Introduction
This project has been a combined development effort between the Visual Studio C# Express Edition compiler and the SharpDevelop 1.x - 2.0 compilers. The reason for this is that both of them have their faults and personally I can't say I'm comfortable using either of them for any length of time, as both of them irritate me in different ways. That is just a personal issue, however, and from a technical point of view the GUI development in Visual C# is excellent in comparison to SharpDevelop. Also, although the debugger is slower in SharpDevelop, it does allow you to debug threads properly, which can't be said for the Visual C# debugger. At the end of the day, SharpDevelop is still being worked on so it can be improved in time whereas any new versions of Visual C# will probably just concentrate on whatever new web technology Microsoft is trying to push next year.
From a developer of 11 years' perspective it is a depressing state of affairs to find that in an attempt to get easier and faster, the development tools themselves have taken a huge step backwards. Once again it is advisable to check to see if bugs show up in two compilers because you can longer trust what the tools are telling you. So to all those relatively new to programming: Welcome to programming early 90's style.
Anyway, enough griping and on with the project. For those new to Genetic Algorithms, this is a really bad place to start. Read this first: Genetics Dot Net - The Basics, as none of the things in that article will be repeated here. As stated in the conclusion of the last project, this time we are going to be looking at adaptive programming. First though, I should probably clarify what that means.
Adaptive programming
On page 2 of his book "Genetic Algorithms in Search, Optimisation and Machine Learning," David E. Goldberg says,
"The implications of robustness for artificial systems are manifold. If artificial systems can be made more robust, costly redesigns can be reduced or eliminated. If higher levels of adaptation can be achieved, existing systems can perform their functions longer and better. Designers of artificial systems-both software and hardware, whether engineering systems, computer systems, or business systems-can only marvel at the robustness, the efficiency, and the flexibility of biological systems. Features for self-repair, self guidance, and reproduction are the rule in biological systems, whereas they barely exist in the most sophisticated artificial systems."
Simple. Then all we need to do from a programming point of view is develop a system whereby the code can, within limits, change and adapt to changes both in its environment and in its primary task. Code-wise, of course, we must be able to handle changes that are thrown at the code on a practically physical level -- i.e. running out of any kind of resource is not an option -- while still retaining the goal-driven nature of the program. That is, we cannot allow the required flexibility of the code to become so far-reaching that it makes it difficult for us to achieve the goal of the program in the first place.
First of all, though, I should probably explain a bit about the program itself so that people can understand what is going on when it is run.
The program
The design of the program (pictured at the top of the page) is that of a fairly simple algorithm finding its way through a maze. I chose this because it is an idea that people can easily follow, as well as being something which provides plenty of visual clues as to what is happening. In this way, even people who don't necessarily understand how the algorithms work can see what it is that they are trying to achieve.
The GUI itself is split into three parts, the map section that shows a visual representation of what is going on. Note, though, that this is not meant to be a complete representation. We are using standard windows graphics here and we quite simply could not display everything that was happening, unless we used Directx. This would also be pretty pointless, however, because even if you could see everything that was happening, you still wouldn't be able to process the information. This is because there is too much going on and any graphics would most likely just be a blur of colour. The solution to this was to select one genetics string from each run to display. This allows me to give a visual representation without overloading the Windows graphics system -- at least on my system, anyway. I have no idea how the program runs on anything less that a 64 bit 4ghz AMD, though no doubt people will mention it if it's bad.
The second part of the GUI is the text box which reports the progress of the code as it goes. The final part is the options tabs, which are used to start and stop each example and to set up the basic parameters for the Genetics Algorithims.
The maps
The maps come in two types: the simple maps,

which are used primarily in the opening stages of development, and the normal or standard maps,
As you can see, each map is required to have a Start and a Finish. After that, they can be as simple or as complex as you want. Bear in mind that the greater the complexity of the map, the longer it will take for the algorithms to do their work. So, although the simple maps can take a few seconds to complete, Map Three can take ages.
The maps are loaded from the Map Options Tab:
Simply select the map you wish to load and then hit the load map button. This button is disabled whenever you start an algorithm so that you can't change the map in the middle of a run. It is re-enabled as soon as an algorithm is stopped.
The maps themselves are a simple XML structure for each square:
As you can see, each square contains the square identifier and a value for if the square represents the start or the finish of the map. It is recommended that there only be one start and one finish per map; there is nothing in the code to deal with more than one of each. In the tradition of programming manuals through the ages, we'll just say that having more than one start or more than one finish square will cause undefined behaviour. There is a file called MapTemplate.xml distributed with the project. It has all settings set to false, so it is a clean sheet if you want to create your own map. Alternatively, you could just modify one of the existing maps.
The graphical interface
The board itself is a single window that is split into squares, with each square taking control of it's own section of the window. They are, in effect, seperate window controls in how they behave although they don't have the overhead of being seperate controls. Rather, they act as drawing regions within the board control itself. This is shown in the GeneticsBoard.cs file, where in the InitialiseBoard function we have the code:
GetHashTable.Add( "A8", new GeneticsSquare( SquareWidth,
SquareHeight, 0, 0, "A8" ) );
GetHashTable.Add( "A7", new GeneticsSquare( SquareWidth,
SquareHeight, 0, SquareHeight, "A7" ) );
GetHashTable.Add( "A6", new GeneticsSquare( SquareWidth,
SquareHeight, 0, SquareHeight * 2, "A6" ) );
GetHashTable.Add( "A5", new GeneticsSquare( SquareWidth,
SquareHeight, 0, SquareHeight * 3, "A5" ) );
As you can see, each square is added to the hash table contained within the board class where, in theory, the name/location of the square is used as the key to access it. However, in practice, we rarely deal with things from within the code in such a controlled way that we know exactly where we are all the time. In practice then, the hash table tends to get used as a standard array. This is because of the way in which the Genetics Algorithm decides where it is going to go. It doesn't decide according to the board positions of squares, but rather it will generate a list of directions such as left, down, right, left, up left, and see where they lead on the board. This, in turn, is why anyone can design a map for the project. The algorithm doesn't care about where it starts on the board or where the valid paths through the board are; this is all decided in the implementation code within the form itself.
As you can see, the map is made up of gold lines on a green background, with three wires or strings being used to represent what is going on. The working wire is the brown and white wire:
This is called the Current Attempt string and is used by all three algorithms to show how it is progressing. This is, as stated above, only displaying one part of the set of Genetics Strings for the whole run. The second wire is the green and yellow string:
This is the Current Solution string and it is used to represent either the completed solution or, where no completed solution is available, the best available solution at the moment. This is not strictly accurate, as it works according to which string has gone furthest without running into a wall. This means, in effect, that a string that goes left, right, left, right, left, right, right, left, left, will read has having travelled further than a string that reads left, left, left. The final wire is the red and blue string:
This is the Previous Solution string. It is only used for a complete and valid path to the finish. As you will see later, there is one occasion where a Current Solution wire can think it has reached the end, but the path is not valid.
The output section
The output box is used to display what is happening within the program at any given time, with the idea that it can be used to see what is going on in the code. In practice, this tends not to work quite that way. This is because there is so much going on that even a short run of the first example code produces a document when the Save Output option is used corresponding to around 250 pages of A4 paper. This is before you start playing around with options in the code. In reality, it tends to function more as an indicator of whether everything is working or not. This is because, when the box has the focus, things will be seen to be happening. If nothing is being written to the box for any length of time, it is a fair bet that something has gone horribly wrong.
At the top of the Form1.cs file there is a section,
private bool bPrintCurrentAttemptFinds = false;
private bool bPrintTimerMessage = false;
private bool bPrintRunMessages = true;
private bool bPrintGenerationMessages = true;
private bool bPrintSampleDebugString = true;
private bool bPrintFullBestString = true;
private bool bDebugProgress = false;
private bool bDebugSetValid = false;
There is a similar, although smaller, section in the GeneticsPath.cs file. This will also allow the output to follow the progress of the algorithms right through the run function. Turning all of these options on will cause a major performance hit and will generate an information file thousands of pages long when the output is saved.
The options section
There are five option tabs at the bottom of the page. We have already seen one of these: the Map Options tab above. The first options tab is the Genetics Options tab:
The Generations box controls the number of generations, as well as the number of cycles or runs per generation. If these mean nothing to you, I refer you to the article mentioned above. The Delay box is used at the start of the loops that control each example. The idea here is that you can stop the execution of the program for a second or so and thus give the drawing functions some processor time to do their job.
The final three tabs are the example tabs, which are used for controlling each example. The only settings that can be changed on these tabs are the starting string size and the size of the population. Once again, these are described fully in the previous article, although it has to be said that there is no real need to change any of the settings for the algorithms at all.
The examples
That concludes our tour of how the program works. Now we can get down to the meat of what's going on in this project by looking directly at the examples and how they work. It should be noted that while Example Three is obviously the most interesting of the examples, it is a good idea to follow the examples through in order, as Examples Two and Three are the logical progressions from the ideas used in Example One.
The problem with concepts
While this program was in development, I showed it to a friend who isn't a programmer just to show him what I was up to. The reason I mention this is because he thought the code was being stupid because it was running into dead ends repeatedly. So I had to explain that the way the program works is that it has no concept of the fact that it is to all outward appearances running through a maze. It is simply generating a random number of options which, in this case, happen to be one of four directions. To the code that finds its way through the maze, it doesn't make any difference which map it is trying to find its way through. In fact, it is perfectly possible that it could generate exactly the same directions through every single map that it is run against at some point, the Validation function being the only one that determines the accuracy of these directions. This is an important point to remember when thinking about the way that Genetic Algorithms work, because when it comes to the actual generation of the options -- or, to be more precise, the genetic data itself -- a Genetic Algorithm is simply concerned with the almost random selection of the options given to it. That is, unless it has been programmed with more specific environmental information from the start, such as in an engineering project where it would not make sense for "A" to follow "B." So, the algorithm is designed from the ground up to discount this possibility.
The Expanding Genetics Array Algorithm (Example One)
Definition
The definition for Example One is a Genetics Array that expands as is required automatically by the program. If you have run the example code already, you will see that each example requires an initial string size of 20. This is the starting length for the Genetics Algorithm strings. You may note that no upper limit for the size is set from the GUI. This is only settable in the code when the example is initialised with:
gpExampleOne.SetExandingGeneticsArray( 100,
( int )exampleOneStartStringSize.Value, 10 );
This is called to tell the Genetics code that we are using a dynamic algorithm which we will grow later in the code. The definition for the function is:
public void SetExandingGeneticsArray( int maxLength,
int startLength, int incrementLength )
You can see that the maximum length for the arrays is set at 100. The initial string size is set at the setting in the GUI, default 20, and the increment length is set to 10. The maximum length set here is adequate for the size of the maps that we are using and the increment length is a nice round number.
For all intents and purposes, the algorithm works just like any standard Genetics Algorithm. It goes through the run function and may or may not apply a mutation to a certain genetic string. The main difference arises at the end of the run function, where you hit this code segment:
if( IsFixedLength == false && nMaxSize == CurrentLength )
{
This tests that we are not using a standard Genetics Algorithm. If we are not, it tests to see if we have reached the current maximum size. Note that this is not the absolute maximum size; this is the initial string length plus the value of the increment lengths we have made. This is tested against the current length. I should be clear that the current length is a measure of how far the string has successfully manoeuvred through the maze. All Items within a genetics string are used all the time. This is a measure of only the valid moves made starting from the beginning of the string.
The code then loops through the population, adding new GeneticsPathItems to the string. The basic make-up of the code is that each GeneticPath holds an array of GeneticsStrings, one for each population item. Each GeneticsString holds an array of GeneticsPathItems, which are the actual directional information pieces for the route through the maze.
The main loop
Once the initialisation for Example One is complete, we enter the main loop of the example with:
>while( bStop == false ) {
We do some more general control stuff and then call:
SetValidPaths( gpExampleOne );
This call passes the current GeneticsPath object to the SetValidPaths function. This then cycles through every GeneticsString held in the GeneticsPath array and checks the validity of each movement instruction against the currently loaded map. We then do some more checking and debug stuff before we get to:
ExampleOneFitness( gpExampleOne, tExampleOne, bStopThreadOne );
if( bFinishIsSet == true )
{
tsTextBox.AppendTextWithColour( "At generation number "
+ nGenerationCount.ToString() + " run number "
+ nRunCount.ToString() + " the algorythm found the finish.",
Color.Red );
geneticsBoard1.SetCurrentSolution( gpsCurrentAttemptString );
OnGuiTimer( this, new EventArgs() );
bStop = true;
break;
}
The fitness function in this case is simply checking to see if we have a string that has a set of valid squares that reaches to the end of the map without being blocked, which only becomes relevant in Example Three. If we find a string of directions that reaches the end square then the bFinishIsSet value is set to true, which we check for in the next line of code. In Example One we then set the current solution to the current attempt, draw it and then exit the example. The next important line is:
gpExampleOne.Run();
This calls the GeneticsPath Run function, which performs the Genetic Algorithm code on each string. It should be noted that all of the examples here use Single Point Cross Over with Roulette Wheel Selection. If that means nothing to you, read the earlier article. The next line is:
if( nGenerationCount == gpExampleOne.NumberOfGenerations )
{
if( bPrintGenerationMessages == true )
{
tsTextBox.AppendTextWithColour(
"Number Of Generations Reached, Halting Algorythm",
Color.BlueViolet );
}
bStop = true;
break;
}
This simply checks if the number of generations that we have run is equal to the total number of generations that we are supposed to run. If it is, we exit the loop and the algorithm has more than likely failed to find a solution. The final important section of the code is:
if( nRunCount == gpExampleOne.NumberOfCyclesPerGeneration )
{
if( gpsCurrentAttemptString.HasReachedFinish
== true && gpsCurrentAttemptString.LengthTravelled
>= gpsMaxString.LengthTravelled )
{
geneticsBoard1.ResetPreviousSolution();
geneticsBoard1.SetPreviousSolution( gpsMaxString );
gpsPreviousSolutionString = gpsMaxString;
}
if( bPrintGenerationMessages == true )
{
tsTextBox.AppendTextWithColour(
"Number Of Cycles Run For Generation " +
nGenerationCount.ToString()
+ ", Reinitialising Genetics Array", Color.BlueViolet );
}
gpExampleOne.Initialise();
gpExampleOne.SingleCrossOverPoint = gpExampleOne.StartingLength /2;
if( gpExampleOne.SingleCrossOverPoint == 0 )
Debug.WriteLine(
"The Single Point CrossOver has been
screwed up in run after the initialisation" );
nGenerationCount++;
nRunCount = 0;
}
This piece of code checks to see if we have run the number of cycles required to be counted as an entire generation. Again, if this is meaningless to you, I refer you to the earlier article. The first thing we do is check to see if any of the last run reached the finish square. If they did, we reset the previous solution string to the finish and display it. We then re-initialise the GeneticsPath object and reset the single crossover point back to the beginning. This is because it will have moved, as the genetics array expands during the run function. Finally, we increment the generations count and set the new generation's run count to zero.
In action
When the first example is running, it will look mostly like this:
This illustrates the current attempt string, showing the maximum string of its current run as it tries to find the way to the finish. When it does find the finish, it will set the previous solution string and display it like so:
The Improving Options Algorithm (Example Two)
Definition
The definition for Example Two follows logically from Example One in that once we have found the finish for a given map, we are going to start wondering if we can do it better. Example Two will take a solution provided by running the first example code and then run the algorithm again to see if it can find a away through the map that -- for this example -- uses the criterion that it should be shorter than the previously saved solution. The set-up precedure for Example Two is almost identical to Example One, except for the code:
StringBuilder strMapName = new StringBuilder( strMap );
strMapName = strMapName.Replace( ".xml", "ExampleTwo.sav" );
if( File.Exists( strMapName.ToString() ) == true )
{
LoadPreviousSolutionString( strMapName.ToString() );
}
else
{
while( RunInitialSearch( gpExampleTwo,
tExampleTwo, ref bStopThreadTwo ) == false );
SavePreviousSolutionString( strMapName.ToString() );
Settings( gpExampleTwo );
GeneticsPathString.InitialChromosomeLength
= ( int )exampleTwoStartStringSize.Value;
gpExampleTwo.PopulationSize = ( int )exampleTwoPopulationSize.Value;
geneticsBoard1.ResetCurrentAttempt();
geneticsBoard1.ResetCurrentSolution();
gpExampleTwo.Initialise();
Monitor.Enter( tExampleTwo );
bFinishIsSet = false;
Monitor.Exit( tExampleTwo );
}
geneticsBoard1.SetPreviousSolution( gpsPreviousSolutionString );
The difference here is that for Example Two we are trying to improve on a previous run of the algorithm. So first of all, we have to load the algorithm. This is stored as an XML file and can be viewed with any XML viewer. The save files for the project are given the extension .sav so that they don't show up in the options when you want to load a map.
Apart from that, the only noticeable difference is the RunInitialSearch function. This is a rewrite of the initial Example One main loop and is seperated off into its own function. At present, the Example Two algorithm will only make one attempt at running through the algorithm to find a faster way through. This means that if the run is unsuccessful, it will require starting again manually. It wouldn't be too much of a challenge to rewrite this so that the algorithm continues to run until a faster solution is found.
The main loop
The main loop for Example Two is largely the same as the code for Example One. The principal exception is that we now use the previous solution string to display the solution found by the previous run. Upon completion, the current solution string is used to display the currently found best solution. Testing the solutions against each other:
if( gpsCurrentAttemptString.LengthTravelled
<= gpsPreviousSolutionString.LengthTravelled )
{
gpsPreviousSolutionString = gpsCurrentAttemptString;
SavePreviousSolutionString( strMapName.ToString() );
geneticsBoard1.SetCurrentSolution( gpsCurrentAttemptString );
OnGuiTimer( this, new EventArgs() );
bStop = true;
break;
}
This only sets the previous solution string to the current attempt string if it is shorter than that found by the previous run of the algorithm. When we reach the end of a run, we now have the code:
if( bFinishIsSet == false )
{
nMaxSize = 0;
gpsTest = null;
for( int i=0; i<gpExampleTwo.PopulationSize; i++ )
{
gpsTest
= ( GeneticsPathString )gpExampleTwo.GeneticsArray[ i ];
if( gpsTest.LengthTravelled >= nMaxSize )
{
nMaxSize = gpsTest.LengthTravelled;
gpsMaxString = gpsTest;
}
}
gpsCurrentSolutionString = gpsMaxString;
}
This sets the current solution string to the largest string found in the current run.
In action
When Example Two first starts, it will look like this:
This shows both the solution found by a previous run and the current (best) attempt that the algorithm is making to find the finish.
This image shows Example Two displaying the previous solution, its current attempt to find the finish and the best current solution found so far. This is what Example Two looks like when it has successfully found a better solution:
Even though the current solution technically looks longer, there is no code in the current algorithms that prevents the strings from going back over ground they have already covered. So a successful run is a string that reaches the finish in fewer moves, whether it looks like it or not.
The Terminator Algorithm (Example Three)
Definition
The third example -- indeed, this entire project -- is the result of the Terminator films. Specifically, I'm talking about the scene where Arnie the terminator is in the steelworks factory and the newer liquid metal terminator rams a steel rod through his back. There then follows a brief sequence in which we see Arnie reroute his circuitry to find the power source. So be warned: this project is a prime example of what happens when you watch sci-fi films and think, "I wonder how you'd do that." This is one solution.
The difference between the code that sets up Example One and that which sets up Example Two is just in the structuring of the blocking code. That is:
string strSquare = geneticsBoard1.GetStartSquare();
GeneticsSquare gsSearchSquare
= ( GeneticsSquare )geneticsBoard1.GetSquare( strSquare );
GeneticsSquare gsTempSquare = null;
GeneticsPathItem gpiPathItem = null;
foreach( DictionaryEntry dicEnt in geneticsBoard1.GetHashTable )
{
gsTempSquare = ( GeneticsSquare )dicEnt.Value;
if( gsTempSquare.Blocked == true )
{
gsTempSquare.Blocked = false;
gsTempSquare.DrawBlocked = false;
}
}
if( geneticsBoard1.InvokeRequired == true )
{
InvalidateCallback d = new InvalidateCallback( Invalidate );
geneticsBoard1.Invoke( d, new object[]{} );
UpdateCallback f = new UpdateCallback( Update );
geneticsBoard1.Invoke( f, new object[]{} );
}
else
{
geneticsBoard1.Invalidate();
geneticsBoard1.Update();
}
for( int i=0; i<nBlockSquare; i++ )
{
gpiPathItem
= ( GeneticsPathItem )gpsPreviousSolutionString.GeneticsString[ i ];
if( gpiPathItem == null )
{
MessageBox.Show( "Error, trying to get item "
+ i.ToString() +
" from the previous solution string" );
return;
}
switch( gpiPathItem.Direction )
{
case "Up": gsTempSquare =
( GeneticsSquare )geneticsBoard1.GetSquareAbove(
gsSearchSquare.Identifier ); break;
case "Right": gsTempSquare
= ( GeneticsSquare ) geneticsBoard1.GetSquareToRight(
gsSearchSquare.Identifier ); break;
case "Down": gsTempSquare
= ( GeneticsSquare )geneticsBoard1.GetSquareBelow(
gsSearchSquare.Identifier ); break;
case "Left": gsTempSquare
= ( GeneticsSquare )geneticsBoard1.GetSquareToLeft(
gsSearchSquare.Identifier ); break;
}
if( gsTempSquare != null )
{
gsSearchSquare = gsTempSquare;
}
}
gsSearchSquare.Blocked = true;
gsSearchSquare.DrawBlocked = true;
First, we remove any blocks set up in previous runs. Then we redraw the board to clean it before setting up a new block that we will hopefully be able to get around. Due to the fact that there is nothing to stop the strings going backwards and forwards over the same square, it is theoretically possible that -- given the way the maps are designed -- a block will be placed which is simply impossible for the algorithm to work its way around.
The main loop
The main loop for Example Three is almost identical to the main loop in Example Two. The primary difference between the two is in the block that is dealt with in the fitness function. As this simply doesn't apply to the earlier examples, the code for it does not get in the way of their running.
In action
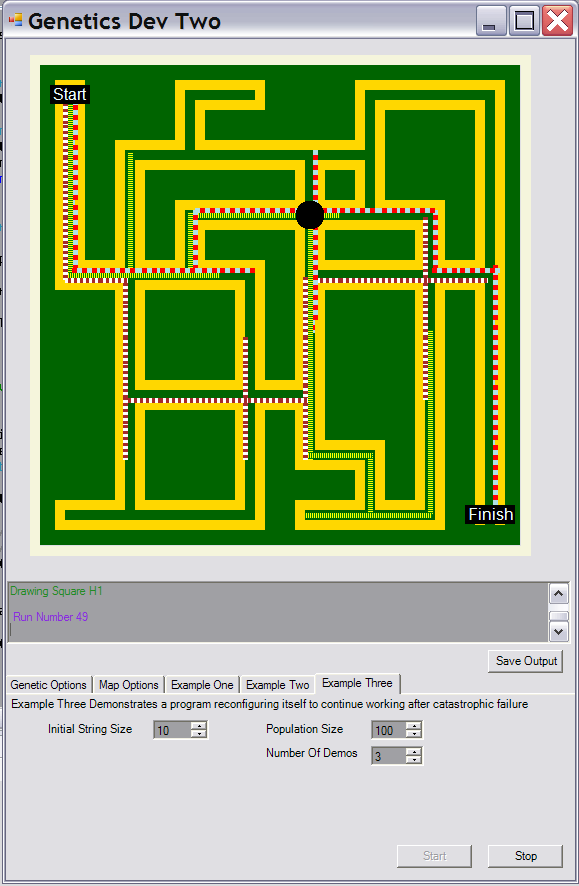
At the start, an Example Three run looks like:
Once it has gotten going and the current solution is also included, it seems like this:
At the end -- yes, it took a couple of runs -- the block is reset at the start of the code run in each example:
Conclusion
That pretty much covers what I'm going to do with Genetic Algorithms for now. I think I'll stick to something simple next time, like how a for loop works.
Primary references
Mat Buckland , ( 2002 ) AI Techniques For Game Programming, Premier Press Game Development Series.
David E. Goldberg, ( 1989 ) Genetic Algorithms In Search Optimization And Machine Learning, Addison Wesley.
Wolfgang Banzhaf et al, ( 1998 ) Genetic Programming An Introduction, Morgan Kaufmann.
Secondary references
Tom Archer ( 2001 ) Inside C#, Microsoft Press
Jeffrey Richter ( 2002 ) Applied Microsoft .NET Framework Programming, Microsoft Press
Charles Peltzold ( 2002 ) Programming Microsoft Windows With C#, Microsoft Press
Robinson et al ( 2001 ) Professional C#, Wrox
William R. Staneck ( 1997 ) Web Publishing Unleashed Professional Reference Edition, Sams.net
Robert Callan, ( 1999 ) The Essence Of Neural Networks, Prentice Hall
Timothy Masters ( 1993 ) Practical Neural Network Recipes In C++, Morgan Kaufmann ( Academic Press )
Melanie Mitchell ( 1999 ) An Introduction To Genetic Algorithms, MIT Press
Joey Rogers ( 1997 ) Object-Orientated Neural Networks in C++, Academic Press
Simon Haykin ( 1999 ) Neural Networks A Comprehensive Foundation, Prentice Hall
Bernd Oestereich ( 2002 ) Developing Software With UML Object-Orientated Analysis And Design In Practice Addison Wesley
R Beale & T Jackson ( 1990 ) Neural Computing An Introduction, Institute Of Physics Publishing
Bart Kosko ( 1994 ) Fuzzy Thinking, Flamingo
Buckley & Eslami ( 2002 ) An Introduction To Fuzzy Logic And Fuzzy Sets, Physica-Verlag
Steven Johnson ( 2001 ) Emergence, The Penguin Press
John H. Holland ( 1998 ) Emergence From Chaos To Order, Oxford University Press
Earl Cox ( 1999 ) The Fuzzy Systems Handbook, AP Professional
Mark Ward ( 1999 ) Virtual Organisms, Pan
Bonabeau, Dorigo, Theraulaz ( 1999 ) Swarm Intelligence From Natural To Artificial Systems, Oxford University Press
Masao Mukaidono, Fuzzy Logic For Beginners ( 2002 ) World Scientific Publishing
Deborah Gordon, Ants At Work ( 1999 ), W W Norton
Gigerenzer, Todd & ABC Research Group ( 1999 ) Simple Heuristics That Make Us Smart, Oxford University Press
Rodney A. Brooks ( 1999 ) Cambrian Intelligence, MIT Press
Winfred F. Hill, ( 1964 ) Learning A Survey Of Psychological Interpretations, University Paperbacks.
M. Tim Jones, ( 2003 ) AI Application Programming, Charles River Media
History
- 16 May, 2007 - Article edited and posted to the main CodeProject.com article base

