Introduction
This is a simple and lightweight modification to the XmlTextReader and Microsoft's SgmlTextReader that simply adds position tracking in the form of an XPath expression. The objective is to extract data from a website without using regular expressions or creating an XmlDocument in memory.
Background
I've been doing quite a bit of screen-scraping work over the years. I've noticed that every time I started working on a new project, I would abandon my existing code and decide to re-write it. Over time, I've experimented with various tag balancers, DOM vs. pull parsers, etc.. I've tracked the position in the document using everything from nested if statements and boolean variables to stacks. The resulting code was difficult to debug and painful to maintain (i.e., when the site template changes).
The solution I present here is based on XML pull parsing (i.e., Readers), uses a stack (sort of) to track position, and exposes that position in the form of an XPath expression. The XPath expression is correct; however, it is not namespace aware, it is not the minimal expression, it does not match attributes (once you find the element, you can get the attributes easily enough), and it may match more than one section of the document. The first is because I'm lazy, and the others are in the interest of speed and simplicity. For example:
While you might like to get this:
id('featured1ct')/span/h3/a
...or this
You get one or more of these instead
...quickly
If you are only concerned with a particular occurrence of a matching document fragment, you will need to count how many times it's matched on your own.
I am aware that there is an XPathReader project out there, and I have played around with it. It offers a powerful solution for extracting data, but without even looking at the code, I can tell you that it's doing a lot more work behind the scenes than is necessary for most simple screen scraping jobs, and it's got a larger memory footprint. Given the one-way nature of Readers, you still have to be careful about ordering your expressions with respect to the structure of the document. And finally, unless I'm missing something, there's no easy way to attach two readers together. In other words, I couldn't find a way to get the SgmlReader to feed directly into the XPathReader without dumping the output into a MemoryStream first. If you really need to match one of the first few expressions, go with the XPathReader. Otherwise, you're in the right place.
The code
The FastSgmlXPathReader and FastXPathReader are intended for HTML and XML documents, respectively. The implementation differs slightly, but the end result is the same.
The FastSgmlXPathReader (for HTML)
using System;
using System.Collections.Generic;
using System.Text;
using Sgml;
using System.Windows.Forms;
using System.Xml;
namespace FastXPathReader {
public class FastSgmlXPathReader : SgmlReader {
private List<string> PositionTracker = new List<string>();
private StringBuilder XPathBuilder = new StringBuilder();
public override bool Read() {
bool Value = base.Read();
if (Value && base.NodeType == XmlNodeType.Element) {
while (PositionTracker.Count > this.Depth) {
PositionTracker.RemoveAt(PositionTracker.Count - 1);
}
if (this.Depth != PositionTracker.Count) {
PositionTracker.Add(this.Name);
} else {
PositionTracker[PositionTracker.Count - 1] = this.Name;
}
}
return Value;
}
public string XPath {
get {
XPathBuilder.Length = 0;
XPathBuilder.Append("/");
for (int i = 0; i < PositionTracker.Count; i++) {
XPathBuilder.Append("/" + PositionTracker[i]);
}
return XPathBuilder.ToString();
}
}
public FastSgmlXPathReader() : base() { }
}
}
The FastXPathReader (for XML)
using System;
using System.Collections.Generic;
using System.Text;
using System.Xml;
using System.IO;
namespace FastXPathReader {
public class FastXPathReader : XmlTextReader {
private List<string> PositionTracker = new List<string>();
private StringBuilder XPathBuilder = new StringBuilder();
public override bool Read() {
bool Value = base.Read();
if (Value) {
if (base.NodeType == XmlNodeType.Document ||
base.NodeType == XmlNodeType.Element) {
if (PositionTracker.Count < this.Depth ||
this.Depth == 0 || PositionTracker.Count == 0) {
PositionTracker.Add(this.Name);
} else {
if (PositionTracker.Count == 0) {
} else if (PositionTracker.Count > this.Depth) {
PositionTracker[PositionTracker.Count - 1] = this.Name;
} else {
PositionTracker.Add(this.Name);
}
}
} else if (base.NodeType == XmlNodeType.EndElement) {
if (PositionTracker.Count > 1) {
PositionTracker.RemoveAt(PositionTracker.Count - 1);
}
}
}
return Value;
}
public string XPath {
get {
XPathBuilder.Length = 0;
XPathBuilder.Append("/");
for (int i = 0; i < PositionTracker.Count; i++) {
XPathBuilder.Append("/" + PositionTracker[i]);
}
return XPathBuilder.ToString();
}
}
public FastXPathReader(Stream input) : base(input) {}
public FastXPathReader(string url) : base(url) {}
public FastXPathReader(TextReader input) : base(input) { }
protected FastXPathReader(XmlNameTable nt) : base(nt) { }
public FastXPathReader(Stream input, XmlNameTable nt) : base(input, nt) { }
public FastXPathReader(string url, Stream input) : base(url, input) { }
public FastXPathReader(string url, TextReader input) : base(url, input) { }
public FastXPathReader(string url, XmlNameTable nt) : base(url, nt) { }
public FastXPathReader(TextReader input, XmlNameTable nt) : base(input, nt) { }
public FastXPathReader(Stream xmlFragment, XmlNodeType fragType,
XmlParserContext context) :
base(xmlFragment, fragType, context) { }
public FastXPathReader(string url, Stream input,
XmlNameTable nt) : base(url, input, nt) { }
public FastXPathReader(string url, TextReader input,
XmlNameTable nt) : base(url, input, nt) { }
public FastXPathReader(string xmlFragment, XmlNodeType fragType,
XmlParserContext context) :
base(xmlFragment, fragType, context) { }
}
}
Using the code
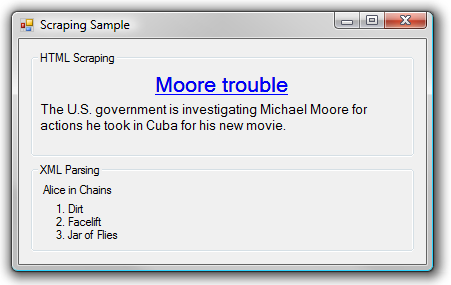
I provide two samples. The first scrapes the headline and description of the top story on yahoo.com, and the second extracts the top three albums for a band (Alice in Chains in the example) from Last.fm's Audioscrobbler webservice. The former demonstrates scraping an unbalanced HTML document, while the latter provides a fast and easy way to get data out of an XML document.
In both cases, you just loop through Read() statements on the Readers and do a 'switch' on the XPath property I've added to the Readers to find the XPath you're looking for.
The Yahoo Example (HTML)
HttpWebRequest Request = (HttpWebRequest)
HttpWebRequest.Create("http://www.yahoo.com/");
Request.UserAgent = "Mozilla/5.0 (Windows; U; Windows NT 6.0;" +
" en-US; rv:1.8.1.3) Gecko/20070309 Firefox/2.0.0.3";
using (HttpWebResponse Response = (HttpWebResponse)Request.GetResponse()) {
using (FastSgmlXPathReader SgmlReader = new FastSgmlXPathReader()) {
using (StreamReader InputStreamReader =
new StreamReader(Response.GetResponseStream())) {
SgmlReader.InputStream = InputStreamReader;
SgmlReader.DocType = "HTML";
bool AllDone = false;
while (!AllDone && SgmlReader.Read()) {
if (SgmlReader.NodeType == XmlNodeType.Element) {
switch (SgmlReader.XPath) {
case "//html/body/div/div/div/div/div/div/div/div/span/span/h3/a":
string Url = "http://www.yahoo.com/" + SgmlReader["href"];
lnkHeadline.Text = SgmlReader.ReadInnerXml();
lnkHeadline.Links.Add(0, lnkHeadline.Text.Length, Url);
break;
case "//html/body/div/div/div/div/div/div/div/div/span/span/p":
string Details = SgmlReader.ReadInnerXml();
lblDetails.Text = Details.Substring(0, Details.IndexOf('<'));
AllDone = true;
break;
}
}
}
}
}
}
And the Last.FM example (XML)
Request = (HttpWebRequest)HttpWebRequest.Create("http://ws.audioscrobbler.com" +
"/1.0/artist/Alice+In+Chains/topalbums.xml");
Request.UserAgent = "Mozilla/5.0 (Windows; U; Windows NT 6.0; " +
"en-US; rv:1.8.1.3) Gecko/20070309 Firefox/2.0.0.3";
int i = 0;
using (HttpWebResponse Response = (HttpWebResponse)Request.GetResponse()) {
using (FastXPathReader XPathReader =
new FastXPathReader(Response.GetResponseStream())) {
bool AllDone = false;
while (!AllDone && XPathReader.Read()) {
if (XPathReader.NodeType == XmlNodeType.Element) {
switch (XPathReader.XPath) {
case "//topalbums":
lblArtist.Text = XPathReader["artist"];
break;
case "//topalbums/album/name":
i++;
if (i == 1) {
lbl1.Text = "1. " + XPathReader.ReadInnerXml();
} else if (i == 2) {
lbl2.Text = "2. " + XPathReader.ReadInnerXml();
} else if (i == 3) {
lbl3.Text = "3. " + XPathReader.ReadInnerXml();
} else {
AllDone = true;
}
break;
}
}
}
}
}
As you can see, it's fairly painless to get the data out, whether its HTML or XML you're dealing with. The bulk of the work is just setting up the WebRequests and getting the response stream. Notice that you're reading XmlNodes directly out of the HttpWebResponse on-the-fly without any intermediate storage.
Points of interest
While the FastSgmlXPathReader should work fine on XML documents, you should always use the FastXPathReader instead when you know the document is well formed (in the interest of performance).
It was interesting to discover that the same code didn't work for the FastSgmlXPathReader and the FastXPathReader, seeing as they both essentially operate in the same way. I spent a few hours trying to figure out why they behave differently, and ultimately just decided to make them both work the same. I suspect it has something to do with the SgmlReader creating elements on-the-fly and how that does or does not affect the subsequent Read() operations. If anyone has any insight, I'm all ears.
If you run into any problems using the SGML parser itself (i.e., entity issues), you'll have to do some digging. I don't have anything to do with that project.
Possible performance enhancements
I realize that the XPath property code could be more efficient. I had considered abandoning the stack (List<string>) altogether and trimming and appending to the StringBuilder by scanning for the last position of the /. I'm open to your suggestions.
Resources
I'd link to the GotDotNet workspaces, but it looks like GotDotNet's on the way out.
History
- May 10, 2007: Initial release.

