Introduction
Creating an hierarchical table in SQL Server is easy. But when it comes to using the data in SQL queries, it is clear that SQL offers limited support. The issue solved in this article is how to use hierarchical tables in easy to understand SQL statements. I present a C# CLR function that transforms the hierarchical table from an item-parent structure to an item-child structure.
The solution is suitable to answer many questions involved in using an hierarchical table. For example to see if a user that is member of an organization is also in another organization, assuming organization is the hierarchical table. The main reason that led me to this solution is reporting, where I want to know the members of an organization and its sub-organizations.
Background
As an example I have defined a table named Organization. Organization has an Id and a ParentId column, and a Name column to store some irrelevant sample data.
Assuming we have this hierarchy:
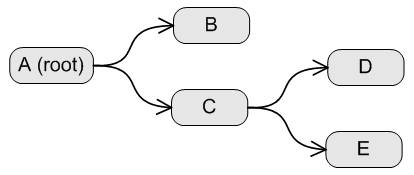
The table is then filled with these records:
| Id | ParentId | Name |
| 00000000-0000-0000-0000-00000000000e | 00000000-0000-0000-0000-00000000000c | E |
| 00000000-0000-0000-0000-00000000000d | 00000000-0000-0000-0000-00000000000c | D |
| 00000000-0000-0000-0000-00000000000c | 00000000-0000-0000-0000-00000000000a | C |
| 00000000-0000-0000-0000-00000000000a | NULL | A |
| 00000000-0000-0000-0000-00000000000b | 00000000-0000-0000-0000-00000000000a | B |
Note that I use home-made uniqueidentifiers such as '00000000-0000-0000-0000-00000000000a' for readability. In the real world you should always use uniqueidentifiers that are generated from your programming language.
The desired output is:

The resulting records will be:
| Id | ChildId |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000a |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000b |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000c |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000d |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000e |
| 00000000-0000-0000-0000-00000000000b | 00000000-0000-0000-0000-00000000000b |
| 00000000-0000-0000-0000-00000000000c | 00000000-0000-0000-0000-00000000000c |
| 00000000-0000-0000-0000-00000000000c | 00000000-0000-0000-0000-00000000000d |
| 00000000-0000-0000-0000-00000000000c | 00000000-0000-0000-0000-00000000000e |
| 00000000-0000-0000-0000-00000000000d | 00000000-0000-0000-0000-00000000000d |
| 00000000-0000-0000-0000-00000000000e | 00000000-0000-0000-0000-00000000000e |
What actually happens is the transformation of the item-parent relation into an item-child relation.
Using the code
The tranformation is performed by a function named TreeToTable, for example:
SELECT * FROM TreeToTable('Organization', 'Id', 'ParentId', NULL)
Parameters are:
TableName | the name of the hierarchical table. |
IdColumn | the name of the id-column. |
ParentIdColumn | the name of the parent-id-column. |
RootId | the Id that is used as the root in case you want to view the tree from a certain point, if you supply NULL the record with parent-id NULL is used, which is typically the root in an hierarchy, but this is not the Id of the root-record itself ! |
As it may be useful to see only records at a certain level, for example if you only want to get all organizations at the root level and don't want the organizations from all sub-organizations. I added a Dept column to the output. I also added a ChildDepth column to the output. So, the real output looks like:
| Id | ChildId | Depth | ChildDepth |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000a | 0 | 0 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000b | 0 | 1 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000c | 0 | 1 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000d | 0 | 2 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000e | 0 | 2 |
| 00000000-0000-0000-0000-00000000000b | 00000000-0000-0000-0000-00000000000b | 1 | 1 |
| 00000000-0000-0000-0000-00000000000c | 00000000-0000-0000-0000-00000000000c | 1 | 1 |
| 00000000-0000-0000-0000-00000000000c | 00000000-0000-0000-0000-00000000000d | 1 | 2 |
| 00000000-0000-0000-0000-00000000000c | 00000000-0000-0000-0000-00000000000e | 1 | 2 |
| 00000000-0000-0000-0000-00000000000d | 00000000-0000-0000-0000-00000000000d | 2 | 2 |
| 00000000-0000-0000-0000-00000000000e | 00000000-0000-0000-0000-00000000000e | 2 | 2 |
If now you want to get only the Organizations at or under the root level, your query could look like:
SELECT * FROM TreeToTable('Organization', 'Id', 'ParentId', NULL)
WHERE Depth = 0
The output will be:
| Id | ChildId | Depth | ChildDepth |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000a | 0 | 0 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000b | 0 | 1 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000c | 0 | 1 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000d | 0 | 2 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000e | 0 | 2 |
If you want to ommit the organization itself from the results and you want the root organization only, your query could look like:
SELECT * FROM TreeToTable('Organization', 'Id', 'ParentId', NULL)
WHERE Depth = 0 AND Depth != ChildDepth
The output will be:
| Id | ChildId | Depth | ChildDepth |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000b | 0 | 1 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000c | 0 | 1 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000d | 0 | 2 |
| 00000000-0000-0000-0000-00000000000a | 00000000-0000-0000-0000-00000000000e | 0 | 2 |
If you want to get the name of the organization back in, your query could look like:
SELECT ORG.*, Organization.Name
FROM TreeToTable('Organization', 'Id', 'ParentId', NULL) ORG
INNER JOIN Organization ON Organization.Id = ORG.Id
Now you might want to join with other tables in order to retrieve usefull data. A typical join looks like this, assuming you have a table named Person that has a referencing column to the Organization table called OrganizationId (note that this code wont work as there is no Person table in the sample database):
SELECT *
FROM TreeToTable('Organization', 'Id', 'ParentId', '', NULL) ORG
INNER JOIN Person ON Person.OrganizationId = ORG.Id
This output now contains all Persons that appear in each organization that it is a member of, including any child organization. This output can be used in a report that does the grouping.
The sample code contains the C# CLR function and a small application that can generate sample data. A ready to use SQL Server Express database is included, though TreeToTable() will work on any version of SQL Server 2005. It is suggested to place the solution at C:\.
Explaining the code
There is too much code to explain it completely. I hope my comments will help you out when it comes to details. General information about programming C# in SQL Server is widely available, you might want to try CLR User-Defined Functions.
You also might want to read Writing Database Objects in CLR for more information on how to use Visual Studio for writing and deploying your C# SQL functions.
The TreeToTable function is declared as:
[SqlFunction(DataAccess = DataAccessKind.Read,
FillRowMethodName = "TreeToTableFillRow",
TableDefinition =
"Id uniqueidentifier, ChildId uniqueidentifier, Depth int, ChildDepth int")
]
public static IEnumerable TreeToTable
(string tableName,
string idColumnName,
string parentIdColumnName,
SqlGuid rootId)
{
}
The FillRowMethodName="TreeToTableFillRow" in the attribute is required and maps to this method:
public static void TreeToTableFillRow(Object obj, out SqlGuid id,
out SqlGuid childId, out int depth, out int childDepth)
{
}
The TreeToTableFillRow(...) method is called for each object that is returned by the enumerator from TreeToTable(...). This is basically how a CLR Table-Valued Function works, covered in many articles and I am not going to explain that here.
So here is a brief description on my implementation of TreetoTable(...):
At first a connection in the context of the current process is made:
SqlConnection cn = new SqlConnection("Context Connection=true");
Next a SQL select statement is built:
string sql = string.Format("SELECT {0}, {1} FROM {2} ", idColumnName,
parentIdColumnName, tableName);
This evaluates, for example, to: SELECT Id, ParentId FROM Organization
Then a SqlDataReader is opened. The SqlDataReader reads all records and creates a Node object for each record. In the nodeobject, the value of Id and ParentId are stored. This node object is stored in a Dictionary that I call source. Also the root is now determined, just because no additional loop is required to find the root.
using (SqlDataReader rdr = cmd.ExecuteReader())
{
while (rdr.Read())
{
SqlGuid id = rdr.GetSqlGuid(0);
SqlGuid parentId = rdr.GetSqlGuid(1);
Node node = new Node(id, parentId);
source.Add(id, node);
if (id == rootId || rootId.IsNull && parentId.IsNull)
{
root = node;
}
}
rdr.Close();
}
It is stored in a Dictionary by id because we need to do a lot of searching on id while buiding the hierarchy of nodes:
foreach (Node node in source.Values)
{
Node parent;
if (source.TryGetValue(node.ParentId, out parent))
{
parent.Add(node);
}
}
Next, the Depth of the nodes is determined, starting at the root by calling the recursive method CalculateDepth(...). This method just sets the Depth property of each child node to 1 more than its parent.
root.CalculateDepth(0);
Now we have an hierarchy of nodes, that only needs to be "flattened" before we can return the result:
RowList result = new RowList();
root.Flatten(result, root.Id, root.Depth, maxDepth);
foreach (Node node in root.SubNodeList())
{
node.Flatten(result, node.Id, node.Depth, maxDepth);
}
The flattenening is a method on the node object. It appends a Row object for itself and all its children to the result object, which is just a List of type Row:
public void Flatten(RowList result, SqlGuid id, int depth, int maxDepth)
{
if (depth > maxDepth)
{
return;
}
Row row = new Row(id, this.Id, depth, this.Depth);
result.Add(row);
foreach (Node node in this.SubNodeList())
{
Row row2 = new Row(id, node.Id, depth, node.Depth);
result.Add(row2);
}
}
That is all there is, result is now the complete list of id's, parentId's, depth's and childDepth's. This list is sent to T-SQL by the TreeToTableFillRow(...) method, which is handled by SqlServer.
Performance
The TreeToTable function performs pretty fast in my opinion. It processes 20.000 records per second, which results in almost 130.000 rows output, tested on my AMD Sempron 2800 notebook. Processing time is lineair to the number of records input, which surprised me a bit because there is a lot recursion and searching going on.
The function may be fast, you should take care when using it. Sql Server can not apply any query optimiziations as it can on T-SQL, neither can the results be cached.
Performance can be increased by adding a SQL where clause parameter so that it does not have to process so many input records. Performance can also get better by adding a maximum-depth parameter, so that it does not output so many rows that you probably dont use. I tried both these options and they make it quicker indeed in specific scenarios. As I think a low number of parameters makes the function easier to use, I left it out of the code that is available for download. With SQL expressions you can achieve the same results and the queries are much easier to read.
To put uniqueidentifiers versus int's to the test, I created an int version as well. Surprise-surprise the int version runs faster. See the graph below.
Creating test data
To create test data I have a small Windows application included in the download.
Points of interest
There are other ways to achieve the same result. Stored procedures with cursors can produce anything you want, though I find them hard to write and they mostly turn out to solve a very specific issue. The very popular Custom Table Expressions of SQL Server 2005 promise to be very fast and easy to use, though I did not manage to return the same results, and I wonder if they will be just as quick. I am interested in alternatives, so please send them in.
History
This first release is submitted on august 12 2006.

