Introduction
This article is Part 1 of a series of 3 articles that I am going to post. The proposed article content will be as follows:
- Part 1: This one, will be an introduction into Perceptron networks (single layer neural networks)
- Part 2: Will be about multi layer neural networks, and the back propogation training method to solve a non-linear classification problem such as the logic of an XOR logic gate. This is something that a Perceptron can't do. This is explained further within this article
- Part 3: Will be about how to use a genetic algorithm (GA) to train a multi layer neural network to solve some logic problem
Let's start with some biology
Nerve cells in the brain are called neurons. There is an estimated 1010 to the power(1013) neurons in the human brain. Each neuron can make contact with several thousand other neurons. Neurons are the unit which the brain uses to process information.
So what does a neuron look like
A neuron consists of a cell body, with various extensions from it. Most of these are branches called dendrites. There is one much longer process (possibly also branching) called the axon. The dashed line shows the axon hillock, where transmission of signals starts
The following diagram illustrates this.
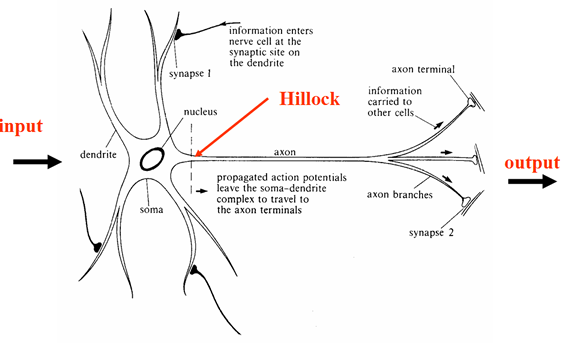
Figure 1 Neuron
The boundary of the neuron is known as the cell membrane. There is a voltage difference (the membrane potential) between the inside and outside of the membrane.
If the input is large enough, an action potential is then generated. The action potential (neuronal spike) then travels down the axon, away from the cell body.

Figure 2 Neuron Spiking
Synapses
The connections between one neuron and another are called synapses. Information always leaves a neuron via its axon (see Figure 1 above), and is then transmitted across a synapse to the receiving neuron.
Neuron Firing
Neurons only fire when input is bigger than some threshold. It should, however, be noted that firing doesn't get bigger as the stimulus increases, its an all or nothing arrangement.
Figure 3 Neuron Firing
Spikes (signals) are important, since other neurons receive them. Neurons communicate with spikes. The information sent is coded by spikes.
The input to a Neuron
Synapses can be excitatory or inhibitory.
Spikes (signals) arriving at an excitatory synapse tend to cause the receiving neuron to fire. Spikes (signals) arriving at an inhibitory synapse tend to inhibit the receiving neuron from firing.
The cell body and synapses essentially compute (by a complicated chemical/electrical process) the difference between the incoming excitatory and inhibitory inputs (spatial and temporal summation).
When this difference is large enough (compared to the neuron's threshold) then the neuron will fire.
Roughly speaking, the faster excitatory spikes arrive at its synapses the faster it will fire (similarly for inhibitory spikes).
So how about artificial neural networks
Suppose that we have a firing rate at each neuron. Also suppose that a neuron connects with m other neurons and so receives m-many inputs "x1 …. … xm", we could imagine this configuration looking something like:
Figure 4 Artificial Neuron configuration
This configuration is actually called a Perceptron. The perceptron (an invention of Rosenblatt [1962]), was one of the earliest neural network models. A perceptron models a neuron by taking a weighted sum of inputs and sending the output 1, if the sum is greater than some adjustable threshold value (otherwise it sends 0 - this is the all or nothing spiking described in the biology, see neuron firing section above) also called an activation function.
The inputs (x1,x2,x3..xm) and connection weights (w1,w2,w3..wm) in Figure 4 are typically real values, both postive (+) and negative (-). If the feature of some xi tends to cause the perceptron to fire, the weight wi will be positive; if the feature xi inhibits the perceptron, the weight wi will be negative.
The perceptron itself, consists of weights, the summation processor, and an activation function, and an adjustable threshold processor (called bias here after).
For convenience the normal practice is to treat the bias, as just another input. The following diagram illustrates the revised configuration.
Figure 5 Artificial Neuron configuration, with bias as additinal input
The bias can be thought of as the propensity (a tendency towards a particular way of behaving) of the perceptron to fire irrespective of its inputs. The perceptron configuration network shown in Figure 5 fires if the weighted sum > 0, or if you're into math-type explanations
Activation Function
The activation usually uses one of the following functions.
Sigmoid Function
The stronger the input, the faster the neuron fires (the higher the firing rates). The sigmoid is also very useful in multi-layer networks, as the sigmoid curve allows for differentation (which is required in Back Propogation training of multi layer networks).
or if your into maths type explanations
Step Function
A basic on/off type function, if 0 > x then 0, else if x >= 0 then 1
or if your into math-type explanations
Learning
A foreword on learning
Before we carry on to talk about perceptron learning lets consider a real world example :
How do you teach a child to recognize a chair? You show him examples, telling him, "This is a chair. That is not a chair," until the child learns the concept of what a chair is. In this stage, the child can look at the examples we have shown him and answer correctly when asked, "Is this object a chair?"
Furthermore, if we show to the child new objects that he hasn't seen before, we could expect him to recognize correctly whether the new object is a chair or not, providing that we've given him enough positive and negative examples.
This is exactly the idea behind the perceptron.
Learning in perceptrons
Is the process of modifying the weights and the bias. A perceptron computes a binary function of its input. Whatever a perceptron can compute it can learn to compute.
"The perceptron is a program that learn concepts, i.e. it can learn to respond with True (1) or False (0) for inputs we present to it, by repeatedly "studying" examples presented to it.
The Perceptron is a single layer neural network whose weights and biases could be trained to produce a correct target vector when presented with the corresponding input vector. The training technique used is called the perceptron learning rule. The perceptron generated great interest due to its ability to generalize from its training vectors and work with randomly distributed connections. Perceptrons are especially suited for simple problems in pattern classification."
Professor Jianfeng feng, Centre for Scientific Computing, Warwick university, England.
The Learning Rule
The perceptron is trained to respond to each input vector with a corresponding target output of either 0 or 1. The learning rule has been proven to converge on a solution in finite time if a solution exists.
The learning rule can be summarized in the following two equations:
b = b + [ T - A ]
For all inputs i:
W(i) = W(i) + [ T - A ] * P(i)
Where W is the vector of weights, P is the input vector presented to the network, T is the correct result that the neuron should have shown, A is the actual output of the neuron, and b is the bias.
Training
Vectors from a training set are presented to the network one after another.
If the network's output is correct, no change is made.
Otherwise, the weights and biases are updated using the perceptron learning rule (as shown above). When each epoch (an entire pass through all of the input training vectors is called an epoch) of the training set has occured without error, training is complete.
At this time any input training vector may be presented to the network and it will respond with the correct output vector. If a vector, P, not in the training set is presented to the network, the network will tend to exhibit generalization by responding with an output similar to target vectors for input vectors close to the previously unseen input vector P.
So what can we use do with neural networks
Well if we are going to stick to using a single layer neural network, the tasks that can be achieved are different from those that can be achieved by multi-layer neural networks. As this article is mainly geared towards dealing with single layer networks, let's dicuss those further:
Single layer neural networks
Single-layer neural networks (perceptron networks) are networks in which the output unit is independent of the others - each weight effects only one output. Using perceptron networks it is possible to achieve linear seperability functions like the diagrams shown below (assuming we have a network with 2 inputs and 1 output)
It can be seen that this is equivalent to the AND / OR logic gates, shown below.
Figure 6 Classification tasks
So that's a simple example of what we could do with one perceptron (single neuron essentially), but what if we were to chain several perceptrons together? We could build some quite complex functionality. Basically we would be constructing the equivalent of an electronic circuit.
Perceptron networks do however, have limitations. If the vectors are not linearly separable, learning will never reach a point where all vectors are classified properly. The most famous example of the perceptron's inability to solve problems with linearly nonseparable vectors is the boolean XOR problem.
Multi layer neural networks
With muti-layer neural networks we can solve non-linear seperable problems such as the XOR problem mentioned above, which is not acheivable using single layer (perceptron) networks. The next part of this article series will show how to do this using muti-layer neural networks, using the back propogation training method.
Well that's about it for this article. I hope it's a nice introduction to neural networks. I will try and publish the other two articles when I have some spare time (in between MSc disseration and other assignments). I want them to be pretty graphical so it may take me a while, but i'll get there soon, I promise.
What Do You Think ?
Thats it, I would just like to ask, if you liked the article please vote for it.
Points of Interest
I think AI is fairly interesting, that's why I am taking the time to publish these articles. So I hope someone else finds it interesting, and that it might help further someones knowledge, as it has my own.
History
v1.0 17/11/06
Bibliography
Artificial Intelligence 2nd edition, Elaine Rich / Kevin Knight. McGraw Hill Inc.
Artificial Intelligence, A Modern Approach, Stuart Russell / Peter Norvig. Prentice Hall.

