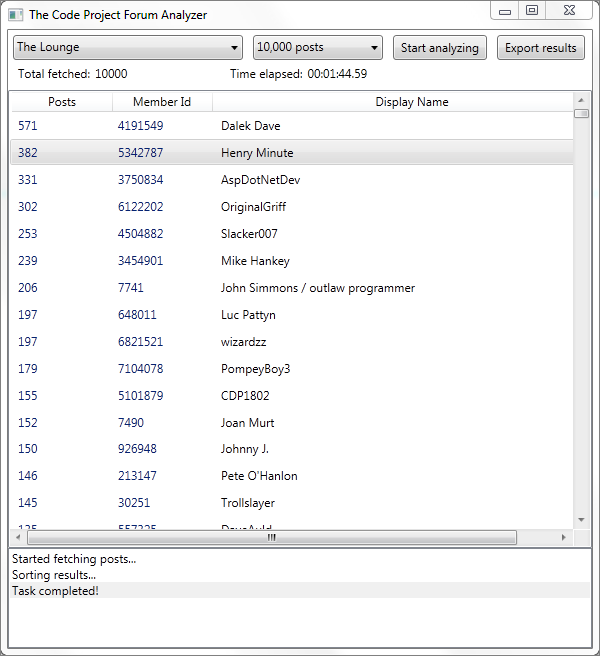
Figure 01 - The app in action, analyzing Lounge posts

Figure 02 - Charting the exported CSV data in Excel
Introduction
This is an unofficial Code Project application that can analyze forums over a
range of posts to retrieve posting statistics for individual members. Like my
other Code Project applications (and that of others like John and Luc), this app
uses HTML scraping and parsing to extract the required information. So any
change to the site layout/CSS can potentially break the functioning of this
application. There's no workaround for that until the time that Code Project
provides an official web-service that will expose this data.
Using the app
I've got a hardcoded list of forums that are shown in a combo-box. I chose
the more important forums and also the ones with a decent amount of posts. You
can also choose the number of posts you want to fetch and analyze. The app
currently supports fetching 1,000 posts, 5,000 posts, or 10,000 posts. Anything
more than 10,000 is not safe as you will then start seeing the effects of the
heavy-loaded Code Project database servers, which means time outs and lost
pages. This won't break the app but the app will be forced to skip pages which
results in reduced statistical accuracy. Even with 10,000 posts you can still
hit this on forums like Bugs/Suggestions or C++/CLI because some of the older
pages have posts with malformed HTML which breaks the HTML parser. There is a
status log at the bottom of the UI which will list such parsing errors and at
the end of the analysis will also tell you how many posts were skipped.
Figure 03 - Forums with malformed HTML will result in
skipped posts (49 in the screenshot)
CP has added stricter checks on the HTML that's allowed in posts, so you
should see this less frequently as time progresses. Once the analysis is
done, you can use the Export feature to save the results in a CSV
file. You can now open this CSV file in Excel and do further analysis and
statistical charting.
Handy Tip
If you hover the mouse over a display name it'll highlight the display name
and the mouse cursor turns into a hand. This means you can click the display
name to open the user's CP profile in the default browser, and you can do this
even as an analysis is in progress.
Exporting to CSV and foreign language member-names
It should correctly choose the comma-separator based on your current locale
(thanks to
Mika Wendelius for helping me get this right) but I do not save the file
as Unicode. That's because Excel seems to have trouble with it and treats it as
one big single column (instead of 3 separate columns). So right now I am using
Encoding.Default which is a tad better than not using any, but you
may run into weirdness in Excel if any of the member display names have Unicode
characters. I have not figured out how to work around that and at the moment I
don't know if I want to spend time researching a fix. If any of you know how to
resolve that, I'd appreciate any suggestions you have for this.
Implementation details
The core class that fetches all the data from the website is the
ForumAnalyzer
class. It uses the excellent
HtmlAgilityPack for
HTML parsing. Here are some of the more interesting methods in this class.
private void InitMaxPosts()
{
string html = GetHttpPage(GetFetchUrl(1), this.timeOut);
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
HtmlNode trNode = document.DocumentNode.SelectNodes(
"//tr[@class='forum-navbar']").FirstOrDefault();
if (trNode != null)
{
if (trNode.ChildNodes.Count > 2)
{
var node = trNode.ChildNodes[2];
string data = node.InnerText;
int start = data.IndexOf("of");
if (start != -1)
{
int end = data.IndexOf('(', start);
if (end != -1)
{
if (end - start - 2 > 0)
{
var extracted = data.Substring(start + 2, end - start - 2);
Int32.TryParse(extracted.Trim(),
NumberStyles.AllowThousands,
CultureInfo.InvariantCulture, out maxPosts);
}
}
}
}
}
}
That's used to determine that maximum number of posts in the forum. Since the
pages are dynamic, you won't get an error if you try fetching pages beyond the
last page, but it will waste time and bandwidth and also mess up the statistics.
So it's important to make sure that we know what the maximum number of pages we
can fetch safely.
public ICollection<Member> FetchPosts(int from)
{
if (from > maxPosts)
{
throw new ArgumentOutOfRangeException("from");
}
string html = GetHttpPage(GetFetchUrl(from), this.timeOut);
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
Collection<Member> members = new Collection<Member>();
foreach (HtmlNode tdNode in document.DocumentNode.SelectNodes(
"//td[@class='Frm_MsgAuthor']"))
{
if (tdNode.ChildNodes.Count > 0)
{
var aNode = tdNode.ChildNodes[0];
int id;
if (aNode.Attributes.Contains("href")
&& TryParse(aNode.Attributes["href"].Value, out id))
{
members.Add(new Member(id, aNode.InnerText));
}
}
}
return members;
}
This is where the post data is extracted. It takes advantage of the
Frm_MsgAuthor CSS class that Code Project uses. Now that I've mentioned this
here, I bet Murphy's laws will reveal themselves and Chris will rename that
class arbitrarily. Note that this class will just return post data in big chunks
so it's up to the caller to actually do any analysis on the data. I do that in
my application's view-model. This decision may be questioned by some people who
may feel that a separate wrapper should have done the calculations and the VM
should have then merely accessed that. If so, yeah, they're probably right but
for such a simple app I went for simplicity versus design purity.
The code that uses the ForumAnalyzer class is called from a
background worker thread, and when it completes, a second background worker is
spawned to sort the results. I've also used Parallel.For from the
Task Parallel Library which gave me a significant speed boost. Initial runs took
8-9 minutes on my connection (15 Mbps, boosted to 24 Mbps) but once I added the
Parallel.For, this went up to a little over a minute. Going from
around 8 minutes to 1 minute was quite impressive! There were a few side effects
though which I will talk about after this code listing.
private void Fetch()
{
canFetch = false;
canExport = false;
this.logs.Clear();
var dispatcher = Application.Current.MainWindow.Dispatcher;
Stopwatch stopWatch = new Stopwatch();
BackgroundWorker worker = new BackgroundWorker();
worker.DoWork += (sender, e) =>
{
ForumAnalyzer analyzer = new ForumAnalyzer(this.SelectedForum);
dispatcher.Invoke((Action)(() =>
{
this.TimeElapsed = TimeSpan.FromSeconds(0).ToString(timeSpanFormat);
this.Total = 0;
this.results.Clear();
AddLog(new LogInfo("Started fetching posts..."));
}));
Dictionary<int, MemberPostInfo> results =
new Dictionary<int, MemberPostInfo>();
stopWatch.Start();
ParallelOptions options = new ParallelOptions()
{ MaxDegreeOfParallelism = 8 };
Parallel.For(0, Math.Min((int)(PostCount)this.PostsToFetch,
analyzer.MaxPosts) / postsPerPage, options, (i) =>
{
ICollection<Member> members = null;
int trials = 0;
while (members == null && trials < 5)
{
try
{
members = analyzer.FetchPosts(i * postsPerPage + 1);
}
catch
{
trials++;
}
}
if (members == null)
{
dispatcher.Invoke((Action)(() =>
{
AddLog(new LogInfo(
"Http connection failure", i, postsPerPage));
}));
return;
}
if (members.Count < postsPerPage)
{
dispatcher.Invoke((Action)(() =>
{
AddLog(new LogInfo(
"Html parser failure", i, postsPerPage - members.Count));
}));
}
lock (results)
{
foreach (var member in members)
{
if (results.ContainsKey(member.Id))
{
results[member.Id].PostCount++;
}
else
{
results[member.Id] = new MemberPostInfo()
{ Id = member.Id, DisplayName = member.DisplayName,
PostCount = 1 };
dispatcher.Invoke((Action)(() =>
{
this.results.Add(results[member.Id]);
}));
}
}
dispatcher.Invoke((Action)(() =>
{
this.Total += members.Count;
this.TimeElapsed = stopWatch.Elapsed.ToString(timeSpanFormat);
}));
}
});
};
worker.RunWorkerCompleted += (s, e) =>
{
stopWatch.Stop();
BackgroundWorker sortWorker = new BackgroundWorker();
sortWorker.DoWork += (sortSender, sortE) =>
{
var temp = this.results.OrderByDescending(
ks => ks.PostCount).ToArray();
dispatcher.Invoke((Action)(() =>
{
AddLog(new LogInfo("Sorting results..."));
foreach (var item in temp)
{
this.results.Remove(item);
this.results.Add(item);
}
}));
};
sortWorker.RunWorkerCompleted += (sortSender, sortE) =>
{
AddLog(new LogInfo("Task completed!"));
canFetch = true;
canExport = true;
CommandManager.InvalidateRequerySuggested();
};
sortWorker.RunWorkerAsync();
};
worker.RunWorkerAsync();
}
When I added the Parallel.For, the first thing I noticed was
that the number of errors and time outs significantly went up to the point
where the results were almost useless. What was happening was that I was
fighting CP's built-in flood protection and I realized that if I spawned too
many connections in parallel, this just would not work. With some trial and
error, I finally reduced the maximum level of concurrency to 8 which gave me the
best results. Coincidentally I have 4 cores with hyper threading, so that's 8
virtual CPUs - so this was perfect for me I guess. Note that this is pure
coincidence, the reason I had to reduce the parallelism was the CP
flood-prevention system and not the number of cores I had.
A major side effect of using Parallel.For was that I lost the
ability to fetch pages in a serial order. Had I not used the parallel loops, I
could detect an HTML parsing error, and then skip that one post and continue
with the post after that one. But with concurrent loops, if I hit an error, I am
forced to skip the rest of the page. Of course, it's not impossible to handle
this correctly by spawning off a side-task that will fetch just the skipped
posts minus the malformed one, but this seriously increased the complexity of
the code. I decided that I can live with 50-100 lost posts out of 10,000. That's
less than a 1% deviation in accuracy which I thought was acceptable for the
application.
Well, that's it. Thanks for reading this article and for trying out the
application. As usual, I appreciate any and all feedback, criticism and
comments.
References
- Html Agility Pack - Awesome library! Nothing else like it!
Acknowledgements
Thanks to the following CPians for their help with testing the application!
Really, really appreciate that. I only listed the first 3 folks, but many others
helped too. So thanks goes to all of them, and I apologize for not listing
everybody here (I didn't realize so many would be so helpful)!
History
- March 26, 2011 - Article first published

