Table of contents
Introduction
Beyond websites, there are other types of applications which -if not impossible- can not be easily built using the web. What the web offers
as a technology is good for situations where we need to publish content and ensure the immediate and easy deployment of changes incurred to it.
The user only reacts to content. If he reacts with other users, then its "reaction" is compiled into the content, persisted, then shown
to others when they request it. Applications that need to broadcast information in real time, or applications that want to enable connected users
to "engage" with each other in real time need a dedicated technology.
For the simplest example, think of a chat application, or a media streaming server. You can also think about many sophisticated applications
that collect signals from a large number of remotely connected devices and provide a timely decision. Such technology should be able to manage
a large number of active full duplex connections. It should be able to relay information from a connection to another one in an immediate
way and enable the efficient and asynchronous broadcast of information so that spontaneous and timely responses are received by the client-side.
I would like to give you my contribution here in the form of a C++ library which emerged from multiple refactoring of the server side code
of an amateur chess server I am developing, and which I hope people may find useful for other domains as well. Beyond this article,
you can find articles, complete documentation guides, and other helpful material at the Push Framework
home page: http://www.pushframework.com.
Deployment layout
Let us look at the deployment picture here. Your server logic will be written on top of the Push Framework library.
It is clear if you want to deploy the application, then you need a dedicated server machine. You should design / use a protocol that helps the efficient
communication between your client side application and the server side of it. Clients will connect to a TCP port that you specify. It is possible that you
have heterogeneous clients which use different protocols to talk with your server. One major feature of the library however is its ability to profile itself and
send periodic statistics. You just need to activate that feature with a simple API call and connect the Dashboard, a separately developed Applet,
to the "monitoring" port of the server so you can receive the "feed" of those stats.

The developer perspective
Personally, as a developer, when I discover a new library and want to asses it, I hurry to look at an example usage code. From there,
I can see the big picture. So let me sacrifice many essential details here and only report the main view. A single instance encapsulates all of the library functionalities:
PushFramework::Server server;
Configure such an instance by calling the member methods, then call start to run your server. This is how the code surrounding that instance
would look like when you are finished:
PushFramework::Server server;
server.setClientFactory(pClientFactory);
server.setProtocol(pProtocol);
server.createListener(sPort);
server.registerService(myServiceId, pService, "myService";
server.start(false);
Now questions are raised. Well first, pClientFactory should point to a concrete implementation of the PushFramework::ClientFactory class.
This class manages the life cycle of clients connecting to the server. In particular it decides on when a newly accepted connection gets transformed into
a legitimate client (PhysicalConnection => LogicalConnection). Also, it manages the case when a client reconnects (abrupt TCP failures can happen,
then the same client reconnects) and when we need to bind the new TCP socket to the existing client information and previously allocated resources.
Note that in the servicing code, you never deal with the socket, you rather deal with reference to a PushFramework::LogicalConnection object that represents the client.
The protocol is an all essential information. You pass this by providing a concrete implementation of the PushFramework::Protocol class
to the ::setProtocol method or within the ListenerOptions parameter of ::createListener if you intend to support
multiple protocols. By overriding its pure methods, you will tell the library how the received information should be deserialized and how the outgoing
information should be serialized. To send an information to a specific client or to a specific group of clients (broadcast), PushFramework expects input
in the form of instances of type PushFramework::OutgoingPacket. Encoding and framing is acted upon such a class. When data is received,
decoding and deframing are triggered and that is called de-serialization. At the end of the day, deserialized data is communicated back in the form
of IncomingPacket instances. These instances are dispatched to your "servicing code" which you may find it useful to organize
into many "services" (very useful when there are multiple types of requests that can be received with each type requiring a special processing).
A service is materialized by an instance of a PushFramework::Service subclass. You devise your business logic by overriding the handle
method of it, then you affect an ID to the instance. Of course, you should take care of passing that ID information at de-serialization time so the library knows how to route the packets.
Let us see how you can treat incoming data. In the first case, we will handle a particular request and echo back a response to the requestor:
MyService::handle(LogicalConnection* pClient, IncomingPacket* pRequest)
{
OutgoingPacket response;
pClient->push(&response);
}
The library is multithreaded. To be more precise, multiple threads are spawn to execute the servicing code. So the code in the handle method of your Service subclasses
is a concurrent one. Let us consider this example where information has to be relayed from a connection to another connection.
For example, imagine we are in the context of a chat application, and we want to route a chat message :
MyService::handle(LogicalConnection* pClient, IncomingPacket* pRequest)
{
ClientKey recipientKey; char* msg CMyClient* pRecipient = FindClient(recipientKey);
if(pRecipient)
{
OutgoingPacket response;
pRecipient->push(&response);
ReturnClient(pRecipient);
}
}
Finally, let us see how to send broadcast information.
MyService: public PushFramework::Service
{
void handle(LogicalConnection* pClient, IncomingPacket* pRequest)
{
PushFramework::OutgoingPacket* pResponse = new PushFramework::OutgoingPacket();
broadcastManager.PushPacket(pResponse, quot;broadcastGroup1");
}
}
Technical architecture
It is good to have a look at the internals of the library even though you would only find yourself dealing with a handful of public classes that encapsulate
all the details. Let me ease it by enumerating the notes.
- To efficiently manage interaction with the system, the library uses Completion Ports (IOCP) for Windows Server and Two Epoll queues for Linux.
IOQueue acts like a Multiple-Producers Multiple Consumers Queue. The Demux module is responsible for
establishing the Consumers threads.
These receive the system IO events (either completion events in case of Windows, or readiness events in case of Linux) and process them. - The main thread is the one that manages the different part of the system : it launches the separate listening threads, the worker threads,
the streaming threads and schedules periodic tasks like garbage collection, scrutinizing illegitimate connections, collecting performance measures.
It also listens on the termination signal so it can stop all threads and clean all memory.
- Listening is performed by a separate thread. Incoming connection requests are communicated to the Channels factory. There happens the decision
to associate the connection (PhysicalConnection) with a new Client object (LogicalConnection) or to attach it to an existing one (client reconnection identification).
- The demux communicates the sending/receiving operation completion status back to the dispatcher. When a Write operation finishes, the intermediate
Send buffer is examined for any outstanding data to be sent. If a Read operation completes, the dispatcher triggers de-serialization which in turn calls
the protocol-defined de-framing and decoding code, then gives back control to the handle method of the Service object responsible of the incoming request type.
- Most of execution time is spent on the available
Service::handle methods. There you put the processing logic for each type of an incoming request.
Naturally there you would push data to specific clients or to a broadcasting channel so the library implicitly streams the information to the list of client that are subscribed. BroadcastStreamerManager launches a list of threads that stream broadcast messages from broadcast queues to subscribed LogicalConnections. So each streamers
is responsible for a collection of clients- Each broadcasting channel has four attributes:
requireSubscription, maxPacket, priority, and quota.
If requireSubscription is false, then all logged clients are implicitly subscribed to it. Otherwise, you must explicitly register each client you want. - Each broadcasting channel maintains a FIFO queue of the packets that are pushed into it.
maxPacket is its maximum size. Ancient packets get released
when the queue is full. Avoiding the phenomenon of broadcast amplification (uncontrollable increased memory consumption) comes at the cost of packet
loss for those clients with B(i) < F(j) where B(i) is the available bandwidth between the server and the client i, and F(j) is the fill rate of broadcasting
channel j which i is subscribed to. - When the bandwidth between a certain client x and the server along with the server’s degree of activity are such that not all data can be streamed out,
the share of each broadcasting channel to which client x is subscribed is dependent on the priority and quotas attributes.
- Suppose that broadcasting channels {Ci} are ordered in such way that if i < j => (either Pi > Pj or (Pi = Pj and Qi >= Qj)), P and Q being the priority and quota attributes.
- Let’s denote Fi as the rate at which Ci is filled with new packets.
- Let’s assume S to be the total rate of broadcast data sent to client x.
- Further assuming that all outgoing messages have the same length.
Then, the share Si of broadcasting channel i is given by:
- The monitoring listener is started in case remote monitoring is enabled. It helps accept connections from remote Dashboards so profiling info are sent.
Tutorials and examples
Chat application
The best way you can see the Push Framework in action is to guide you in the development of a whole new application that will be based on it. This allows
to better assess the library and weigh multiple factors at once.
You can follow the step-by-step tutorial here. Source code and binaries are also available.
The application that is developed uses XML to encode requests and responses. The server and the client "see" the same prototypes that represent
those requests/responses. If a direct chat message is received, the server knows the destination client and forwards the request to the relevant connection.
At startup, the chat server creates broadcasting channels to represent the "available chat rooms". If a room chat request is received, a room chat response
is pushed into the corresponding broadcasting channel so every participant in the room receives that response. Joining a room is technically implemented by "subscribing"
a client to a broadcasting channel. The same goes for how to let chat participants see each other: a broadcasting channel is setup and filled with signal packets each time a client logs in.
Client-server using the Google Protobuf protocol
Google says it created its own protocol to let its heterogeneous applications exchange data. Encoding/decoding is extremely fast and produces a minimum message. To allows
users who want to use this protocol along side Push Framework, a client-server application is created. You can follow the
complete tutorial here. The functionality is extremely simple: the client sends a request about some item
with a particular ID. The response is expected to contain the detailed information about that item. One can imagine anything, the aim here is just to let
the integration between ProtoBuf and the Push Framework be understood.
Communication data must be designed in a specific language before being compiled by ProtoBuf so we can produce the classes with which we can work with.
For our example, we need to design these three structures only:
package gprotoexample;
message LoginRequest {
}
package gprotoexample;
message LoginResponse {
required bool result = true;
}
package gprotoexample;
message DataInfoRequest {
required int32 id = 2; }
package gprotoexample;
message DataInfoResponse {
enum ResultType {
InfoFound = 0;
InfoNotFound = 1;
InfounspecifiedError = 2;
}
required ResultType result = 0;
required int32 id = 1; optional string description = 1;
}
package gprotoexample;
message LoginResponse {
required bool result = true;
}
For use with C++, the ProtoBuf compiler produces C++ classes that we include in our project. To adapt ProtoBuf and allow multiple messages
to be sent in the same connection (ProtoBuf messages are not self delimiting), we create a new PushFramework::Protocol subclass
alongside a template class, deriving both from PushFramework::OutgoingPacket and PushFramework::IncomingPacket which are the currency for the Push Framework:
class ProtobufPacketImpl : public PushFramework::IncomingPacket,
public PushFramework::OutgoingPacket
{
public:
ProtobufPacketImpl(int serviceId);
~ProtobufPacketImpl(void);
protected:
virtual bool Decode(char* pBuf, unsigned int nSize);
virtual bool Encode();
virtual google::protobuf::Message& getStructuredData() = 0;
private:
int serviceId;
std::string* pEncodedStream;
public:
std::string* getEncodedStream() const { return pEncodedStream; }
int getEncodedStreamSize();
int getServiceId() const { return serviceId; }
};
template<class T>
class ProtobufPacket : public ProtobufPacketImpl
{
public:
ProtobufPacket(int serviceId)
: ProtobufPacketImpl(serviceId)
{
}
~ProtobufPacket()
{
}
private:
T data;
public:
virtual google::protobuf::Message& getStructuredData()
{
return data;
}
};
Here is how the servicing code looks like when we receive a datainforequest:
void CDataInfoRequestService::handle( LogicalConnection* _pClient, IncomingPacket* pRequest )
{
ExampleClient* pClient = (ExampleClient*) _pClient;
ProtobufPacket<DataInfoRequest>* pDataInfoRequest =
(ProtobufPacket<DataInfoRequest>*) pRequest;
ProtobufPacket<DataInfoResponse> response(DataInfoResponseID);
response.getData().set_id(pDataInfoRequest->getData().id());
response.getData().set_result(DataInfoResponse_ResultType_InfoFound);
response.getData().set_description("this is a description");
pClient->pushPacket(&response);
}
Using Websocket to communicate with Web clients
You can use this library to create servers that communicate with web applications using the Websocket protocol.
This makes it possible to create web interfaces that shows real time information by receiving "streaming data" from Push Framework.
Also, it is feasible to create a live community engaging in real time using the web.
A C++ Websocket Server For realtime interaction with Web clients
is an Open Source project that features a complete application where a web page communicates with a PF-based server using Websocket as framing protocol.
Benchmarking
Monitoring the chat application
An interesting feature of the Push Framework is its ability to profile itself and send a real time report to a remote Dashboard where the numbers are drawn
into usable display in the form of qualitative charts and grids. You activate this by calling a simple method of your server object:
server.enableRemoteMonitor(monitoringPort, password);
server.enableProfiling(samplingRate);
monitoringPort is the listening port that the Monitoring Listener will listen to. Of course, you will have to put that information
in the Dashboard login info along with the server IP and password so your connection succeeds. The dashboard can be used to execute remote commands.
By overriding Server::handleMonitorRequest, you can receive any input that your user tapes in the Dashboard console. The answer is redirected
in the form of a text in the console. Statistics and Performance information can not be displayed in the Dashboard unless you make a call
to Server::enableProfiling. This instructs the library to start to collect performance values and send a report at a regular interval of samplingRate seconds.
The aim now is to let you see the use of the remote monitoring features. So let's enable profiling in the previously developed chat server and try
to connect to the server using the Monitoring Dashboard. To be close to a real world scenario where a very large number of people connect to the same chat
server and chat with each other, I've made a separate multi-clients simulator able to launch many connections and approximately behave like a human participant
who sends chats, replies to receive chat, and also engages in chat rooms. This is contained in the ChatRobots project. The Simulator is- to tell the truth- not very optimized
because it launches one thread for each Chat Robot. So this can lead to some issues when launching many clients.
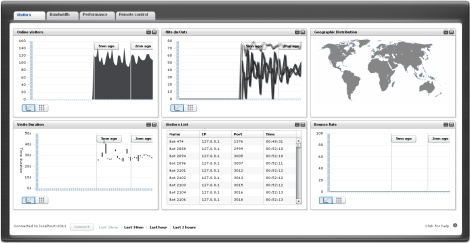
In one test, 100 bots were started against the previous chat server which reports profiling at intervals of 10s duration. The following is a screenshot
of the Performance tab of the Dashboard:
You can find other screenshots and read details in this article: Bursting the Library. A zoom on the Time Processing Zone gives:
The vertical segments represent the periodic report that is sent every 10 seconds. The segment center is the average processing time of all the requests that
were received within the specific observation interval. The vertical length is the dispersion calculated and sent by the server.
This profiling feature can help you a lot when you design an application and decide to deploy it. I think even at deployment time, it may still be useful to keep
profiling activated as it does not cost much time and may give valuable information about your visitor's behavior, the incoming/outgoing bandwidth of exchanged data,
and the performance the server is able to give in terms of throughput (number of requests per seconds), processing time, etc.
Broadcast QoS
The goal in this article is to validate the claim that Push Framework is able to provide different priorities and quotas for each broadcasting channel.
This QoS feature is explained in the Developer Guide page (see the Broadcasting data paragraph).
For that goal, a new client-server application will be developed. The Push Framework – based server will setup a number of broadcasting channels having
different priorities/quotas attributes and constantly fill them with packets. At the client side, we collect the received packets and try report statistics.
The protocol to use for the demo is really simple: we just need to record the broadcasting channel each incoming packet belongs to. An extra payload of 8K
is however added in order to put ourselves in a realistic application protocol. Broadcasting channels (broadcasting groups) are setup before the call to Server::start:
broadcastManager.CreateQueue(
broadcastId, 100, false, uPriority, uQuota);
server.start();
For each broadcasting group, a new thread is spawned to push packets into it. You can examine the code details in the QoS Application Validation package.
More results and details are reported in the article, I just report one scenario here where we have three broadcasting channels sharing the same priority:
1 => { priority = 5, quota = 10 }
2 => { priority = 5, quota = 20}
3 => { priority = 5, quota = 5}
The effect of the quota parameter can be seen in the following client-side statistics:
References
This work would not have been possible without other people's contributions that cleared the many technical dusts of server development:
History
This is the first release of this article. By this time, the furnished material may have changed or become obsolete,
so visit the library home page to get the latest updates, and engage in the Forum
space to help others and get help.

