Introduction
This is a simple class which enables multiple processes to share the same block of memory. The difference with this class is that the memory can grow/shrink, enabling you to share any amount of data.
Background
A common problem when creating a new program is managing memory. The problem worsens when creating multithreaded applications where the use of Critical Sections, mutexes, and/or semaphores is required. But when it comes to multiple processes, there is no simple way of sharing data. When I started this class, I found and read many tutorials about inter-process communication. While they were well-written, none of them addressed my problem. Each article I read, showed how to share a string between processes. Not one showed how to share multiple strings, multiple data types, or even variable sized data. This was what I wanted.
Rather than waste time trying to find examples, I decided to create my own method. This class addresses my two concerns, multiple strings and variable sized data.
How it works
Sharing memory between processes is the simple part. The CreateFileMapping() function does most of the work for us. It can create a file either on the hard drive, or a temporary file in the systems page file. When two or more process want to share memory, all they need to do is call this function with the same filename. But there are limitations. First, the file cannot be resized without closing it first, and second, there is no convenient method to write multiple items to the file.
The first problem can be addressed by using a physical file on the disk. By doing this, you can specify a size, the file will grow to the required size when it's opened. The drawback here is that the application must handle the file creation and deletion; also, there is a security risk of having private data stored where anybody can read it. When using a physical file, it is also possible to use the DeviceIoControl() function to enable a file to become growable, though this will only work on NTFS5 partitions, leaving Win95/98 users out of the loop.
Multiple items
In essence, all a memory mapped file is, is a large byte array. To write data, all we need to do is call the basic memory functions memset(), memcpy(), and memmove(). We can also write to the array as with any other array by getting the pointer/position of an element and changing it. So to write multiple items, all we need do is write, increase the pointer, and write again. But what about the second process? How does that know where you wrote the data, the size of the data, and for that matter, if you wrote the data.
The first problem is simple, we write the data in sequence. All the reader needs to do is parse the byte array until it finds the data it's looking for. The second problem can be solved by writing the size of the data alongside the data. The third requires work on the user's part. For each item added to the stream, a unique ID is required. I thought, if a process wants to read shared memory, then obviously it must know something about what it wants to read. In my case, I wanted to read strings that may or may not be there. So, for each item I wanted to add, I had a #define statement containing a unique ID. If I wanted to add items of the same type, I just looped through using the #define as a base number, adding the counter to it.
#define SMTP_BODY 0
#define SMTP_SUBJECT 1
...
#define SMTP_SENDERNAME 9
...
#define SMTP_RECIPIENT 20
#define SMTP_CCRECIPIENT 30
...
#define SMTP_ATTACHEDNAME 200
#define SMTP_ATTACHEDFILE 300
#define SMTP_ATTACHEDTYPE 400
As you can see, for any item where there may be more than one instance, for example, SMTP_ATTACHEDNAME, I can simply use a loop, adding i to the value of SMTP_ATTACHEDNAME to create my unique ID.
So now, for each item written to the stream, a further two items are stored. This actually works to our advantage. When reading the stream, all we need to do is read the ID, read the size, and jump to the next ID. Also, we don't need to store anything in a particular order. The class allocates an extra 8 bytes for each item added: 4 for the ID and 4 for the size. This may seem to be a waste, but it enables us more room for the ID, and allows for larger sized items to be added.
BOOL CMemMap::AddString(LPCTSTR szString, UINT uId)
{
if ( uId == 0xFFFFFFFF || uId == 0xFFFFFF00 )
return FALSE;
LPBYTE lpBytePos = 0;
UINT uPage = 0;
if ( FindID(uId,&uPage,&lpBytePos) == TRUE )
return FALSE;
UINT uStrlen = (_tcslen(szString) + 1 ) * sizeof(TCHAR);
Write(&uPage, &lpBytePos, 4, &uId);
Write(&uPage, &lpBytePos, 4, &uStrlen);
Write(&uPage, &lpBytePos, uStrlen, (LPVOID)szString);
Write(&uPage, &lpBytePos, 4, DOUBLE_NULL);
return TRUE;
}
Just like any string, a special marker 0xFFFFFF00 is used to mark the end of the array. All free space is marked as unallocated with 0xFFFFFFFF. All the IDs and sizes entered will be in the form of an unsigned int, so choosing a marker from the higher range will prevent conflicts, though it does prevent those two hex values being used as an ID.
Dynamic sizing
As mentioned above, there are several steps involved when resizing a file, and security considerations to think about. When using the systems pagefile, the data is only temporary. This means that when closing the handle to the file, the data would be lost. I decided to approach this from another angle, taking the pagefile itself as the basis of my ideas. Instead of creating a single file, we create a book of several files or pages.
There are advantages and disadvantages to this. We are no longer dealing with a simple byte array, but several byte arrays. A page can be added at any time, but there is no guarantee that they will be sequential. The reader also needs to know if a page has been added and exactly how many pages there are at any given time. So, the first four bytes of the first page serves as a page count. Any time a reader/writer wants to perform an action, it can quickly adjust its internal page arrays by looking at this value.
Because of this, the first page must always exist while the class is in scope. Also, each page must be exactly the same size. The next problem comes when reading and writing data. If we create a page of 56 K and add a bitmap image of 238 K, it's not going to fit. The answer is to span the page. Reading and writing requires a little more work, but the data can still remain sequential.
This sequence of items is what holds the whole structure together. So, any time an item is removed, we can't just wipe the used space and leave a void, or the reader will have trouble jumping the IDs. We instead have to move all the following items down to fill the void. Instead of doing this item by item, which would be slow, we do it memory by memory.
while ( 1 ) {
memmove(lpDestPos,lpBytePos,uRemaining);
if ( uPage < m_uPageCount-1 ) {
uPage += 1;
lpBytePos = (LPBYTE)m_pMappedViews[uPage];
lpDestPos += uRemaining;
}
else {
break;
}
memmove(lpDestPos,lpBytePos,uSize);
lpBytePos += uSize;
lpDestPos = (LPBYTE)m_pMappedViews[uPage];
}
Dealing with strings also helps improve the performance. Remember, all we are really dealing with is a byte array, and all strings are null terminated. So to read a string from the file, all we need do is find the start. This pointer can be used in any string function since the byte array will also store the null value. The only time we can't is when the string spans a page. In this instance, we need to copy each half to a single buffer.
LPCTSTR CMemMap::GetString(UINT uId)
{
if ( uId == 0xFFFFFFFF || uId == 0xFFFFFF00 )
return NULL;
LPTSTR lpString = NULL;
LPBYTE lpBytePos = 0;
UINT uPage = 0;
if ( FindID(uId,&uPage,&lpBytePos) == FALSE )
return NULL;
UINT uLen = 0;
Read(&uPage,&lpBytePos,4,NULL);
Read(&uPage,&lpBytePos,4,&uLen);
UINT uRemaining = ((UINT)m_pMappedViews[uPage] +
MMF_PAGESIZE) - (UINT)lpBytePos;
if ( uLen > uRemaining ) {
if ( m_lpReturnBuffer )
delete [] m_lpReturnBuffer;
m_lpReturnBuffer = new BYTE [uLen];
return (LPTSTR)Read(&uPage,&lpBytePos,uLen,m_lpReturnBuffer);
}
else
return (LPTSTR)Read(&uPage,&lpBytePos,uLen,NULL);
}
Reading and writing binary data to file works on a similar method, except that when reading the data, it must first be copied to a buffer. The class provides two methods for this: either it writes to a user entered buffer, or writes to an internal buffer and returns a pointer. This, in turn, can be type cast to your data type.
Reading and writing locks
I cannot take credit for the mutual exclusion code, it instead comes from another article I found while doing my research. The code was written by Alex Farber, and the article can be found here[^]. In my application, I was reading several items at the same time from several processes. Using a mutex for each call was undesirable and slow, Alex Farber's class enables multiple read processes to read the data, but only a single process to write. It served my needs perfectly. I have left it in the code for convenience, though you may like to use your own methods.
Using the code
#define MMF_PAGESIZE 4096
The size in bytes of each page. Use this #define if you wish to change the default page size from 4K to your own. Add the statement to your code before including the header file, otherwise the default value will be used. If you are adding large items to the file, I advice you set this to a higher value as it will decrease the amount of spanned pages and increase the performance.
DWORD Create(LPCTSTR szMappedName, DWORD dwWaitTime, ULONG ulMappedSize);
This function should be called prior to any reading or writing operation. A unique name for the shared memory must be passed into szMappedName, this name must be the same for all processes wanting to share the memory. dwWaitTime is the timeout in milliseconds for the mutex, this parameter may be INFINITE. ulMappedSize is the initial size in bytes of the shared memory. The value will be rounded up to the MMF_PAGESIZE boundary. If this value is less than MMF_PAGESIZE, the value of MMF_PAGESIZE is used in its place.
If the shared memory has already been created, the memory size will be that of the already created file. The function returns ERROR_SUCCESS if it successfully created a file, or ERROR_ALREADY_EXISTS if the file was created by another process. On failure, it returns the value from GetLastError().
BOOL Close();
Closes all open handles to the mapped files. The destructor will call this, by default.
VOID Vacuum();
When several items are deleted, the open handles remain open. Thus, the shared file size remains the same. Calling this function will close all unused pages, freeing the memory that was used to manage them.
BOOL AddString(LPCTSTR szString, UINT uId);
Adds a string to the file. The uId parameter must be a unique value. If the ID already exists or the function fails, it will return FALSE.
BOOL UpdateString(LPCTSTR szString, UINT uId);
Replaces the stored item with the same uId. If the ID does not exist, it adds a new item and returns TRUE. If the function fails, it returns FALSE.
UINT GetString(LPCTSTR szString, UINT uLen, UINT uId);
Reads uLen bytes into szString. If the szString parameter is NULL, it returns the string length in bytes including the null terminator. szString must be an allocated buffer large enough to hold uLen bytes.
UINT GetStringLength(UINT uId);
Returns the string length of uId in bytes including the null terminator.
LPCTSTR GetString(UINT uId);
Returns a pointer to a null terminated string. It is recommended you copy this string to your own allocated buffer, as the internal structure of the file is likely to change, causing the pointer to become invalid.
BOOL AddBinary(LPVOID lpBin, UINT uSize, UINT uId);
Adds binary data (int, long, struct... ) to the file. Specify the size of the data type in the uSize parameter. If the function fails, it returns FALSE.
BOOL UpdateBinary(LPVOID lpBin, UINT uSize, UINT uId);
Adds or replaces the data stored at uId.
UINT GetBinary(LPVOID lpBin, UINT uSize, UINT uId);
Reads the uSize of the binary data into lpBin. If the lpBin parameter is NULL, the function returns the size of the data. If the uSize parameter is larger than that of the stored data, the size of the stored data is used instead.
UINT GetBinarySize(UINT uId);
Returns the size in bytes of the binary data.
LPVOID GetBinary(UINT uId);
Returns a pointer to the binary data. It's recommended that you copy the data because the internal structure of the file is likely to change, causing the pointer to become invalid.
BOOL DeleteID(UINT uId);
Removes the specified uId from the file. Internal memory is not unallocated. To free any used memory, you must call Vacuum().
UINT Count();
Returns the number of items currently being stored. This function serves little purpose, and is here mainly for debugging reasons.
UINT64 UsedSize();
Returns the actual used bytes of the internal files. This function serves little purpose, and is here mainly for debugging reasons.
BOOL WaitToRead();
Attempts to gain Read access to the shared file. Reading may be shared among other processes. When finished reading, you must call Done(), or you will lock out any process trying to write.
BOOL WaitToWrite();
Attempts to gain write access to the file. Write access has priority over any and all readers, and only one process may write to the file at the same time. When finished writing, you must call Done().
BOOL Done();
You must call this after WaitToRead() and WaitToWrite() and after having completed any reading or writing you may have done. This will release the lock, enabling another process to write.
I apologise for not providing a demo app, I just cannot think of a suitable demonstration as to what this class can do. If you have any ideas, please let me know, or if you would like to create a demo, I would be happy to include it in the article.
The class is pretty straightforward to use as shown in the example below. Before calling any functions, you must call the Create() method. Most errors are returned by the functions, but in rare cases, an exception may be thrown, so it's good practice to wrap the code in try...catch blocks. If you decide to use the internal locking mechanism, be sure to call Done() to release the lock for another process. Failing to do this will not prevent other processes from reading, but it will prevent others from writing.
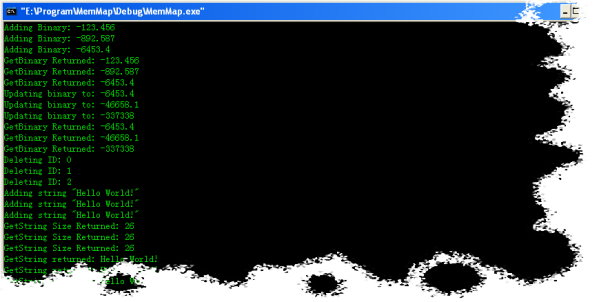
int main()
{
CMemMap mmp;
unsigned int i;
double j = -123.456;
try
{
mmp.Create(_T("594855C7-9888-465a-8BC8-D9797874EB9F"),INFINITE,2048);
if ( mmp.WaitToWrite() ) {
for (i=0; i<3; i++,j*=7.23) {
wcout << _T("Adding Binary: ") << j << endl;
mmp.AddBinary(&j,sizeof(double),i);
}
for (i=0,j=0; i<3; i++) {
mmp.GetBinary(&j,sizeof(double),i);
wcout << _T("GetBinary Returned: ") << j << endl;
}
for (i=0; i<3; i++,j*=7.23) {
wcout << _T("Updating binary to: ") << j << endl;
mmp.UpdateBinary(&j,sizeof(double),i);
}
for (i=0,j=0; i<3; i++) {
mmp.GetBinary(&j,sizeof(double),i);
wcout << _T("GetBinary Returned: ") << j << endl;
}
for (i=0; i<3; i++) {
wcout << _T("Deleting ID: ") << i << endl;
mmp.DeleteID(i);
}
for (i=0; i<3; i++) {
wcout << _T("Adding string \"Hello World!\"") << endl;
mmp.AddString(_T("Hello World!"),i);
}
for (i=0; i<3; i++) {
wcout << _T("GetString Size Returned: ");
wcout << (UINT)mmp.GetString(0,0,i) << endl;
}
for (i=0; i<3; i++) {
wcout << _T("GetString returned: ");
wcout << (LPCTSTR)mmp.GetString(i) << endl;
}
for (i=0; i<3; i++) {
wcout << _T("Deleting ID: ") << i << endl;
mmp.DeleteID(i);
}
wcout << _T("Freeing the memory") << endl;
mmp.Vacuum();
wcout << _T("Releasing lock") << endl;
mmp.Done();
}
}
catch (LPCTSTR sz)
{
wcout << sz << endl;
}
char c(' ');
while (c != 'q' && c != 'Q')
{
cout << "Press q then enter to quit: ";
cin >> c;
}
return 0;
}
My latest project called for multiple processes to read/write/store many strings. Some of these strings were up to 10 MB in size (base64 encoded files). When I started the project, the first thing I did was to create a class which handled these strings. At that time, all the data was stored within the class. When the question of multiple processes came to mind, I realised that I couldn't store strings in this manner. So after creating this class, I no longer needed to. Instead of calling new to allocate a buffer and then copying the string into it, I could instead store the strings directly into the shared file. Any time a class member wanted to use the string, I simply used the pointer returned by GetString().
TODO list
- Create a demo application.
- All processes reading and writing must use the same string format. If an ANSI build writes a string, it will be stored as ANSI, but if a UNICODE build tries to read the same string, there will be problems.
- Possibly implement a method of enumerating all stored items.
History
- September 10th (Teachers' day) - Version 1.0 released.

