Background
This article follows on from the previous four Searcharoo samples:
Searcharoo 1 describes building a simple search engine that crawls the file system. A basic design and object model was developed to support simple, single-word searches, whose results were displayed ina rudimentary query/results page.
Searcharoo 2 focused on adding a 'spider' to find data to index by following web links (downloading files via HTTP and parsing the HTML). Also discusses how multiple search words results are combined into a single set of 'matches'.
Searcharoo 3 implemented a 'save to disk' function for the catalog, so it could be reloaded across IIS application restarts without having to be generated each time. It also spidered FRAMESETs and added Stop words, Go words and Stemming to the indexer.
Searcharoo 4 added IFilter support for non-text filetypes (eg Word, PDF and Powerpoint), better robots.txt support, a remote-indexing console application and a lot of code tidy-up (refactoring!).
Introduction to version 5
This article is shorter than most, covering just two topics:
- Allowing Searcharoo to run on websites where the ASP.NET application is restricted to Medium Trust. The remote-indexing console app in v4 was intended to addrsess this issue - but just building the catalog remotely isn't enough because you cannot binary-deserialize the file under Medium Trust. Rather than advise people to try and get the trust level on their server changed or customised (difficult!), the file format has been changed (to XML) to allow it to work in Medium Trust.
- Extend the
Document object hierarchy introduced in v4 to index Office 2007 (OpenXML) file types. I received a *.docx file from a collegue recently, and since I don't intended to upgrade to Office 2007 any time soon, it seemed like a good idea to investigate how the file could be indexed/searched without having the application/IFilter installed.
ASP.NET has 'Trust Issues'
When Searcharoo v4 is run under Medium Trust, you get one of these errors:
WebPermission denied if Search.aspx cannot find a catalog file and triggers SearchSpider.aspx (accessing websites or webservices is not allowed under Medium Trust by default).
[SecurityException: Request for the permission of type 'System.Net.WebPermission, System, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089' failed.]
System.Security.CodeAccessSecurityEngine.Check(Object demand, StackCrawlMark& stackMark, Boolean isPermSet) +0
System.Security.CodeAccessPermission.Demand() +59
System.Net.HttpWebRequest..ctor(Uri uri, ServicePoint servicePoint) +166
System.Net.HttpRequestCreator.Create(Uri Uri) +26
System.Net.WebRequest.Create(Uri requestUri, Boolean useUriBase) +373
System.Net.WebRequest.Create(String requestUriString) +81
Searcharoo.Indexer.RobotsTxt..ctor(Uri startPageUri, String userAgent) +250
Searcharoo.Indexer.Spider.BuildCatalog(Uri startPageUri) +116
SecurityPermission denied if Search.aspx finds a binary-serialized catalog file and tries to deserialize it (Binary Serialization is not allowed under Medium Trust).
[SecurityException: Request for the permission of type 'System.Security.Permissions.SecurityPermission, mscorlib, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089' failed.]
System.Runtime.Serialization.Formatters.Binary.ObjectReader.CheckSecurity(ParseRecord pr) +1644388
System.Runtime.Serialization.Formatters.Binary.ObjectReader.ParseObject(ParseRecord pr) +363
System.Runtime.Serialization.Formatters.Binary.ObjectReader.Parse(ParseRecord pr) +64
System.Runtime.Serialization.Formatters.Binary.__BinaryParser.ReadObjectWithMapTyped(BinaryObjectWithMapTyped record) +1050
System.Runtime.Serialization.Formatters.Binary.__BinaryParser.ReadObjectWithMapTyped(BinaryHeaderEnum binaryHeaderEnum) +62
System.Runtime.Serialization.Formatters.Binary.__BinaryParser.Run() +144
System.Runtime.Serialization.Formatters.Binary.ObjectReader.Deserialize(HeaderHandler handler, __BinaryParser serParser, Boolean fCheck, Boolean isCrossAppDomain, IMethodCallMessage methodCallMessage) +183
System.Runtime.Serialization.Formatters.Binary.BinaryFormatter.Deserialize(Stream serializationStream, HeaderHandler handler, Boolean fCheck, Boolean isCrossAppDomain, IMethodCallMessage methodCallMessage) +190
System.Runtime.Serialization.Formatters.Binary.BinaryFormatter.Deserialize(Stream serializationStream) +12
Searcharoo.Common.Catalog.Load() +461
The combination of errors -- cannot create a new catalog, and cannot load an existing catalog file (even if it was generated elsewhere) -- means that Searcharoo v4 doesn't work under Medium Trust. There are two options to fixing this problem:
- Update your server with a custom Code Access Security policy to allow the Searcharoo code to perform these functions. This could be very difficult if your site is on shared hosting and you need to convince the ISP to make changes 'just for you'.
- Make changes to Searcharoo so that at least one of those errors does not occur.
We'll do #2, since it's easier! There was a long discussion in v4 about why Binary Serialization was a good idea and Xml Serialization was bad: in this article we'll turn that around by fixing the problems with the Xml output so that we can build it remotely using the Indexer Console Application then uploaded to a Medium Trust website. Xml-serialized data can be de-serialized even under Medium Trust, so it can be loaded and searched.
About Option #2: Xml redux
Original (v4) Xml Catalog format
Way back in v4, the Xml-serialized Catalog object was dismissed as bloated, inefficient and (as implemented) unable to be de-serialized. It looked like this:
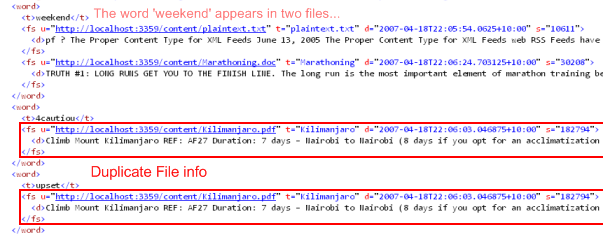
Recall that each Word object contains a collection (Hashtable) of File objects, indicating which File/s that Word appeared in. That works in memory because the File objects in Word._FileCollection are references - there's only one File 'object' per indexed file.
The problem with the resulting Xml is that the File object references are 'flattened out' (repeated every time they are referenced). You can see above that the document http://localhost:3359/content/Kilimanjaro.pdf is represented twice in the small excerpt. This repetition occurs for EVERY WORD in each File, creating a huge amount of redundant data in the Catalog file.
What's needed is a more succinct way to represent the relationship between Word and File: a 'foreign key' in database terms.
New (v5) Xml Format
This 'foreign key' will be represented by a new object CatalogWordFile, which will act as a 'proxy' for Word objects (which we will no longer serialize). The Word object will continue to be the basis of the Catalog, but when we load and save it via Xml Serialization, we will use attributes to ignore Word and treat the File and CatalogWordFile like two 'database tables' joined by a 'foreign key': the FileId.

Now the File objects are serialized once and their FileId is their implicit order in the serialized Xml (starting from zero, of course). The content we mentioned above - http://localhost:3359/content/Kilimanjaro.pdf - appears in the new Xml as FileId=2 (below) just once.
| | |
In the same Xml file the individual CatalogWordFile objects reference just the FileId, resulting in a significantly smaller Xml than when Word objects were used.
Repeating the Original (v4) Xml Catalog example, you can see the two words boxed above shown here again, with just the FileId rather than a whole serialized File object. |
Note that the markup shown still has some complete element names; in the actual code the element names are overridden to further reduce the Xml file size using attributes: [XmlElement("w")] and [XmlElement("f")] (see right).
The test data used during development created a 178 Kb file when Binary Serialization was used. This equated to a 1.1 Mb Xml file in the old format.
Using the new, improved Xml format, the file shrunk to 194 Kb; and after applying XmlElement attributes to shorten the element names shrunk even further to 97 Kb - actually smaller than the Binary version.
| | |
Behind the Xml-serialization Scenes
So that's the Xml format we need - how do we get it? Unfortunately, just replacing the Word[] with CatalogWordFile[] isn't all we needed to do to make this work. The FileId needs to be 'in-sync' between the CatalogWordFile and File arrays, but we don't really know what order the XmlSerializer will access the properties (nor whether they'll be accessed multiple times). To avoid having to populate the internal CatalogWordFile collection unnecessarily, we use pre/post methods in the Property accessors to create it on-demand.
The two property declarations look like this (below): the PrepareForSerialization() does the work of 'flattening' the _Index Hashtable of Word objects into CatalogWordFile proxies with FileIds, it's called in both get accessors to ensure they return the 'synchronized' collections.
The PostDeserialization() method waits until both File and WordFile set accessors have been called (because we need both collections to re-build the original _Index via our 'foreign key'), then loops through the data and calling the Add() method just like the Spider does when it builds the Catalog while indexing.
If you check the Catalog.Load() code, you'll also notice the XmlSerialization uses the Kelvin generic serialization helper (another CodeProject article).
Catalog c1 = Kelvin<Catalog>.FromXmlFile(xmlFileName);
One final note: rather than remove the Binary Serialization feature, both methods are still available, controlled by a new web.config/app.config setting (for your Website and Indexer Console application).
<appSettings>
<add key="Searcharoo_InMediumTrust" value="True" />
</appSettings>
If set to
True, the Catalog will be saved as an Xml file, if set to
False it will be written as *.dat. Don't forget to update the other .config file settings to match your environment - including the
Searcharoo_VirtualRoot, Searcharoo_CatalogFilepath and
Searcharoo_TempFilepath which will be used in the
DownloadDocument class discussed in the remainder of this article...
More on Trust & Code Access Security
Office 2007 File Formats
The rest of the article discusses indexing the new Office 2007 file formats.
Microsoft Word Docx file 'structure'
This blog on getting started with OpenXML discusses how to use the Open XML File Formats. It explains the basic structure of OpenXML documents: they are actually a series of related Xml (and other) files, 'hidden' inside a single ZIP file with an Office 2007 file extension like docs, xlsx, pptx, etc).
A Microsoft Word 2007 file looks like this 'inside' the ZIP:
You can read all about the details of the format in the references, but the key file we're interested in is the document.xml part. To search it, we'll need to do the following steps:
- Download the OpenXML file/ZIP archive from the web link
- Extract the file we need from the ZIP archive
- Learn a bit about the Xml format so we can extract the plaintext we want to index, and ignore all the formatting and other data.
Step 1: Subclassing Document to share download code
The v4 article describes how the FilterDocument needed to download files for IFilter processing (whereas previously downloads were loaded into/parsed from a MemoryStream). The new Office 2007 classes need the same behaviour, so the SaveDownloadedFile method is pushed up to a superclass they can all implement.
Step 2: unZIP
The System.IO.Packaging API in .NET 3.0 provides built-in capabilities for accessing ZIP archives (some might say specifically to facilitate Office 2007/OpenXML interoperability). However, to keep Searcharoo accessible we're not going to upgrade to 3.0 just yet; luckily the System.IO.Compression namespace in .NET 2.0 contains the building blocks needed to build a ZipFile implementation that reads/writes ZIP files (and therefore also OpenXML documents).
Using the ZipFile to access a data stream to process is easy:
using (ZipFile zip = ZipFile.Read(filename))
{
using (MemoryStream streamroot = new MemoryStream())
{
MemoryStream stream = new MemoryStream();
zip.Extract(@"word/document.xml", streamroot);
stream.Seek(0, SeekOrigin.Begin);
}
}
Step 3: Extract text
Turns out the Word 2007 OpenXML format is very Html-like in it's treatment of formatting and content: all document structure and formatting present in document.xml is contained in Xml attributes and the relevent plaintext in the InnerXml of each element. For our purposes, we'll assume that's all the text we wish to index (more research is required to determine whether headers/footers/tables/references are included, and more work would be required to detect and index other embedded Office documents).
DocxDocument in 3 easy steps
The new Docx file indexer inherits most of it's functionality from the abstract Document and DownloadDocument classes. All we really need to do is override the GetResponse() method to extract the file contents and set the WordsOnly property which is used to generate the Catalog.
This same pattern can be easily applied to PowerPoint 2007 (.pptx files) and Excel 2007 (.xlsx files) - see the XlsxDocument and PptxDocument code for the additional work that was required to loop through sheets/slides to get all the text in those file types.
Lastly, our new classes will never be instantiated unless we update DocumentFactory to be aware of the new MIME types we can 'handle', and which MIME type/file extension maps to which class.
More on Open XML Office Formats
Erika's blog is an excellent source of
Office 2003 and 2007: MSDN Technical Articles, How-To Content, and Code Samples. Other links include:
Wrap-up
These additions to Searcharoo are quite minor, and have been posted mainly to help anyone wishing to use the code under Medium Trust. Many users may have Office 2007 installed (or the relevent IFilter on their server) and may not even need the additional Document subclasses - if this is the case, simply remove the new case statements from DocumentFactory and let the existing FilterDocument direct the Indexer.
History
- 2004-06-30: Version 1 on CodeProject
- 2004-07-03: Version 2 on CodeProject
- 2006-05-24: Version 3 on CodeProject
- 2007-03-18: Version 4 on CodeProject
- 2007-04-29: Version 5 (this page) on CodeProject

