In this article, I will try to introduce Memory Model in the context of .NET platform. This piece of writing is also meant to be a starting point for a series of articles about lock-free synchronization techniques, where understanding memory model issues is a must.
.NET Framework 4.0 comes with a set of new, out of the box thread safe collections like ConcurrentStack, ConcurrentQueue, ConcurrentDictionary or ConcurrentBag. Their availability together with Task Parallel Library (TPL) creates completely a new experience for implementing scalable and parallel algorithms with .NET platform. One may ask why these collections were added so late, why they were not added in .NET Framework 2.0 together with synchronization primitives. From my point of view, these collections alone don't represent any big value, the real added value to .NET platform is TPL. I mentioned them here because there is something very interesting in their implementation. As described in Microsoft paper [Chunyan], new collections are more efficient when compared to thread-safe collections with synchronization based on monitors, or simply "lock" keyword. This is because new collections are implemented in a bit tricky and arcane technique called "lock-free synchronization". Unfortunately, regardless their performance boost, they won't save your programs from bottlenecks, but possibly they will postpone noticing them a bit in a time.
Writing scalable, high performance and parallel logic is not as simple as most developers would like it to be. Suppose you have to solve some variation of a classic producer-consumer problem. One of the obvious solutions is to share thread safe collection between producers and consumers. In this solution, producers are populating shared collection, whereas consumers are simply emptying it. Unfortunately, this works well only for small problems, because above some number of cooperating threads time spend on synchronization can overtake actual producing (consuming) time. Optimal number of threads usually depend on the amount of time spent in the real logic for producing and consuming, but also how efficient the shared thread safe collection is implemented. [Chunyan] presents the following comparison of scalability for blocking and non-blocking collection in a pure producer-consumer problem.
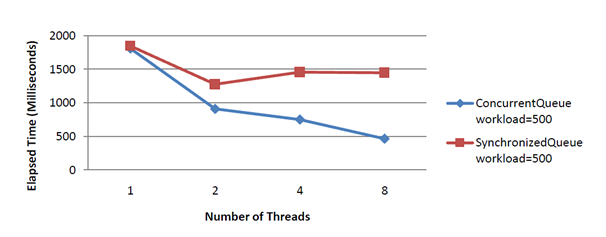
What's interesting here is that producer-consumer problem with single blocking collection loses scalability for more than two threads. This diagram clearly proves that using better collection can help, but somebody should ask, what would happen with larger number of threads, i.e., 16. My expectation is that above some number of threads, lock-free collections will also lose their scalability. For highly scalable producer-consumer problem, we need better communication algorithm between cooperating threads, not more efficient shared thread-safe collection.
The aim of this article is to take a closer look at the locking free synchronization techniques in the context of .NET platform. This will deepen the reader's understanding of concurrent programming, but it will also show why writing correct locking free synchronization is very difficult and in general language dependent. Blocking synchronization relies on synchronization primitives, provided by the language itself, whereas locking-free synchronization heavily relies on platform's memory model details. The difference becomes important when we notice that standard synchronization primitives are similar in all languages, whereas the gap between memory models for different languages can be significant.
Memory Model
Before giving memory model formal definition, let us consider some examples to feel it first. As a starter, consider Dekker's example:
class DekkersExample
{
static int A = 0;
static int B = 0;
static int r1, r2;
public static void Thread1()
{
r2 = A;
B = 1;
}
public static void Thread2()
{
r1 = B;
A = 2;
}
}
In the code above, two variables A and B are shared between two threads. Is it possible to observe r2 == 2 and r1 == 1 at the end? At first, it seems to be obvious that at least one of the instructions 9 or 16 needs to be executed, before any of the assignments to A or B can be done in instructions 10 or 15, so the answer is no. Not so fast, section 12.6.4 in [ECMA-335] states:
An optimizing compiler is free to reorder side-effects and synchronous exceptions to the extent that this reordering does not change any observable program behaviour.
Note that compiler doesn't know anything about concurrent threads, that is it can reorder Thread1 instructions as long as there would be no "observable change of program behaviour", e.g. when compiling Thread1 procedure, the compiler may decide that the following instructions order is for some reason more efficient.
public static void Thread1()
{
B = 1;
r2 = A;
}
In this example, from the compiler's point of view, it doesn't matter which of the instructions should be executed first, because they are independent, so their reordering won't change anything. Now suppose the compiler also reordered instructions when compiling Thread2, given this assumption, it becomes visible that the following execution path is also possible:
| Thread1 | Thread2 |
| B = 1; | |
| | A = 2; |
| r2 = A; | |
| | r1 = B; |
Which leads to result r2 == 2 and r1 == 1.
This basic example shows that concurrent programming is not as predictable as humans would like to see it. Obviously, somebody could argue why compilers are at all allowed to change instructions order, why they don't translate it to assembly code exactly as written by programmer. The reason is simple, performance. The developer should be focused on a high level optimization and readability of his code, whereas low level optimization should be left for compiler and processor. As long as the developer is writing single threaded code, he doesn't have to worry about instructions reordering and other optimizations, because these by definition should not make any "observable change of program behaviour", but as soon as developer starts to write concurrent code, he should be at least aware of the possible changes to his code. These "possible modifications" are specified as a memory model which for a program and an execution trace of that program, decides whether the execution trace is a legal execution of the program.
According to [JSR-133]
The memory model describes possible behaviours of a program. A compiler is free to produce any assembly code it likes, as long as all resulting executions of a program produce a result that can be predicted by the memory model. This provides a great deal of freedom to perform a myriad of code transformations, including the reordering of actions and removal of unnecessary synchronization.
It's a bit of shame that as confirmed by Joe Duffy in [DuffyMM], Microsoft didn't yet specify any formal memory model for .NET platform. ECMA standard [ECMA-335] describes CLI memory model in roughly few pages of informative text, which leaves a lot of freedom to do optimizations, but also lacks any precise contracts of what is allowed and what is not.
To get a better picture, how understanding platform's memory model is important for parallel programming, consider the following code:
class DataRace
{
class DataItem
{
public int x;
}
static DataItem s1 = new DataItem() { x = 0 };
static DataItem s2 = new DataItem() { x = 0 };
static bool isReady = false;
static void Thread1()
{
DataItem r1 = s1;
int r2 = r1.x;
DataItem r3 = s2;
int r4 = r3.x;
while(!isReady);
int r5 = r1.x;
}
static void Thread2()
{
DataItem r6 = s1;
r6.x = 3;
isReady = true;
}
}
Without instructions reordering, is it possible that at the end we may observe r2 == r5 == 0? At first, it seems to be impossible, because before assignment to isReady, Thread2 changes value of r1.x to 3.
Consider the following optimization:
static void Thread1()
{
DataItem r1 = s1;
int r2 = r1.x;
DataItem r3 = s2;
int r4 = r3.x;
while(!isReady);
int r5 = r2;
}
Here, the compiler decided that getting value from local variable r2 is cheaper than getting it from global variable's field. Optimization seems to be correct because when considering Thread1 alone, it won't change its "observable behaviour". Unfortunately, the developer might be surprised that new value assigned in Thread2 will never be picked up in Thread1.
If you try to compile this program under VS2010 and disassembly it via MSIL Disassembler (Ildasm.exe), you will find out that VS compiler is not performing this kind of optimization, but as pointed out in [JSR-133], the Java compiler will probably do it. This means that memory model for .NET is stronger than Java's, because it gives more guarantees for preserving original code layout. Here, stronger means more developer friendly, but also potentially less efficient, due to constraints on possible low level optimizations. This conclusion is confirmed in [DuffyConcProg].
Lock-free Stack Implementation
To see how lock free programming can be tricky, consider the following thread safe stack implementation:
public class LockFreeStack<T>
{
class Node
{
public T value;
public Node next;
}
private Node m_head;
public bool TryPop(out T result)
{
Node head = m_head;
while (head != null)
{
if (Interlocked.CompareExchange(ref m_head, head.next, head) == head)
{
result = head.value;
return true;
}
head = m_head;
}
result = default(T);
return false;
}
public void Push(T item)
{
Node node = new Node() { value = item };
Node head;
do
{
head = m_head;
node.next = head;
} while (Interlocked.CompareExchange(ref m_head, node, head) != head);
}
}
Here, stack is implemented as a linked list of Node instances, where push and pop methods operate on the head of the list. Notice that pointer to stack's head is assigned via Interlocked.CompareExchange, not via direct assignment. CompareExchange reads pointer stored in m_head, compares it to the pointer stored in head, and if it finds them to be the same, it assigns new value to m_head and what is important is it does all these steps in an atomic manner. Combining compare and swap into one atomic CAS operation is very important here, because it prevents data race when assigning new pointer to the m_head variable. Generally speaking, atomic CAS operations are the corner stone for lock-free synchronization.
Push method tries to insert new node at the head of the linked list. Implementation is lock free, because it is based on the optimistic concurrency control technique, that is push method optimistically assumes it will have no problems with updating m_head variable to a new head pointer and if in the mean time, m_head value has been changed by other thread, it will just try one more time, ultimately sooner or later it should succeed.
In TryPop method, access to m_head is synchronized in a similar way. The method will return false if at some point algorithm notices that m_head points to null, which simply means empty stack. The only synchronization is required when the head node is being removed and shared m_head variable needs to be updated to point to the next node in the list.
Intuitively this seems to work, but to prove stack correctness, we have to check whether is it affected by ABA problem and whether it can lead to a live lock.
ABA problem in short can be described as a lock free synchronization fault. I will describe it on example. Suppose the stack above contains nodes "A"->"B"->"C" and one thread was suspended in the TryPop method right before CAS operation, this means that head variable is holding reference to the "A" node. Now suppose that the other thread completed TryPop operation two times, so it removed "A" and "B". In this configuration, ABA problem will occur if in some way it is possible to insert "A" node right before the first thread will start its CAS operation, because then the first thread will insert "B" as a head of stack. Clearly, this is not possible; because Push method on each call creates new Node instance and address for "A" node cannot be reused here because its reference is still held by the first thread in head variable.
Live lock is also a kind of synchronization fault, but of a more subtle nature. Like in synchronization algorithms based on locking primitives, it is possible to hit deadlock, when two or more threads are waiting for each other to release locks; in lock free algorithms, it is possible to hit live lock, where two or more threads cannot move forward. For the stack above, live lock can occur in the loop in "Push" method, if for some reason CAS operation will always return false, that is, if it will never be able to update stack's head variable, "Push" method will never complete. Luckily, the above implementation is very simple, because CAS operations are performing synchronization for only one variable m_head. It is very easy to see that with more than one thread, one of them will be able to make progress, preventing live lock.
At first look, this collection seems to be properly synchronized. I was not able to break it on a one processor machine with many threads simultaneously accessing shared stack. Unfortunately, this stack may not work on a multiprocessor machine, because new value assigned to m_head variable by one processor doesn't have to be instantly visible by all other processors. This is mainly due to processor memory cache to reduce average time to access memory. Suppose collection is shared between two threads, where each of them is executed on a different processor. Probably to reduce memory access time, each CPU will operate on a copy of m_head variable in its cache, not directly on the "real" memory location represented by m_head. This can potentially lead to the situation where each processor will "see" different value of the m_head variable! What we need here is to somehow obligate processor to operate directly on the m_head variable stored in the global memory, not in its private cache. In C#, this can be achieved by marking shared variable declarations with volatile keyword.
class Node
{
public T value;
volatile public Node next;
}
volatile private Node m_head;
This implementation is pretty close to the ConcurrentStack in .NET Framework 4.0, we only need few "implementation details" changes; see [DuffyReusePattr].
Memory Barriers
Volatile keyword forces processor's cache refresh by generating special memory barrier instructions called fences before/after every load/store operations on a variable marked with volatile keyword [DuffyFence]. This is important to make sure that each reading variable value fetches its current value from global memory, not from processor cache. Similar memory barriers are generated with blocking synchronization primitives, with a difference that these will trigger refreshing whole processor's cache, like with "lock" in the example below:
Object privateLock
public void Push(T item)
{
Node node = new Node() { value = item };
lock (privateLock)
{
node.next = m_head;
m_head = node;
}
}
This example leads to a conclusion that using volatile keyword is not needed when using blocking synchronization primitives, even in multiprocessor execution environment, because in this case, all low level synchronization details are leaved to compiler and .NET Framework. Generally speaking, algorithms for synchronization based on blocking primitives are more intuitive, less error prone and less platform dependent when compared to lock free synchronization techniques. Unfortunately, the trade-off for simplicity is the overall lower performance.
Processors Memory Model
Virtual machine is not only an abstraction layer over operating system, so that the developer doesn't need to worry about different operating system APIs, it is also an abstraction layer over processor architecture.
Comparison for possible instructions reordering for the same memory location between two Intel's processors x86 and IA-64 can be summarized by the following table (taken from [DuffyConcProg]):
| | Load, Load | Load, Store | Store, Load | Store, Store |
| x86 | In some cases | Not allowed | Allowed | Not allowed |
| IA-64 | Allowed | Allowed | Allowed | Allowed |
x86 specification generally doesn't allow any reordering beside (store, load), which needs to be allowed due to pervasive use of processor's cache.
Logic written in C# or Java is expected to work on IA-64 processors in exactly the same way as on x86, regardless of processor memory model weakness. IA-64 is an example of very weak memory model where by default all instructions can be reordered by processor and a compiler is responsible for emitting fence instructions to prevent invalid reordering. This means that the C# IA-64 compiler emits appropriate fence instruction for every (load, load), (load, store) or (store, store) instructions pair which effectively force Itanium processor to work in x86 memory model.
In reality, as admitted in [MorrisonMM] when Microsoft has been writing VM for IA-64, it realized that most of the developers in .NET platform implicitly relied on guarantees provided by strong x86 memory model and their logic would nondeterministically fail when run on the weak IA-64 memory model. What they come up with was simply to force x86 memory model on the Itanium processor via memory fences. Obviously, this made .NET programs work, but it didn't reuse all possibilities of the new processor.
Processor architecture abstraction is a very important feature of a programming language. This was not so visible, when the only popular architecture was x86, but now even .NET Framework applications are expected to run on desktop computers as well as on various mobile phones using ARM RISC processors [WinEmb].
Note that fine-grained description of memory models for processors is out of scope for this article. If you are interested in details, please refer to the appropriate white paper, like [IntelMM] for x86.
Now that we introduced memory models for processors, it is possible to compare above described memory models described above on a chart comparing their strength (taken from [DuffyConcProg]):

Sequential Consistency
Sequential Consistency represents the strongest possible memory model, following [JSR-133] I will define it as:
Sequential consistency is a very strong guarantee that is made about visibility and ordering in an execution of a program. Within a sequentially consistent execution, there is a total order over all individual actions (such as reads and writes) which is consistent with the order of the program. Each individual action is atomic and is immediately visible to every thread.
From a perspective of programming simplicity, this is the best memory model, unfortunately the trade off here is paid in overall performance. x86 is a little weaker than sequential consistency, because it allows (store, load) to be reordered, although it still preserves intuitional consistency. Although .NET depends on x86 processor memory model, it is weaker than x86 because it applies compilation optimization. Generally speaking, the same goes for Java, but it defines its memory model in more formal, precise way, explicitly allowing for more optimization when compared to .NET. Finally, none of the presented languages is able to fully reuse possibilities of IA-64 architecture.
.NET Memory Model
Following [DuffyMM], I will describe effective .NET memory model as the following set of rules:
- Rule 1: Data dependence among loads and stores is never violated.
- Rule 2: All stores have release semantics, i.e., no load or store may move after one.
- Rule 3: All volatile loads are acquire, i.e., no load or store may move before one.
- Rule 4: No loads and stores may ever cross a full-barrier (e.g.,
Thread.MemoryBarrier, lock acquire, Interlocked.Exchange, Interlocked.CompareExchange, etc.). - Rule 5: Loads and stores to the heap may never be introduced.
- Rule 6: Loads and stores may only be deleted when coalescing adjacent loads and stores from/to the same location.
From my understanding, rule number 1 is required for preserving "observable changes in behaviour" as defined in ECMA specification.
Rules 2, 3, 4 are required to preserve transparency when writing synchronization algorithms based on locking primitives. With their enforcement in CLR, a developer doesn't need to know a lot about low level programming details like fences or processor cache to write correct parallel algorithms.
Rule 3 is also essential for proving lock-free algorithms correctness.
Rule 5 and 6 reserve some space for compiler optimizations.
Summary
Detailed knowledge about memory model is only necessary when designing lock-free synchronization. At first, this seems to be an interesting and very efficient technique, especially if someone likes challenges, but for most of the cases, this is not necessary. Just to mention all points that needs to be checked when proving potential algorithm:
- Make sure that algorithm won't end up in a livelock
- Verify it against ABA problem
- Mark all shared variables with volatile keyword
Surprisingly, lock-free algorithms have also their share in constraining general platform's performance. To make them work on weaker IA-64 processor Microsoft had to decide to artificially strength CLR memory model. Until most of the PC processors are x86 compatible, this constraint is not so visible, but as noticed in [DuffyVolatile] it slowly starts to be a problem on the mobile phone platform, whose processors are already weaker than x86 standard.
Bibliography

