Introduction
This article builds on Exsead to create a JScript DOM parser and an XML viewing GUI.
Some Background on Exsead, Etc.
The core concept behind Exsead is covered here. Also, to benefit most from this post, it would really help if you have already looked at the post on using Internet Explorer as a script GUI which is here. The code here also takes advantage of my system for reading binary files in JScript, which is described in detail here. More background on the AJAX used in this post is here.
Inside the code example is XMLViewer.js. This script uses the Model, View Controller concept to structure a simple but effective XML data viewer. An even simpler MVC example is also included (the one from the previous post on using Internet Explorer as a GUI), it is called MVCExample.js (no imagination at all...). The purpose of any script that parses XML like this is to take the raw data stored in the XML and convert it into usable knowledge. Just by itself, XML is totally static data and is of no use; it must be parsed into a program before it 'comes to life'. This is exactly what XMLViewer.js does.
XMLViewer.js is quite a long script as it performs a few different functions to reach its goal. However, the overall structure is very simple; the parts are like this:
ProcessArguments: This function processes arguments passed to the script or if none are passed, takes a default action.DisplayXML: This does what it says, it pushes a visual representation of the XML to an Internet Exporter GUI.XMLClean: This is just a simple utility to escape &tl; symbols out of text.ProcessNode: As we will see later, XML is stored as a tree of nodes, this function is used by DisplayXML to run through the entire tree, creating an HTML representation of the XML structure as it goes.GUIWindow: This is an object function - i.e., a function that creates an object. The object it creates is a wrapper around an instance of Internet Explorer. The class can then be used as the method DisplayXML uses for sending the visual (HTML) representation of the XML to Internet Explorer.BinaryFile: As another object function, this creates BinaryFile objects which permit JScript to read and write files as binary rather than text. It is used to read in XML files.ConcatStringArray: This is a very handy utility which takes an array of strings and returns the string created by joining them all together. This is very much faster than just adding loads of strings together where the strings start to get long.
Process Arguments
If you pass arguments to the script, which is what happens if you drag and drop an XML file onto the script's icon, this function will read the file as a binary file and then pass the contents to DisplayXML. If there are no arguments, then Process Arguments uses AJAX to get an XML data stream from the Nerds-Central ATOM feed and passes the returned XML to DisplayXML.
This is the Arguments/File Read part:
=====================================
for(var i=0;i<WScript.arguments.count();++i)
{
var chunks;
var fn=WScript.arguments.item(i);
var bf1=new BinaryFile(fn);
var xml=bf1.ReadAll();
DisplayXML(xml);
}
This is the AJAX Part:
======================
var ajax=WScript.CreateObject('Microsoft.XMLHTTP');
for(var i=0;i<32;++i)
{
try
{
ajax.open
('GET','http://nerds-central.blogspot.com/feeds/posts/default',false);
ajax.setRequestHeader
(
'Connection',
'close'
);
ajax.send();
if(!ajax.status==200) throw('Got Wrong Status:'+ajax.status);
break;
}
catch(e)
{
for(var a in e)
{
WScript.Echo(a + '=' + e[a]);
}
WScript.echo('Failed to get atom feed from Nerds-Central:
tries left='+(32-i));
}
}
if(i!=32)DisplayXML(ajax.responseText);
DisplayXML
Given a piece of XML as a string, this function parses it using a Microsoft DOM parser. It then locates the Document part of the DOM (a DOM - document object model - has other parts to it as well as the document itself).
var xmlDOM = new ActiveXObject("Microsoft.XMLDOM");
xmlDOM.loadXML(xml);
var doc=xmlDOM.documentElement;
Once it has the document element, it creates an Array which will be used to store all the output HTML. This approach is taken because new bits of HTML can just be 'pushed' to the end of the array very efficiently and then the whole array is converted to a string at the last minute.
To understand the next piece of the puzzle, we have to understand how the DOM concept models XML. As with most modern software concepts, it is actually much simpler than many would like us to believe! There are two core concepts to understand when working with XML:
- Everything is a node.
- Ignore everything you don't need to worry about.
Nodes are really just simple containers. They can contain other nodes, or they can contain text. So a piece of XML like this <tt><myParent><myChild>Hello World</myChild></myParent></tt> will be stored in the DOM as 3 nodes. The first node will have the nodeName of myParent. It will have one child which will have the nodeName of myChild. The myChild node will have one child as well. But this child does not have a name. However, it does contain the text. It has a nodeValue of Hello World.
So that we can tell the difference between nodes that contain text and those which contain other nodes (or could contain other nodes, but happen to be empty) each node has a nodeType. Node types 3 and 4 contain text.
We are nearly there in understanding nodes! The last piece we need for this post is the concept of 'attributes'. Attributes as the key="value" things that live inside XML. For example <tt><myParent gender="female">Dorris</myParent></tt> could be a piece of XML indicating that someone's mother was called Dorris. Attributes are an alternative to using more complex XML structures like this: <tt><myParent><tname>Dorris</name><gender>female</gender></myParent></tt>. If you were to print out all the discussion on the Internet as to when attributes should or should not be used, you would probably wipe out the Amazon rain forest. So, for now I think we should just accept that they can be used!
The document element of the DOM is itself a node. All XML documents must have one outer node of which all others are descendants. ProcessNode takes a node and generates an HTML representation of that node and all its descendants. So DisplayXML, passes the document element (why it is not called the document node - I do not know) to ProcessNode.
ProcessNode
Want to be scared? Well ProcessNode is a 'recursive descendent processor'. Sounds really complex, mind boggling and scary... But again, it is actually quite simple. The reasoning goes a bit like this: Every node either has a value or children. We have a function and process a parent node. A parent node is just the same as a child node. So, we use the same function to process the parent node and its children. The easiest way to do this is to get the function that processes the parent to call itself for each of the children. A function which calls itself is called recursive. A function that uses recursion to 'walk down a parent/child relationship' is called recursive descendent. Finally, it processes the nodes as it goes, so it is a recursive descendent processor.
function ProcessNode(node,outArr)
{
if(node.nodeType<3 || node.nodeType>4)
{
... node.nodeName ...
var atts=node.attributes;
if(atts.length>0)
{
for(var i=0;i<atts.length;++i)
{
var aNode=atts.item(i);
... aNode.nodeName ...
... aNode.nodeValue ...
}
}
if(node.hasChildNodes())
{
var newNode=node.firstChild;
while(newNode!=null)
{
ProcessNode(newNode,outArr);
newNode=newNode.nextSibling;
}
}
}
else
{
... node.nodeValue ...
}
}
Finally We Push the HTML Visualization of XML to the GUI
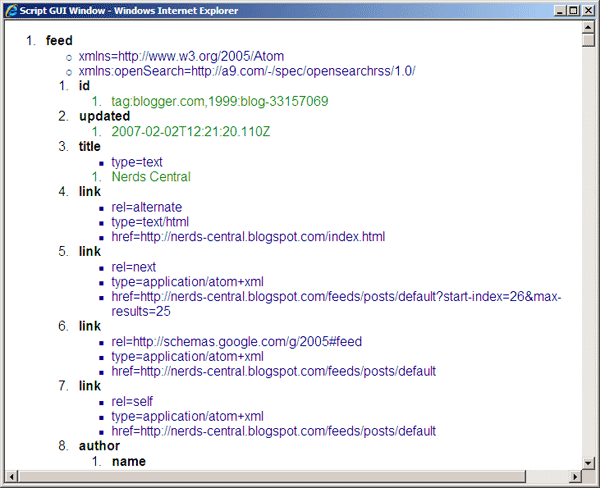
This is created using the following piece of code:
var out=ConcatStringArray(outArr);
var gui= new GUIWindow();
gui.SetHTML(out);
var doc=gui.GetDocument();
var styleSheet;
if(doc.styleSheets.length==0)
{
styleSheet=doc.createStyleSheet();
}
else
{
styleSheet=doc.styleSheets[0];
}
styleSheet.addRule('body','color: black;');
styleSheet.addRule('body','font-family: Arial, helvetic, sans-serif;');
styleSheet.addRule('span.nodeName','font-weight: 700;');
styleSheet.addRule('ul.attributeList','color: #008;');
styleSheet.addRule('li.nodeValue','color: #080;');
styleSheet.addRule('*.missing','color: #888;');
gui.SetVisible(true);
OK, so this is a lot of stuff to take in, but the result is pretty powerful for just a script!
History
- 2nd February, 2007: Initial post

