Contents
In this article (actually my first article in The Code Project), I will introduce you to db4o, one of today's most popular Object-oriented Database Management Systems (ODBMS).
But first, why should we need an ODBMS? Why can't we just use Relational Database Management Systems (RDBMS) such as Oracle and MS SQL Server? If you cannot answer these questions, I would suggest you to have a look at my two blog entries (see the Resources section) which attempt to explain object-relational mismatch, the impact it has on the object model, and provide an overview of ODBMS as well as its advantages and disadvantages in comparison with RDBMS.
Okay, I assume that you already understand the context in which ODBMS is useful, and are interested in learning about how to make use of one of them, let's get started.
db4o is an Open-Source native ODBMS available for both .NET and Java platforms. As a native ODBMS, the database model and application object model are exactly the same, hence, no mapping or transformation is required to persist and query objects with db4o. Regarding the usage mode, db4o can be deployed either as a standalone database or as a network database. Finally, db4o has support for schema evolution, indexing, transaction and concurrency, database encryption, and replication service (among db4o databases and certain relational databases). The latest version of db4o is 6.1, and is available under two licenses: GPL and a commercial runtime license.
While db4o's strengths are more obvious in applications with a highly complex object model, the purpose of this article is more to offer an introduction to db4o, instead of exploring it in every level of depth. As a result, I will use an object model which is very simple but still comprehensive enough to demonstrate the features of db4o.
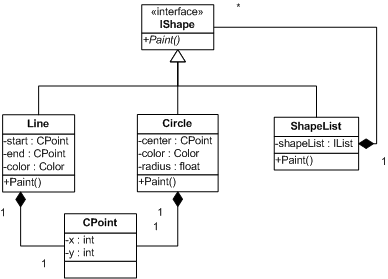
What we have is an object model for a painting application. There are two concrete shape types, Line, Circle, and ShapeList, which implement the IShape interface which has Paint() as its single method. The ShapeList implements the composite design pattern, and contains many instances of type IShape. The CPoint represents a 2-D coordination used by Line (start point and end point) and Circle (center point). (Yes, I know there is a System.Drawing.Point, but that Point is a struct, not a class, and since Line and Circle already consist of System.Drawing.Color which is a struct, it is better to have a custom Point class instead to see the differences in how db4o handles classes and structs.)
I will write code using C# 2.0. If you are from the Java space, you should still easily understand the code because the db4o libraries for the two platforms are virtually identical. Some notes about coding styles:
- I will use unit test cases to explore and validate the behaviors of db4o, instead of dumping the output to the console. I would love to hear whether this approach makes it easier to understand the code or not.
- I will try to explain the code by using as many comments embedded in the code as possible. That will eliminate much of the text I would have to write (and you would have to read) had I not written the comments, but will make the comments more elaborated than I, and possibly some of you, would expect to see in production code.
The first step we need to do is to download the binary of db4o from its website, and then in VS.NET 2005, add a reference to the Db4objects.Db4o.dll file which is located in the net-2.0 folder of the download.
Below is what the Solution Explorer looks like after we've added the references as well as created the source files needed. The source code of these model objects can be found in the source download of this article.
Okay, let's first create a new shape and store it into the database.
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
IShape circle = new Circle(new CPoint(1, 2), 5f);
container.Set(circle);
IObjectSet result = container.Get(typeof(Circle));
Assert.AreEqual(1, result.Count);
Assert.AreEqual(circle, result[0]);
Assert.AreSame(circle, result[0]);
}
What needs to be explained a bit is line 19 (see the ***Line 19*** comment). The retrieved object does not only have the same attributes as the original object, but it actually is the same object in memory (AreSame() uses == checking while AreEqual() uses Equals() checking). The reason is because the object container caches the references of all objects stored or retrieved in a session and thus may return the exact references if these objects are requested via a query (in this case, the call to IObjectContainer#Get(Type)). (By default, weak references are used, and thus these objects may be wiped out by the garbage collector if they are not referenced to in the application code - we can configure to use hard references instead, but this option may silently hold up memory). If the current object container is closed and the IObjectContainer.Get(Type) is called on a different object container, the call to AreEqual() will pass but the call to AreSame() will fail. This feature allows us to update objects without having to fetch them from the database as long as they are previously stored or retrieved in the same session, but can also be harmful at times if we forget about it, since we may happen to work with the local copy of an object while thinking that it, together with all its references, is from the database.
Now, let's create a more complex nested object:
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
Circle circle = new Circle(new CPoint(50, 20), Color.Pink, 20f);
ShapeList list = new ShapeList();
list.Add(circle);
list.Add(new Line(null, null));
container.Set(list);
}
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
IObjectSet result = container.Get(typeof(ShapeList));
Assert.AreEqual(1, result.Count);
ShapeList list = (ShapeList)result[0];
Assert.AreEqual(2, list.Count);
Circle circle = new Circle(new CPoint(50, 20), Color.Pink, 20f);
Assert.AreEqual(circle, list[0]);
}
Notice that I use two separate sessions, by opening and closing the object container twice, that is to avoid the problem in which the object retrieved is actually the one already existing in memory (if we happen to perform all calls in one session). The object stored, ShapeList, has several nested levels: first, it has an internal list IShape. Within this internal list is a Circle and a Line object which reference to some CPoint objects and Color structs. Because the Equals() implementation of Circle does compare its center, the assertions above show that the object and its children (and its children's children) are stored as expected. See how easy the inheritance tree and the nested objects are stored and retrieved with db4o?
Now, let's see how we can update objects already existing in the database. As already mentioned in the discussion about weak references, you need to have "live" objects (still in the db4o's references cache) by fetching them from the database or storing them in the same session, before being able to update them. We also use the IObjectContainer#Set() method to update objects.
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
Circle circle = new Circle(null, Color.Red, 0f);
container.Set(circle);
IObjectSet result = container.Get(typeof(Circle));
Circle storedCircle = (Circle)result[0];
storedCircle.Color = Color.Blue;
container.Set(storedCircle);
}
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
IObjectSet result = container.Get(typeof(Circle));
Assert.AreEqual(1, result.Count);
Assert.AreEqual(Color.Blue, ((Circle)result[0]).Color);
}
Now, try the same update, but this time we will update the CPoint instead of the Color, and see what happens.
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
CPoint point = new CPoint(10, 20);
Circle circle = new Circle(point, 0f);
container.Set(circle);
IObjectSet result = container.Get(typeof(Circle));
Circle storedCircle = (Circle)result[0];
storedCircle.Center.X = 30;
container.Set(storedCircle);
}
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
IObjectSet result = container.Get(typeof(Circle));
Assert.AreEqual(1, result.Count);
Circle storedCircle = (Circle)result[0];
Assert.AreEqual(30, storedCircle.Center.X);
}
The last assertion will fail, storedCircle.Center.X returns 10, not 30. How can this possibly happen? The answer has something to do with the concept of Update Depth. Imagine you have a highly nested object, e.g., a Person object with a list of friends, each of which has another list of friends. When updating the name of the root Person object, do you want to have all the hundreds of thousands of other friend objects persisted as well? Obviously not, you would want to have the exact objects which are modified stored. Since db4o currently does not have support for dirty-checking, it introduces the concept of Update Depth in order to allow application developers to control the level of references to be persisted with each update call. The default update depth is 1; thus in line 10 of the above example, only modifications made on the Circle's primary attributes (of type int, bool, struct etc.) are persisted while those made to the CPoint are not. That's why we see the CPoint still has the old value in the assertion on line 19.
However, note that if line 9 is replaced by the below statement, then the assertion will pass since CPoint is now a newly created object referenced to by the root (Circle), and db4o's will store it without applying the Update Depth rule.
storedCircle.Center = new CPoint(30, 20);
To make the code work as expected, we can either increase the Update Depth or turn on cascading update for a specific type or for the whole database, as shown in the code segment below:
container.Ext().Configure().CascadeOnUpdate(true);
container.Ext().Configure().ObjectClass(typeof(Circle)).CascadeOnUpdate(true);
container.Ext().Configure().UpdateDepth(2);
container.Ext().Configure().ObjectClass(typeof(Circle)).UpdateDepth(2);
The above code only modifies the setting of a specific container; we can also make the settings applied for all containers by calling the same methods in the IConfiguration instance returned by the call to the method Db4objects.Db4o.Db4oFactory.Configure().
Just like the update, you need to have "live" objects before being able to delete them. To delete an object, we simple call the IObjectContainer#Delete() method of the object container with the object to be deleted as the parameter.
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
Circle circle = new Circle(new CPoint(1, 2), 0f);
container.Set(circle);
container.Ext().Purge(circle);
IObjectSet result = container.Get(typeof(Circle));
Assert.AreEqual(1, result.Count);
container.Delete(result[0]);
Assert.AreEqual(0, container.Get(typeof(Circle)).Count);
}
In the above example, I use a different technique to make sure the object retrieved in line 9 is not the same in-memory object as the one stored in line 4; i.e., instead of closing the current session and opening another one for the retrieval, I use a call to the IObjectContainer.Ext()#Purge() method which will remove the object passed as parameter from db4o's internal reference management system. Now, the code above does show that the Circle object is deleted, but how about the CPoint object? Is it also deleted? Obviously, you and I would expect the CPoint object to be deleted when the Circle object is deleted since they have a composition relationship. However, let's think about association and aggregation relationships, in which the referenced objects still make sense regardless of the existence of the referencing objects (e.g., Album -> Song, Song -> Next Song etc.). Will we still expect the referenced objects to be deleted? The answer would be 'no' in most cases. Since db4o does not know about the relationship semantics of our object model, it cannot choose to delete every referenced object from the root object. In fact, the following assertion if added after line 12 would pass, since the CPoint object is not deleted although its container (Circle) is.
Assert.AreEqual(1, container.Get(typeof(CPoint)).Count);
In order to have CPoint deleted, we need to turn on the cascade delete option for a specific type or for the whole database, with the following calls:
container.Ext().Configure().CascadeOnDelete(true);
container.Ext().Configure().ObjectClass(typeof(Circle)).CascadeOnDelete(true);
The last point of interest regarding object deletion is that if there is an object in the database referenced to by more than one reference (in one or more objects) and that object is deleted, then all the references will be null when they are retrieved from the database. This maybe an unexpected behavior when we delete a parent object with cascade delete enabled just to find out later that the children objects are also deleted while they are referenced to by some other parent objects. The code segment below shows this unexpected behavior in action:
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
container.Ext().Configure().ObjectClass(typeof(Line)).CascadeOnDelete(true);
CPoint sharedPoint = new CPoint(99, 100);
Line line1 = new Line(sharedPoint, null);
container.Set(line1);
Line line2 = new Line(sharedPoint, null);
container.Set(line2);
container.Delete(line1);
}
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
IObjectSet result = container.Get(typeof(Line));
Assert.IsNull(((Line)result[0]).Start);
}
db4o exposes three different APIs for application developers to retrieve stored objects: they are Query-By-Example (QBE), Simple Object Data Access (SODA), and Native Query (NQ). These APIs differ in their ease of use and flexibility, as we will see shortly. Before going to details about each API, let's first talk about an important concept of db4o which applies to all query APIs: Activation Depth.
Think of the Person example mentioned in the discussion about cascade update; when we retrieve a person from the database, since this person may contain a reference to a list of friends, each of whom may contain another list of friends and so on, it is possible that we will pull out the entire database with one single call while what we really need is just one person. In order to avoid this problem, db4o controls the level of objects to be "activated" as part of a query via the Activation Depth setting. If the container is configured with an Activation Depth of 5 for a certain type, then when objects of that type are loaded from the database, only 5 levels of object references are "activated" (e.g., instantiated and populated with stored values), and the reference at the 6th level will not be "activated" (all attributes are set to their default values). Let's go through an example to demonstrate this point.
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
ShapeList list = new ShapeList();
list.Add(new Circle(new CPoint(50, 50), Color.Pink, 20f));
list.Add(new Line(new CPoint(10, 5), new CPoint(5, 10), Color.Purple));
container.Set(list);
}
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
container.Ext().Configure().ActivationDepth(2);
IObjectSet result = container.Get(typeof(ShapeList));
Assert.AreEqual(1, result.Count);
Assert.AreEqual(2, ((ShapeList)result[0]).Count);
Circle circle = (Circle)((ShapeList)result[0])[0];
Assert.IsNull(circle.Center);
Assert.AreEqual(Color.Empty, circle.Color);
Assert.AreEqual(0f, circle.Radius);
container.Activate(circle, 1);
Assert.IsNotNull(circle.Center);
Assert.AreEqual(Color.Pink, circle.Color);
Assert.AreEqual(20f, circle.Radius);
Assert.AreEqual(0, circle.Center.X);
container.Activate(circle.Center, 1);
Assert.AreEqual(50, circle.Center.X);
}
Since the default Activation Depth is 5, in line 11, we need to configure it to 2 in order to demonstrate the problem. With Activation Depth as 2, only the returned ShapeList object and its internal children list (of type IList<ishape>) are activated. The Circle and Line created in line 4 and line 5 will be loaded in the children list but not activated, thus their attributes are set with default values. The assertions in lines 21, 22, and 23 validate the fact that objects located further than the current Activation Depth are not activated. In lines 26 and 33, we use the IObjectContainer#Activate() method to tell db4o to activate the Circle and CPoint objects (i.e., populate them with actual values stored in the database).
The next few paragraphs will discuss about each of the query APIs supported by db4o. But first, let's populate the database with the following objects and write the query:
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
container.Set(new Circle(new CPoint(-5, 15), Color.Red, 10f));
container.Set(new Circle(new CPoint(20, 30), 0f));
container.Set(new Circle(new CPoint(100, 6), Color.Blue, 1f));
container.Set(new Circle(new CPoint(-10, -20), Color.Pink, 10f));
container.Set(new Line(new CPoint(5, 10), new CPoint(20, 30)));
container.Set(new Line(new CPoint(15, 0), new CPoint(-10, 5), Color.Pink));
container.Set(new Line(new CPoint(15, 0), new CPoint(5, 10), Color.White));
container.Set(new Line(new CPoint(0, 5), new CPoint(5, 10), Color.Green));
}
QBE is the most basic mechanism to query objects from db4o's databases. To look up objects, we would need to create an example (or template) of the kind of objects we want to retrieve by specifying the attributes, which are part of the search criteria, with specific valuesn while leaving the remaining attributes with their default values (null for reference type, null or "" for string type, 0 for numerical types, false for bool type, and whatever default values [returned by new()] for struct type). The result set will include objects which match all the specified criteria (AND matching). Let's fire up some QBEs:
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
IShape prototype = new Circle(null, new Color(), 0);
IObjectSet result = container.Get(prototype);
Assert.AreEqual(4, result.Count);
prototype = new Circle(null, new Color(), 10f);
result = container.Get(prototype);
Assert.AreEqual(2, result.Count);
prototype = new Line(new CPoint(15, 0), null, Color.Pink);
result = container.Get(prototype);
Assert.AreEqual(1, result.Count);
}
In the first query, we create a Circle template filled with default values, and the matches would obviously include all Circle objects in the database. This is actually the long version of the short-hand one we saw earlier (IObjectContainer#Get(typeof(Circle)). The second and third queries do populate some values to the templates' attributes, thus only objects matching the specified criteria are returned. So simple, right? Unfortunately, the simplicity of QBE comes as an expense to its flexibility. In fact, QBE is not sufficient to be used for certain querying tasks since it has the following problems:
- Attributes with default values are never included as part of the search criteria, so you cannot perform searches like "Find all lines with an empty color", or "Find all persons with age of 0" etc.
- Since the template is created by invoking the object constructor, any initialization done in the constructor may break the ability to perform searches by default values. For example if we happen to initialize the
Color of every Line object to Color.Black, then when we call IObjectContainer#Get() on an empty template (new Line(null, null, new Color()), we would only receive Lines which have their color as Black, instead of all Lines. - QBE cannot perform complex query expressions, such as "or", "not", "less than", and "greater than" etc. For instance, we cannot perform queries like "Find Circles whose radius is bigger than 10f", or "Find Lines whose Color is different from black" etc.
The basic idea behind SODA is that each query is represented as a graph which includes nodes (each represents a class, multiple classes, or an attribute) and constraints (criteria applied for each node). The querying engine will traverse these nodes and based on their constraints, select the objects to be returned as part of the result set. The SODA API allows application developers to build up query graphs and execute them. Let's say we are searching for "all circles whose center's X-coordinate is smaller than 100 and Y-coordinate is greater than 6, and radius is not 10", the SODA code will be written as follows:
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
IQuery rootNodeQuery = container.Query();
rootNodeQuery.Constrain(typeof(Circle));
IQuery pointXNode = rootNodeQuery.Descend("center").Descend("x");
pointXNode.Constrain(100).Smaller();
IQuery pointYNode = rootNodeQuery.Descend("center").Descend("y");
pointYNode.Constrain(6).Greater();
IQuery radiusNode = rootNodeQuery.Descend("radius");
radiusNode.Constrain(10f).Not();
IObjectSet result = rootNodeQuery.Execute();
Assert.AreEqual(1, result.Count);
Assert.AreEqual(new Circle(new CPoint(20, 30), 0f), (Circle)result[0]);
}
Note that in order to create the nodes, we need to specify the attributes' names ('center', 'y' etc.) and we need to modify the query code should we decide to change the objects' attribute names. By default, all the constraints are ANDed; if we need to write OR queries, we need to explicitly perform a call to the method Or() of the constraints. For example, if we want to modify our search as "Find all circles whose center's X-coordinate is (smaller than 100 and Y-coordinate is greater than 6) or (radius is not 10)", we would rewrite the code as follows (I removed the comments in the previous example for brevity):
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
IQuery rootNodeQuery = container.Query();
rootNodeQuery.Constrain(typeof(Circle));
IQuery pointXNode = rootNodeQuery.Descend("center").Descend("x");
IConstraint const1 = pointXNode.Constrain(100).Smaller();
IQuery pointYNode = rootNodeQuery.Descend("center").Descend("y");
IConstraint const2 = pointYNode.Constrain(6).Greater().And(const1);
IQuery radiusNode = rootNodeQuery.Descend("radius");
radiusNode.Constrain(10f).Not().Or(const2);
IObjectSet result = rootNodeQuery.Execute();
Assert.AreEqual(3, result.Count);
}
The call to IConstraints#And(const1) in line 11 is necessary; otherwise, SODA will understand our intention as "x is smaller than 100 AND (y is greater than 6 or radius is not 10)" and only two objects match (#1 and #2). SODA also supports other constraint types (via methods of IConstraint such as Identity(), Like(), Contains()), sorting of result sets, searching of array or collection types, and a flexible Evaluator API which allows developers to write code to check whether a candidate object should be included in the result set. In other words, unlike QBE, with SODA, you can do any kind of queries required for the application.
NQ API is an attempt by db4o creators to make queries as close and natural to the host programming languages as possible (as DLINQ). In the .NET implementation, NQ makes use of the System.Predicate delegate (definition is public delegate bool Predicate<T>(T obj)) to allow developers to write code to determine whether an object passed into that delegate should be included in the result set or not. Let's say we are searching for "all circles whose color is not blue and radius is less than or equal to 10", the NQ code will look like:
using (IObjectContainer container = Db4oFactory.OpenFile(DB_PATH))
{
IList<Circle> circles = container.Query<Circle>(delegate(Circle circle)
{
return (circle.Color != Color.Blue) && (circle.Radius <= 10);
});
Assert.AreEqual(3, circles.Count);
}
Very simple, right? We can also sort the result set by creating a System.IComparer and passing it as the second parameter of the IObjectContainer#Query<T>() method. In addition, it is also easy to see that by writing code to select a result set at the programming language level, we can write all kinds of queries just as SODA.
Some of you may notice that this API looks like all of the objects of a specific type must be loaded from the database, instantiated, and passed to the Predicate so that it can be checked against the search criteria, and this is very inefficient in terms of memory and performance. Fortunately, what db4o does internally is analyze the CIL of the Predicate delegate's body, building up ASTs (Abstract Syntax Trees), and translating them to SODA query graphs so that they can be executed just as any other SODA query. (Actually, at run-time, QBE queries are also translated to SODA queries, but that is a straight-forward translation process and no CIL inspection process is necessary). The bad news is that not all native queries can be optimized into SODA queries if they contain complex logic not supported by the optimizer (which is improved more and more with each release of db4o), and the worst case scenario is when all objects are instantiated for the query matching.
Having talked about all three db4o's query APIs, let's recap about when we should use which API type.
- Query-By-Example: due to QBE's limitations, it can only be used for very simple queries. Given the same query, I personally think that NQ is as simple as QBE yet expresses the code's intention much better, thus I would suggest NQ to be considered first, even for simple queries.
- Native Query: NQ can be used to perform all kinds of queries, no matter how complex they are, and at the same time, it is very expressive. In addition, type-safety is also a plus for NQ, in comparison with SODA, and I would recommend NQ to be used by default for all querying needs. Cases in which NQ needs to be avoided are when the SODA optimizer cannot translate native queries into corresponding SODA queries. Fortunately, db4o does expose the API for developers to check whether their native queries are successfully optimized or not so that they can either modify the queries or choose to use SODA instead.
- Simple Object Database Access: the least expressive of all three APIs, and should only be used when NQ cannot be optimized and its performance is not acceptable.
By now, I hope you have seen how easy and fast it is to write object persistence code with db4o. Unlike when developing applications with RDBMS, with db4o, there is no need to worry about inheritance, deeply nested classes, complex associations, primary and foreign keys, XML mapping files, SQL, HQL, or JDOQL etc. And while I have not touched many advanced features of db4o such as transaction, concurrency, networking database, and replication etc., I hope that I have provided enough information for you to start the discovery about this interesting product yourselves.
- The Legend of Data Persistence - Part 1: this blog entry describes the object-relational mismatch, the impact it has on the domain model, and briefly about how current ORM tools do not effectively resolve the mismatch.
- The Legend of Data Persistence - Part 2: this blog entry provides an overview of ODBMS as well as its advantages and disadvantages in comparison with RDBMS.
- db4o Developer Community Website: one of the biggest strengths of db4o is that it has a great community around it. In the developer forum, you can almost always find your questions already been asked and answered.
- db4o Tutorial: great resource to learn deeper about the topics discussed in this article.

