Background
When I was developing an application for Pocket PC that used quite a large DataSet, I wondered where I could gain at least some bits of performance. I was filling some data to a tree view control, storing some data, doing selects from DataTable and getting the data from columns of DataRows. As you know, you can access the DataRow's columns by using either string indexing (dataRow["NAME"] or integer indexing dataRow[3]).
I thought I could test performance of both indexers - I just wanted to know if I could still use string indexers (they are more comfortable to work with) - or rework the code of this app to use integer indexing. So here comes the performance tester.
The Code
The approach to solve this problem was to create a large enough database (DataTable in my case), then in loops traverse the rows, and test the indexing itself. This is done by passing it as a parameter to a dummy function:
dummy(dataRow["STR1"]));
The DataTable's structure is as follows:
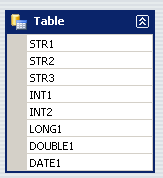
The columns are named by their data types, so STR1 is a string, INT1 an integer, DATE1 the DateTime, etc.
The program first generates user-entered number of rows, then n-times does integer indexing test and string indexing test. The indexing test m-times gets each row in table and calls dummy function on each column of that row.
There is a measuring - how long does it take to do the integer indexing test and the string indexing test.
In the end, the application writes out how much integer and string indexing take in total, and each one in average.
Example:
int indexing
total: 42171,875 ms
each: 421,71875 ms
string indexing
total: 149312,5 ms
each: 1493,125 ms
Conclusion
According to the tests on my machine (Intel Core2 Duo 1,86 GHz, 1 GB RAM), integer indexing is approximately 3.5 - 4 times faster than the string indexing (results vary according to row count and repetition count).
Clearly, integer indexing is faster, but when we take in account that both indexers take a very short time (about 1 µs) to access a column, the difference is noticeable only when applied on large amounts of data.
History
- 5th February, 2007: Initial post

