Introduction
SQL Server doesn’t have so many aggregates to use. The basics, such as COUNT, MIN, MAX, etc., are implemented but still the list is quite small. This may lead to a situation where some of the calculations must be done in procedures, functions or even at client side.
However, SQL Server includes both CLR integration and the ability to define an aggregate implemented in .NET project. This combination makes it possible to create custom aggregates.
The First Aggregate, Calculating Product
C# Implementation
Creating an aggregate is quite straightforward. We need a simple class library (DLL) project targeting .NET Framework 3.5 (maximum for SQL Server 2008), implement the necessary structures and then register the assembly and the aggregates into the SQL Server.
An aggregate is created by defining a struct with SqlUserDefinedAggregate – attribute. Using the attribute, we can define for example the following options:
Format: Serialization format for the struct. This is typically either Native or UserDefined. In case of Native format, the framework handles all the necessary steps to serialize and deserialize the structure. IsInvariantToDuplicates (bool): Does receiving the same value twice or more affect the result IsInvariantToNulls (bool): Does receiving a NULL value change the result IsInvariantToOrder (bool): Does the order of values affect the result IsNullIfEmpty (bool): Does an empty set result to a NULL value Name (string): Name of the aggregate
The struct itself must contain at least the following methods:
Init: This is called when a new group of values is going to be handled using an instance of the structure Accumulate: Each value is passed to the Accumulate method which is responsible for making the necessary calculations, etc. Merge: This method is used when the original set of values is divided into several independent groups and after accumulating the group specific values, the group is merged to another group. Terminate: And finally when all values have been handled, Terminate returns the result.
Note that the structure may be re-used while using the aggregate. For this reason, it’s important to do all necessary initializations in the Init method and not to trust that the instance of a struct is a fresh one.
Merging is best explained with a small (simplified) diagram:
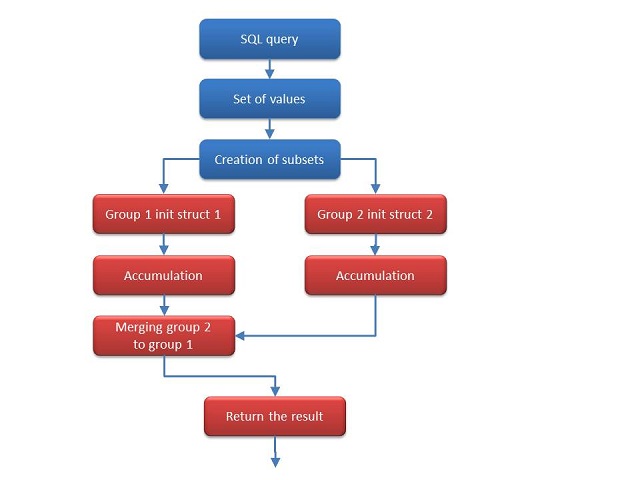
The query processor may divide a set of values to a smaller subsets called groups. When the aggregation is done, each group has its own instance of the structure to handle the subset. Each instance is first initialized and the accumulation is done for each value in the group. After this, the group is merged to another group. Finally, when all the groups have been merged, the aggregation is terminated and the result is returned to the consumer. For this reason, the aggregate must be designed to support operating on partial sets at accumulation time.
So far, lots of text and no code. So let’s have a look at the structure:
[System.Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedAggregate(
Microsoft.SqlServer.Server.Format.Native,
IsInvariantToDuplicates = false,
IsInvariantToNulls = false,
IsInvariantToOrder = true,
IsNullIfEmpty = true,
Name = "Product"
)]
public struct Product {
public System.Data.SqlTypes.SqlDouble Result { get; private set; }
public bool HasValue { get; private set; }
public void Init() {
this.Result = System.Data.SqlTypes.SqlDouble.Null;
this.HasValue = false;
}
public void Accumulate(System.Data.SqlTypes.SqlDouble number) {
if (!this.HasValue) {
this.Result = number;
} else if (this.Result.IsNull) {
} else if (number.IsNull) {
this.Result = System.Data.SqlTypes.SqlDouble.Null;
} else {
this.Result = System.Data.SqlTypes.SqlDouble.Multiply(this.Result, number);
}
this.HasValue = true;
}
public void Merge(Product group) {
if (group.HasValue) {
this.Result = System.Data.SqlTypes.SqlDouble.Multiply
(this.Result, group.Result);
}
}
public System.Data.SqlTypes.SqlDouble Terminate() {
return this.Result;
}
}
This aggregate is using only blittable data types which means that both SQL Server and the .NET Framework have common representation for the fields defined in the struct. Because of this, the aggregate is defined as Native in format and no additional steps need to be taken for the serialization.
The four mandatory methods are implemented and since this is a very trivial calculation, I believe that the code needs no thorough explanation. Only one note: Because of possible NULL values in the value set, NULL is handled as a special case so that NULL times anything always yields to NULL.
Registering to SQL Server
After the project has been successfully built, the next step is to register the assembly into the SQL Server. Before adding the assembly to the database, I chose to create a new schema. This is not mandatory but I felt that it would be nice to have the custom aggregates in one, separate place:
CREATE SCHEMA Aggregates;
After creating the schema, let’s upload the assembly:
CREATE ASSEMBLY CustomAggregates
AUTHORIZATION dbo
FROM '?:\???\CustomAggregates.dll'
WITH PERMISSION_SET SAFE;
Now the assembly is stored within SQL Server so we can register the newly created aggregate to the database:
CREATE AGGREGATE Aggregates.Product (@number float) RETURNS float
EXTERNAL NAME CustomAggregates.Product;
The aggregate is created in the Aggregates –schema. Data type float is used since this is the equivalent data type in SQL Server for the SQLDouble data type.
So now we’re ready to test the aggregate. First, a simple test-run:
SELECT Aggregates.Product(a.Val) AS Result
FROM (SELECT 2.1 AS Val UNION ALL
SELECT 5.3 AS Val) a
And the result is:
Result
------
11,13
Now the second test run, what if the set contains a NULL:
SELECT Aggregates.Product(a.Val) AS Result
FROM (SELECT 2.1 AS Val UNION ALL
SELECT NULL AS Val UNION ALL
SELECT 5.3 AS Val) a
The result is NULL as discussed earlier:
Result
------
NULL
And the last test-run is to use an empty set:
SELECT Aggregates.Product(NULL) AS Result
This also results NULL as it should.
A Slight Enhance, Geometric Mean
The next aggregate is very similar to the product since its geometric mean. Geometric mean is defined:

Now since this calculation cannot be done in accumulation (in this form) we calculate the product in accumulation and merge steps and the final result is calculated in the Terminate method. The structure could look like the following:
[System.Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedAggregate(
Microsoft.SqlServer.Server.Format.Native,
IsInvariantToDuplicates = false,
IsInvariantToNulls = false,
IsInvariantToOrder = true,
IsNullIfEmpty = true,
Name = "GeometricMean"
)]
public struct GeometricMean {
public System.Data.SqlTypes.SqlDouble Product { get; private set; }
public double ValueCount { get; private set; }
public void Init() {
this.Product = System.Data.SqlTypes.SqlDouble.Null;
this.ValueCount = 0;
}
public void Accumulate(System.Data.SqlTypes.SqlDouble number) {
if (this.ValueCount == 0) {
this.Product = number;
} else if (this.Product.IsNull) {
} else if (number.IsNull) {
this.Product = System.Data.SqlTypes.SqlDouble.Null;
} else {
this.Product = System.Data.SqlTypes.SqlDouble.Multiply(this.Product, number);
}
this.ValueCount++;
}
public void Merge(GeometricMean group) {
if (group.ValueCount > 0) {
this.Product = System.Data.SqlTypes.SqlDouble.Multiply(
this.Product, group.Product);
}
this.ValueCount += group.ValueCount;
}
public System.Data.SqlTypes.SqlDouble Terminate() {
return this.ValueCount > 0 && !this.Product.IsNull
? System.Math.Pow(this.Product.Value, 1 / this.ValueCount)
: System.Data.SqlTypes.SqlDouble.Null;
}
}
Let’s register the aggregate:
CREATE AGGREGATE Aggregates.GeometricMean (@number float) RETURNS float
EXTERNAL NAME CustomAggregates.GeometricMean;
And then the test:
SELECT Aggregates.GeometricMean(a.Val) AS Result
FROM (SELECT 34 AS Val UNION ALL
SELECT 27 AS Val UNION ALL
SELECT 45 AS Val UNION ALL
SELECT 55 AS Val UNION ALL
SELECT 22 AS Val UNION ALL
SELECT 34 AS Val) a
The result is:
Result
------
34,5451100372458
Using Partitioning
Partitioning can be used normally also with custom aggregates. For example, if we divide the previous data to two different categories and we want to have the geometric mean for each category, the query looks like:
SELECT DISTINCT
a.Cat,
Aggregates.GeometricMean(a.Val) OVER (PARTITION BY a.Cat) AS Result
FROM (SELECT 1 AS Cat, 34 AS Val UNION ALL
SELECT 1 AS Cat, 27 AS Val UNION ALL
SELECT 1 AS Cat, 45 AS Val UNION ALL
SELECT 2 AS Cat, 55 AS Val UNION ALL
SELECT 2 AS Cat, 22 AS Val UNION ALL
SELECT 2 AS Cat, 34 AS Val) a
When this is run, the result is:
Cat Result
--- ------
1 34,5688605753326
2 34,5213758169679
Using Multiple Parameters, Concatenate
When creating aggregates, float is definitely not the only data type that can be used. So in this last example, let’s look at few other things:
- Using multiple parameters
- Using
UserDefined format - Using
SQLString and SQLBoolean
The aggregate concatenates strings using the given delimiter. The third parameter controls the behavior of the aggregate. If NullYieldsToNull is true, a NULL in the values will result to NULL. When NullYieldsToNull is false, NULLs are completely ignored. The implementation:
[System.Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedAggregate(
Microsoft.SqlServer.Server.Format.UserDefined,
IsInvariantToDuplicates = false,
IsInvariantToNulls = false,
IsInvariantToOrder = false,
IsNullIfEmpty = true,
MaxByteSize = -1,
Name = "Concatenate"
)]
public struct Concatenate : Microsoft.SqlServer.Server.IBinarySerialize {
public System.Text.StringBuilder Result { get; private set; }
public System.Data.SqlTypes.SqlString Delimiter { get; private set; }
public bool HasValue { get; private set; }
public bool IsNull { get; private set; }
public bool NullYieldsToNull { get; private set; }
public void Init() {
this.Result = new System.Text.StringBuilder("");
this.HasValue = false;
this.IsNull = false;
}
public void Accumulate(System.Data.SqlTypes.SqlString stringval,
System.Data.SqlTypes.SqlString delimiter,
System.Data.SqlTypes.SqlBoolean nullYieldsToNull) {
if (!this.HasValue) {
if (nullYieldsToNull && stringval.IsNull) {
this.IsNull = true;
} else if (stringval.IsNull) {
} else {
this.Result.Append(stringval.Value);
}
this.Delimiter = delimiter;
this.NullYieldsToNull = nullYieldsToNull.Value;
} else if (this.IsNull && nullYieldsToNull.Value) {
} else if (stringval.IsNull && nullYieldsToNull.Value) {
this.IsNull = true;
} else {
if (!stringval.IsNull) {
this.Result.AppendFormat("{0}{1}", delimiter.Value, stringval.Value);
}
}
this.HasValue = this.HasValue ||
!(stringval.IsNull && !nullYieldsToNull.Value);
}
public void Merge(Concatenate group) {
if (group.HasValue) {
this.Accumulate(group.Result.ToString(),
this.Delimiter, this.NullYieldsToNull);
}
}
public System.Data.SqlTypes.SqlString Terminate() {
return this.IsNull ? System.Data.SqlTypes.SqlString.Null :
this.Result.ToString();
}
#region IBinarySerialize
public void Write(System.IO.BinaryWriter writer) {
writer.Write(this.Result.ToString());
writer.Write(this.Delimiter.Value);
writer.Write(this.HasValue);
writer.Write(this.NullYieldsToNull);
writer.Write(this.IsNull);
}
public void Read(System.IO.BinaryReader reader) {
this.Result = new System.Text.StringBuilder(reader.ReadString());
this.Delimiter = new System.Data.SqlTypes.SqlString(reader.ReadString());
this.HasValue = reader.ReadBoolean();
this.NullYieldsToNull = reader.ReadBoolean();
this.IsNull = reader.ReadBoolean();
}
#endregion IBinarySerialize
}
This needs a bit explanation. Since we’re using data types in fields that are not present in SQL Server, the format is marked as UserDefined. In this situation, the IBinarySerialize interface must be implemented in order to serialize and deserialize the results. Also note that the MaxByteSize is set now that we have to do our own serialization.
NULL is now handled separately (in IsNull property) so, that the StringBuilder can always contain an instance, but we’re still able to control if NULL should be returned.
Let’s see what happens with the tests. First registration:
CREATE AGGREGATE Aggregates.Concatenate (@string nvarchar(max),
@delimiter nvarchar(max),
@nullYieldsToNull bit) RETURNS nvarchar(max)
EXTERNAL NAME CustomAggregates.Concatenate;
And the test:
SELECT Aggregates.Concatenate(a.Val, ', ', 0) AS Result
FROM (SELECT 'A' AS Val UNION ALL
SELECT 'B' AS Val UNION ALL
SELECT 'C' AS Val) a
The result is:
Result
------
A, B, C
So, this simple case works. What about NULLs:
SELECT Aggregates.Concatenate(a.Val, ', ', 0) AS Result
FROM (SELECT 'A' AS Val UNION ALL
SELECT 'B' AS Val UNION ALL
SELECT NULL AS Val UNION ALL
SELECT 'C' AS Val) a
Resulting to:
Result
------
A, B, C
and
SELECT Aggregates.Concatenate(a.Val, ', ', 1) AS Result
FROM (SELECT 'A' AS Val UNION ALL
SELECT 'B' AS Val UNION ALL
SELECT NULL AS Val UNION ALL
SELECT 'C' AS Val) a
results to:
Result
------
NULL
More test runs are included in the downloadable script.
About the Performance
I was asked about the performance several times, so I decided to add some discussion about it into the article.
Using custom aggregates can never match the performance of built-in aggregates. One reason is that custom aggregates use MSIL (or CIL) since the logic is implemented using .NET languages. This means that the JIT compiler is involved so there's an overhead because of the compiling.
On the other hand, comparing built-in and custom aggregates isn't quite fair. You wouldn't create a new SUM aggregate because it already exists. Custom aggregates are handy to create new functionality into the database that do not exist. So when comparing the performance, it should be done as a whole. This means that the comparison should include at least:
- execution time
- the amount of pages read
- CPU usage (the DBMS server and the consumer)
- network traffic, etc.
But to give an example of the difference between built-in and custom aggregates, let's use both AVG and GeometricMean. First, we need some data so let's create a table:
CREATE TABLE SomeNumbers (
Value decimal not null
);
And then fill the table with 100'000 rows with random data. This will take a while, so be patient.
SET NOCOUNT ON
TRUNCATE TABLE SomeNumbers;
DECLARE @counter int;
BEGIN
SET @counter = 1;
WHILE @counter <= 100000 BEGIN
INSERT INTO SomeNumbers VALUES (RAND() * CAST(10 AS DECIMAL));
SET @counter = @counter + 1;
END;
END;
If we take the arithmetic mean (AVG), the amount of page reads is 234:
SELECT AVG(Value)
FROM SomeNumbers;
Statistics:
Table 'SomeNumbers'. Scan count 1, logical reads 234, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 26 ms.
Now let's compare this to the geometric mean:
SELECT Aggregates.GeometricMean(Value)
FROM SomeNumbers;
This will result to:
Table 'SomeNumbers'. Scan count 1, logical reads 234, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 78 ms, elapsed time = 83 ms.
So it's safe to say that the custom aggregate in this case was roughly 4 times slower than the built-in aggregate. But again calculating a different thing.
When running this example, you may encounter an arithmetic overflow. This is because the geometric mean calculates the product of elements and if there's no zero present, this calculation quickly overflows. With greater amounts of data or with large numbers, the calculation itself should be done differently.
Common Pitfalls
Few words about common pitfalls that may cause gray hair:
- When you make modifications to the source code and recompile the assembly, it’s not automatically refreshed in the SQL Server since the database has its own copy of the assembly. Use
ALTER ASSEMBLY command to ’refresh’ the DLL in the database without having to drop the aggregates. - If the signature of a method is changed (for example, parameter data type changes or parameters are added),
ALTER ASSEMBLY cannot be used until the aggregate changed is first dropped from the database. - The matching data types in SQL Server and CLR are not always so easy to know. Use data type mapping documentation provided by Microsoft: System.Data.SqlTypes Namespace
- The SQL Server equivalent for
SQLString is nvarchar, not varchar. Using varchar in the CREATE AGGREGATE statement results to error 6552. - Also calling
SQLString.Concat(some SQLStringInstance from database, c# string) may fail with error 6552 since the ordering is different.
That’s it this time. Hopefully, you find custom aggregates useful. I’d be grateful if you would have the extra time for comments and votes. Thank you.
History
- March 18, 2011: Created
- March 27, 2011:
- Correction: Merge step for
GeometricMean didn't include the addition of elements. Thanks to Marc Brooks for noticing this. - Added discussion about the performance

