Introduction
When we first went live with Pageflakes back in the year 2005, most of us did not have experience with running a mass consumer high volume web application on the Internet. We went through all types of difficulties a web application can face as it grows. Frequent problems with software, hardware, and network were part of our daily life. In the last 2 years, we have overcome a lot of obstacles and established ourselves as one of the top most Web 2.0 applications in the world. From a thousand user website, we have grown to a million user website over the years. We have learnt how to architect a product that can withstand more than 2 million hits per day and sudden spikes like 7 million hits on a day. We have discovered under the hood secrets of ASP.NET 2.0 that solves many scalability and maintainability problems. We have also gained enough experience in choosing the right hardware and Internet infrastructure which can make or break a high volume web application. In this article, you will learn about 13 disasters than can happen to any production website anytime. These real world stories will help you prepare yourself well enough so that you do not go through the same problems as we did. Being prepared for these disasters upfront will save you a lot of time and money as well as build credibility with your users.
13 disasters
We have gone through many disasters over the years. Some of them are:
- Hard drive crashed, burned, got corrupted several times
- Controller malfunctions and corrupts all disks in the same controller
- RAID malfunction
- CPU overheated and burned out
- Firewall went down
- Remote Desktop stopped working after a patch installation
- Remote Desktop max connection exceeded. Cannot login anymore to servers
- Database got corrupted while we were moving the production database from one server to another over the network
- One developer deleted the production database accidentally while doing routine work
- Support crew at hosting service formatted our running production server instead of a corrupted server that we asked to format
- Windows got corrupted and was not working until we reinstalled
- DNS goes down
- Internet backbone goes down in different part of the world
These are some of the problems that usually happen in dedicated hosting. Let's elaborate some of these and make a disaster plan:
Hard drive crash
We experienced hard drive crashes frequently with cheap hosting providers. They used cheap SATA drives that were not reliable. So far we found Western Digital SATA drives to be most reliable. If you can spend money, go for SCSI drives. HP has a lot of variety of SCSI drives to choose from. Better always, go for SCSI drives on web and database server. They are costly, but they will save you from frequent disasters.
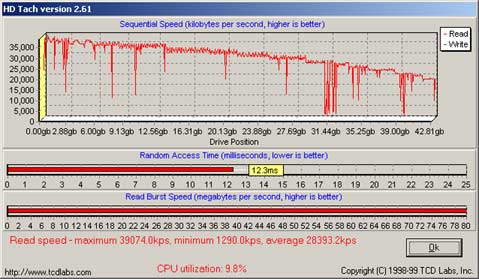
The above figure shows a benchmark of a good hard drive. You need to pay attention to disk speed rather than CPU speed. Generally processor and bus are standard and their performance does not vary much. Disk IO is generally the main bottleneck for production systems. For database server, the only thing you should look at is Disk Speed. Unless you have some really bad queries, CPU will never go too high. Disk IO will always be the bottleneck for database servers. So, for database you need to choose the fastest disk and controller solution.
Controller malfunction
This happens when the servers do not get tested properly and handed over to you in a hurry. Before you accept any server, make sure you get written guaranty that they passed all sorts of exhaustive hardware tests. Dell server's BIOS contain test suites for testing controller, disks, CPU etc. You can also use BurnInTest from www.Passmark.com to test your server's capability under high disk and CPU load. Just run the Benchmark Test for 4 to 8 hours and see how your server is doing. Keep an eye on temperature meters of CPU and Hard drives and ensure they do not get overheated.
RAID malfunction
RAID combines physical hard disks into a single logical unit either by using special hardware or software. Hardware solutions often are designed to present themselves to the attached system as a single hard drive and the operating system is unaware of the technical workings. Software solutions are typically implemented in the operating system, and again would present the RAID drive as a single drive to applications.
In our case, we had RAID malfunction which resulted in disks in the RAID controller corrupt data. We used Windows 2003's built in RAID controller. We learnt never to depend on software RAID and paid extra for hardware RAID. Make sure when you purchase a server that it has a hardware RAID controller.
Once you have chosen the right disks, the next step is to choose the right RAID configuration. RAID means multiple hard disks working together to serve as a single logical drive. For example, RAID 1 takes two identical physical disks and represents them as one single disk to the operation system. Thus every disk write goes to both of them simultaneously. If one disk fails, the other disk can take over and continue to serve the logical disk. Nowadays servers support "hot swap" enabled disks where you can take a disk right out of server while the server is running. The controller immediately diverts all requests to the other disk. This way you can take out a disk, do repair or replacement, then put it back again. Controller synchronizes both disks once the new disk is put into the controller. RAID 1 is suitable for web servers. Here are the pros and cons for RAID 1:
Pros
- Mirroring provides 100% duplication of data
- Read performance is faster than a single disk; if the array controller is capable of performing simultaneous reads from both devices of a mirrored pair. You should make sure your RAID controller has this ability. Otherwise Disk Read will become slower than having a single disk
- Delivers the best performance of any redundant array type during a rebuild. As soon as you put back in a replacement disk after repairs, it quickly synchronizes it with the operational disk
- No re-construction of data is needed. If a disk fails, copying on a block by block basis to a new disk is all that is required
- No performance hit when a disk fails; storage appears to function normally to outside world
Cons
- Raid 1 writes the information twice, because of this there is a minor performance penalty when compared to writing to a single disk
- I/O performance in a mixed read-write environment is essentially no better than the performance of a single disk storage system
- Requires two disks for 100% redundancy; doubling the cost. However, disks are cheap now
For database servers, RAID 5 is a better choice because it is faster than RAID 1. RAID 5 is more expensive than RAID 1 because it requires a minimum of 3 drives. But one drive can fail without affecting the availability of data. In the event of a failure, the controller regenerates the lost data of the failed drive from the other surviving drives.
By distributing parity across the arrays member disks, RAID Level 5 reduces (but does not eliminate) the write bottleneck. The result is asymmetrical performance, with reads substantially outperforming writes. To reduce or eliminate this intrinsic asymmetry, RAID level 5 is often augmented with techniques such as caching and parallel multiprocessors.
Pros
- Best suited for heavy read applications like Database Servers where
SELECT operation it lot higher than INSERT/UPDATE/DELETE - The amount of useable space is the number of physical drives in the virtual drive minus 1
Cons
- A single disk failure reduces the array to RAID 0
- Performance is slower than RAID 1 when rebuilding
- Write performance is slower than read (write penalty)
CPU overheated and burned out
We had this only once that one of the server's CPU burnt out due to overheat. We were partially responsible for this because we had a bad query that made the SQL Server go 100% CPU. So, the poor server ran around 4 hours on 100% CPU and then died.
Servers should never burn out on high CPU usage. Generally servers have monitoring systems in place where the server turns itself off when CPU is about to burn out. This means the defective server did not have the monitoring system working properly. So, you should run tools to push your servers to 100% CPU for 8 hours and ensure they can withstand this. In the event of overheating, the monitoring systems should turn off the servers and save the hardware. However, if the server has a good cooling system, then the CPU will not overheat in 8 hours.

Whenever we move to a new hosting provider we run stress test tools to simulate 100% CPU load on all our servers for 8 to 12 hours. The above figure shows 7 of our servers running on 100% CPU for hours without any problem. In our case, none of the servers got overheated and turned themselves off which means we got a good cooling system as well.
Firewall went down
Our hosting providers Firewall once malfunctioned and exposed our web servers to the public Internet unprotected. We soon found out they were infected and they were starting to shutdown automatically. So, we had to format them, patch them and turn on Windows Firewall. Nowadays, as best practice, we always turn on Windows Firewall on the external network card which is connected to the hardware Firewall. In fact, we purchase redundant firewall just to be on the safe side.
You should turn off File Sharing on the external network card. Unless you have a redundant firewall, you should turn on Windows Firewall as well. Some might argue this will affect performance. We have seen that Windows Firewall has near zero impact on performance.
You should also disable NetBIOS protocol because you should never need it from an external network. You server should be completely invisible to the public network besides having port 80 and port 3389 (for remote desktop) open.
Remote Desktop stopped working after a patch installation
This happened several times that after installing latest patches from Windows Update, Remote Desktop stopped working. Sometimes doing a restart of the server fixed it, sometimes we had to uninstall the patch. In such a case, the only ways you can get into your server are:
use KVM over IP, or
call a support technician
KVM over IP (Keyboard, Video, Mouse over IP) is a special hardware which connects to servers and transmits server's screen output to you. It also takes keyboard and mouse input from you and simulates it on the server. KVM works as if a monitor, keyboard and mouse is directly connected to the server. You can use regular Remote Desktop to connect to KVM and work on the server as if you are physically there. Benefits of KVM:
- Access to all server platforms and all server types
- A "Direct Connect Real Time" solution with no mouse delays due to conversion of signals. Software has to convert signals and this causes delays
- Full use of GUI's
- Full BIOS level access even when the network is down
- The ability to get to the command line and rebuild servers remotely
- Visibility of server boot errors and the ability to take action e.g. "Non-system disk error, please replace system disk and press any key to continue" or "power supply failure press F1 to continue"
- Complete security from "hacking" - a physical connection is required to access the system
If Remote Desktop is not working or your firewall is down or the external network card of your server is not working, you can easily get into the server using KVM. Ensure your hosting provider has KVM support.
Remote Desktop max connection exceeded. Cannot login anymore to servers
This happens when users don't log off properly from remote desktop by closing the Remote Desktop Client. Disconnected sessions exceed the maximum number of active sessions and prevent new sessions. Thus no one can get into the server anymore. Incase this happens, go to Run and issue "mstsc /console" command. This will launch the same old Remote Desktop client you use every day. But when you will connect to remote desktops, it will connect you in Console Mode. Console Mode means connecting to the server as if you are right in front of the server and using the server's keyboard and mouse. Only one person can be connected in console mode at a time. Once you get into the console mode, it shows you the regular Windows GUI. There's nothing different about it. You can launch "Terminal Service Manager" and see the disconnected sessions and boot them out.
Database got corrupted while we were moving the production database from one server to another over the network
Copying large files over the network is not safe. You can have data corruption anytime, especially over the Internet. So, always use WinRAR in Normal compression mode to compress large files. Then copy the RAR file over the network. RAR file maintains CRC and checks the accuracy of the original file while decompressing. If WinRAR can decompress a file properly, you can be sure that there's no corruption in the original file. One caution about WinRAR compression modes: do not use Best compression mode. Always use Normal compression mode. We had seen large files getting corrupted on Best compression mode.
One developer deleted the production database accidentally while doing routine works
In early stages, we did not have a professional Sys Admin taking care of our servers. We, the developers, used to take care of our servers ourselves. This was not ideal. It was disastrous when one of the developers accidentally deleted the production Database thinking it's a backup database. It was his shift to cleanup space from our backup server. So, he went to the backup server using Remote Desktop, logged into SQL Server using "sa" user name and password. He needed to free up some space. So, he deleted the large "Pageflakes" database. SQL Server did warn him the database is in use. But as he never reads any alert which has an "OK" button in it, he clicked the OK button. We were doomed.
Here's what we did wrong which you should make sure you never do:
Sys Admin became too comfortable with the servers. There was lack of seriousness while working on remote desktop. It became routine monotonous absent minded work to him. This is a real problem with a sys admin. On the first month, you will see him very serious about his role. Every time he logs into remote desktop on production or maintenance servers, there's a considerable amount of curves on his forehead. But day by day, concentration starts to slip off and he starts working on production server as if he is working on his own laptop. At some point, someone needs to make him realize what the gravity of his actions is. He should wash his hands before sitting in front of remote desktop and then say his prayer: "O Lord! I am going to work on remote desktop. Grant me tranquility and absolute concentration and protect me from the devil who lures me to cause great harm to production servers".
All databases had the same "sa" password. If we had a different password, at least while typing the password, sys admin could realize where he is connecting to. Although he did connect to remote desktop on the maintenance server, but from SQL Server Management Studio, he connected to the primary database server as he did last time. SQL Server Management Studio remembered the last machine name and user name. So, all he did was enter password and hit enter and delete the database. Now that we have learnt our lessons, we have put the server's name inside the password. So, while typing the password, we know consciously which server we are going to connect to.
Don't ignore confirmation dialogs on remote desktops as you do on your local machine. Nowadays, we consider ourselves super experts on everything and never read the confirmation dialog. I myself don't remember the last time I have read any confirmation dialog seriously. Definitely this attitude must change while working on servers. When Sys Admin tried to delete the database, there was a confirmation that there are active connections on the database. SQL Server tried its best to inform him that this is a database being used and don't delete it, please. But as he does hundred times per day on his laptop, clicked OK without reading the confirmation dialog.
Don't put the same administrator password on all servers. This makes life easier while copying files from one server to another, but don't do it. You will accidentally delete a file on another server just like we used to do often.
DO NOT use Administrator user account to do your day to day work. We started using a Power User account for our day to day operation which has limited access on a couple of folders only. Using Administrator account on remote desktop means you are opening doors to all possible accidents to happen. If you use a restricted account, there's limited possibility of such accidents.
Always have someone beside you when you work on production server and do something important like cleaning up free space or running scripts, restoring database etc. Make sure the other person is not taking a nap on his chair beside you.
Support crew at hosting service formatted our running production server
We told the support technician to format Server A, he formatted Server B. Unfortunately Server B was our production database server which runs the whole site.
Fortunately, we had log shipping and there was a standby database server. We brought it online immediately, changed the connection string in all web.config and went live in 10 mins. We lost around 10 mins worth data as the last log ship from production database to standby database did not happen.
Windows got corrupted and was not working until we reinstalled
Web Server's Windows 2003 64bit got corrupted several times. Interestingly, the database servers never got corrupted. The corruption happened mostly on servers when we had no Firewall device and used Windows Firewall only. So, this must have something to do with external attacks. The corruption also happened when we were not installing patches regularly. Those Security Patches that you see Microsoft delivering every now and then are really important. If you don't install them timely, your OS will get corrupted for sure. Nowadays we can't run Windows 2003 64bit without SP2.
When the OS gets corrupted it behaves abnormally. You will see sometimes that it's not accepting inbound connections anymore. Sometimes you will see this error "An operation on a socket could not be performed because the system lacked sufficient buffer space or because a queue was full". Sometimes you will see login and logoff taking a lot of time. Sometimes Remote Desktop will stop working randomly. Sometimes you will see Explorer.exe and IIS process w3wp.exe crashing frequently. All these are good signs of the OS getting corrupted and time for patch installation.
We found that once the OS gets corrupted, there's no way you can install the latest patches and bring it back. At least for us, it rarely happened that installing some patch fixed the problem. 80% of the time we had to format and reinstall Windows and install the latest service pack and patches immediately. This always fixed such OS level issues.
Patch management is something you don't consider with high priority unless you start suffering from these problems frequently. First of all, you can never turn on Automatic Update and Install on production servers. If you do, Windows will download patches, install them and then restart itself. This means your site will go down unplanned. So, you will always have to manually install patches and bring out a server from Load Balancer, restart it and then put it back to Load Balancer.
DNS goes down
DNS providers sometimes do not have a reliable DNS server. We took hosting and DNS from GoDaddy.com. Their hosting is fine, but DNS hosting is crap. It went down 7 times so far. When DNS goes down, your site goes down as well for all new users and majority of the old users. When visitors enter www.pageflakes.com, the request first goes to the DNS server to get the IP of the domain. So, when the DNS server is down, IP is unavailable and the site becomes unreachable.
There are some professional DNS hosting companies which only do DNS hosting. For example, UltraDNS (www.ultradns.com), DNSPark (www.dnspark.com), Rackspace (www.rackspace.com). You should go for commercial DNS hosting instead of relying on Domain Registration companies to give you a complete package. However, UltraDNS turned out to be negative in DNSStuff.com test. It reported that their DNS hosting has a single point of failure which means both primary and secondary DNS were actually the same server. If that's really true, then it's very risky. So, when you take DNS hosting service, test their DNS servers using DNSStuff.com and ensure you get positive report on all aspects. Some things to ensure are:
- Resolve IP of the primary and secondary DNS server. Make sure you get different IP
- Ensure those different IP are actually different physical computer. I believe the only way to do it is to check with the service provider
- Ensure DNS resolution takes less than 300ms. You can use external tools like DNSStuff.com to test it
Internet backbone goes down in different part of the world
Internet backbones connect the Internet of different countries together. They are the information superhighway that span the oceans connecting continents and countries. For example, UUNet is an Internet backbone that covers USA and also connects with other countries.
There are some other Internet backbone companies like British Telecom, AT&T, Sprint Nextel, France Télécom, Reliance Communications, VSNL, BSNL, Teleglobe (now a division of VSNL International), Flag Telecom (now a division of Reliance Communications), TeliaSonera, Qwest, Level 3 Communications, AOL, and SAVVIS.
All hosting companies in the world are either directly or indirectly connected to some Internet backbone. Some hosting providers have connectivity with multiple Internet backbones.
At an early stage, we used a cheap hosting provider which had connectivity with one Internet backbone only. One day, the connectivity between USA and London went down on a part of the backbone. London was the entry point to the whole of Europe. So, entire Europe and part of Asia could not reach our server in USA. This is a really rare bad luck. Our hosting provider happened to be on that segment of the backbone which was defective. As a result, all websites hosted by that hosting provider were unavailable for one day to Europe and some part of Asia.
So, when you choose a hosting provider, make sure they have connectivity with multiple backbones and do not share bandwidth with telecom companies and do not host online gaming servers.
Tracert can reveal important information about hosting provider's Internet backbone. The following figure shows very good connectivity between hosting provider and Internet backbone.
The tracert is taken from Bangladesh connecting to a server in Washington DC, USA. Some good characteristics about this tracert are:
- Bangladesh and USA are in two parts of the world. Still there are only 9 hops which is very good. This means the hosting provider has chosen very good Internet backbone and has intelligent routing capability to decide the best hops between different countries.
- There are only three hops from pccwbtn.net to the firewall. Also the delay between these hops is 1ms or less. This ensures they have very good connectivity with the Internet backbone.
- There's only one Backbone Company, which is the pccwbtn.net. This means they have direct connection with the backbone and there's no intermediate connectivity.
The following figure shows an example of a bad hosting company with bad Internet connectivity.
Some bad characteristics about this tracert are:
- Total 16 hops compared to 9. It also has 305ms latency compared to 266ms. So, the network connectivity of the hosting provider is bad.
- There are two providers: pccwbtn.net and cogentco.com. This means the hosting provider does not have connectivity with tier-1 providers like pccwbtn.net. They go via another provider in order to save cost. Thus they introduce additional latency and point of failures.
- Cogentco.com gave us trouble several times. We were using two hosting providers connected to cogentco.com and both of them had latency and intermittent connectivity problems.
- There are four hops from the backbone to the web server. This means there are multiple gateways or firewall. Both are sign of poor network design.
- There are too many hops on cogentco.com itself which is an indication of poor backbone connectivity. This means traffic is going between several networks in order to reach the destination web server.
- Traffic goes through 5 different network segments 63.218.x.x, 130.117.x.x, 154.54.x.x, 38.20.x.x before reaching the final destination network XX.41.191.x. This is sign of poor routing capability within the backbone.
Choosing the right hosting provider
Our experience with several bad hosting companies gave us valuable lessons on choosing the right hosting company. We started with very cheap hosting providers and gradually went to one of the most expensive hosting providers in USA – Rackspace. Rackspace is insane when it comes to cost and good service quality. Their technicians are very well trained and their Managed Hosting plan offers onsite Sys Admin and DBA to take care of your servers and database. They can solve SQL Server 2005 issues as well as IIS related problems that we frequently had to solve ourselves. So, when you choose a hosting provider, make sure they have Windows 2003 and IIS 6.0 experts as well as SQL Server 2005 experts. While running production systems, there's always probability that you will fall into trouble which is beyond your capability. Having onsite skilled technicians is the only way for you to survive such disasters.
I have built a check list for choosing the right hosting provider from my experience:
- Test ping time of a server in the same data center where you will get a server. Ping time is less than 40ms within USA and around 250ms average from several other countries including London, Singapore, Brazil, and Germany.
- Ensure multiple backbone connectivity and intelligent routing capability that can choose the best hop from different countries. Do tracert from different countries and ensure the server is available within 10 to 14 hops from anywhere in the world. If your hosting provider is in USA, from anywhere in USA the server should be available within 5 to 8 hops.
- Ensure there are only 3 hops from the Internet backbone to your server. You can verify this by checking the last 3 entries in tracert. The last entry should be your server IP and two entries back should be the Internet backbone provider. This ensures there's only one gateway between your server and the Internet backbone. If there's more hops, that means they have a complex network and you will waste latency within the internal network of your hosting provider.
- 24x7 Phone support to expert technicians. Call them on a Weekend night and give them a complex technical problem. If the crew says he/she is only filling in for the real experts until they get back to office on Monday, discard them immediately. A good hosting provider will have expert technicians available at 3 AM on Saturday night. You will mostly need technicians on Saturday and Sunday late night in order to do maintenance and upgrade.
- Live Chat support. This helps immensely when you are travelling and you cannot make a phone call.
- You can customize your dedicated servers as you want. They do not limit you to predefined packages. This will give an indication that they have in-house technicians who can build and customize servers.
- They can provide you all kinds of software including SQL Server Enterprise edition, Microsoft Exchange 2007, Windows 2003 R2, Windows Longhorn Server etc. If they can't, they do not have a good software vendor. Don't bet your future on them.
- They must be able to provide you with 15K RPM SCSI drives and SAN (Storage Area Network). If they can't, don't consider them. You won't be able to grow your business with the provider if they don't have these capabilities.
- Before you setup a whole data center with a hosting provider, make sure you get one server from them. While ordering the server, order something that you will need in 2 years from now on. See how fast and how reliably they can hand over a server like this to you. This will be an expensive experiment to do. But if you ever get into a bad hosting provider without doing this experiment, the time and money you will lose to get out of them is much more than the cost of the experiment.
Make sure their Service Level Agreement (SLA) ensures the following:
- 99.99% network uptime. Deduction in monthly rent in case of outage in hour and number of occurrence unit.
- Max 2 hours delay in hardware replacement for defective hard drives, network card, mother board equipment, controllers and other input devices
- Full cooperation if you want to get out of their service and go somewhere else. Make sure they don't put you in trap for lifetime.
- In case of service cancellation, you will get to delete all data stored in any storage and backup storages
- Max 2 hours delay in responding to support tickets
This is not an exhaustive list. There can be many other scenarios where things can go wrong with hosting providers. But these are some of the common killer issues that you must try to prevent.
Web site monitoring tool
There are many online website monitoring tools that pings your servers from different locations and ensures the servers and network are performing well. These monitoring solutions have servers all around the world and in many different cities in USA. They scan your website or do some transaction to ensure the site is fully operational and critical functionalities are running fine.
We used www.websitepulse.com which is a perfect solution for our need. We have set up a monitoring system which completes the Welcome Wizard at Pageflakes and simulates a brand new user visit every 5 mins. It calls web services with the proper parameters and ensures the returned content is valid. This way we can ensure our site is running fine. We have also put a very expensive webservice call in the monitoring system in order to ensure the site performance is fine. This also gives us an indication whether the site has slowed down or not.
This figure shows the response time of the site for a whole day. You can see around 2:00 PM the site was down. It was getting timed out. Also from 11:00 AM to 3:00 PM there's high response time which means the site is getting big hit. All these give you valuable indications:
- There might be some job running at 2:00 PM which produces very high response time. Possible suspect – database full backup.
- There can be some job running at 11:30 AM which is causing high response time or there can be a traffic surge which is causing site wide slowdown.
Detail views show the total response time from each test, number of bytes downloaded and number of links checked. This monitor is configured to hit the homepage, find all links in it and hit those links. So, it basically gives the majority of the site one visit on every test and ensures that the most important pages are functional.
Testing individual page performance is important to find out resource hungry pages. Figure 8-22 shows some slow performing pages. The "First" column shows the delay between establishing connection and getting the first byte of response. This means the time you see there is the time the server takes to execute the ASP.NET page on the server. So, when you see 3.38 sec, it means the server took 3.38 seconds to execute the page on server, which is very bad performance. Every hit to this page makes the server go high CPU and high disk IO. So, this page needs to be improved immediately.
Using such monitoring tools you can not only keep an eye on your sites 24x7 but also find out your site's performance at different times and see which pages are performing poorly.
Conclusion
Developing a mass consumer web site is a lot of fun. It's even more fun when it goes live on a massive scale and you start hitting production challenges that you never dreamt of. It's a completely different world out there with production systems compared to our development environment. So, being prepared for such production challenges helps the company prevent common disasters and keep up the user confidence in the long run.

