
Introduction
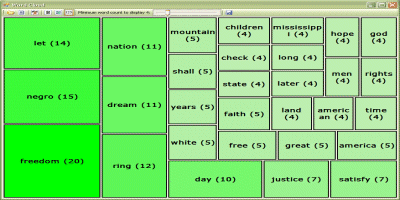
WordCloud is a visual depiction of how many times a word is used, or its frequency if you will, within a given set of words. It does this by: reading in plain text, filtering out "stop words", counting how many times a word is used, and displaying results in a Squarified Treemap. (In the images above, the larger a node and more saturated the color, the more frequent its use.)
Background
I was really impressed, and inspired, by Chirag Mehta's cool web-based tag cloud generator of US Presidential Speeches. So I took a shot at doing a simplified version using .NET.
At best, I'm a hobbyist with the technologies used in this example, so I'm defaulting to various articles I read that lead to creating WordCloud.
The Squarified Treemap
Stemming
Stop words
- Stop words are used to filter out common words before processing.
The Code
To build WordCloud, you'll need to grab the latest version of Microsoft's Data Visualization Components, and update WordCloud's project references to include TreemapGenerator. You'll find this reference in \VisualizationComponents\Treemap\Latest\Components\TreemapGenerator.dll. NOTE: WordCloud needs .NET Framework 2.0 or greater to build and run.
TreemapPanel.cs
TreemapPanel handles node rendering. Nodes are preprocessed into an ArrayList collection and then added to the TreemapGenerator. Object data is stored within each node in the form of NodeInfo.
protected TreemapGenerator m_oTreemapGenerator;
...
public void PopulateTreeMap(Hashtable wordsHash, Hashtable stemmedWordsHash)
{
AssertValid();
ArrayList nodes = new ArrayList();
ArrayList aKeys = new ArrayList(stemmedWordsHash.Keys);
aKeys.Sort();
foreach (string key in aKeys)
{
int count = (int)stemmedWordsHash[key];
string name = (string)wordsHash[key];
if(m_bShowWordCount)
name += String.Format(" ({0})", count);
NodeInfo nodeinfo = new NodeInfo(name, count);
nodes.Add(nodeinfo);
}
m_nodes = nodes;
RepopulateTreeMap();
}
...
private void RepopulateTreeMap()
{
if(m_nodes.Count == 0)
return;
Nodes TreemapGeneratorNodes;
m_TreemapGenerator.Clear();
TreemapGeneratorNodes = m_TreemapGenerator.Nodes;
foreach(NodeInfo n in m_nodes)
{
if(n.Count >= m_nDisplayCount)
{
Node oWordNode = new Node(n.Name, n.Count * 50.0f, 0F);
oWordNode.Tag = n;
TreemapGeneratorNodes.Add(oWordNode);
if (n.Count > m_nLargestCount)
m_nLargestCount = n.Count;
else if (n.Count < m_nSmallestCount)
m_nSmallestCount = n.Count;
}
}
}
Drawing Nodes
The treemap uses custom drawing for nodes, which is called from OnPaint.
m_TreemapGenerator.DrawItem +=
new TreemapGenerator.TreemapDrawItemEventHandler(DrawItem);
...
protected override void OnPaint(PaintEventArgs e)
{
AssertValid();
m_Graphics = e.Graphics;
m_TreemapGenerator.Draw(this.ClientRectangle);
m_Graphics = null;
}
Node rendering is handled in DrawItem(). Within this method we extract the NodeInfo object, get name and count, set color and text size based on count, and then draw the node. Final node result: the greater the count, the larger the text and more saturated the color.
private void DrawItem(Object sender, TreemapDrawItemEventArgs e)
{
AssertValid();
Node oNode = e.Node;
float fontSize = m_FontSize;
int count = 0;
if (oNode.Tag is NodeInfo)
{
NodeInfo oInfo = (NodeInfo)oNode.Tag;
count = oInfo.Count;
if(m_bUseTextScaling)
fontSize += oInfo.Count;
}
else
{
Debug.WriteLine("DrawItem: Skipping node - bad");
return;
}
Color newStartColor = GetColor(count, m_startColor);
Color newEndColor = GetColor(count, m_endColor);
LinearGradientBrush nodeBrush = new LinearGradientBrush(e.Bounds,
newStartColor, newEndColor, LinearGradientMode.Vertical);
nodeBrush.GammaCorrection = true;
m_Graphics.FillRectangle(nodeBrush, e.Bounds);
Font newfont = new Font(m_FontName, fontSize, m_FontStyle);
StringFormat sf = new StringFormat();
sf.Alignment = StringAlignment.Center;
sf.LineAlignment = StringAlignment.Center;
m_Graphics.DrawString(e.Node.Text, newfont, new SolidBrush(m_FontColor),
e.Bounds, sf);
Pen blackPen = new Pen(Color.Black, 2);
m_Graphics.DrawRectangle(blackPen, e.Bounds);
nodeBrush.Dispose();
newfont.Dispose();
blackPen.Dispose();
}
"Massaging" The Text
A worker thread method, DoWordProcessing(), in the main form processes the word collection document. Stemming is also performed in this method for word suffix stripping.
private void DoWordProcessing(object obj)
{
object[] objArray = (object[])obj;
IProgressCallback callback = (IProgressCallback)objArray[0];
StringBuilder sbRawText = (StringBuilder)objArray[1];
ArrayList arrStopWords = (ArrayList)objArray[2];
try
{
Hashtable wordsHash = new Hashtable();
Hashtable stemmedWordsHash = new Hashtable();
PorterStemmer ps = new PorterStemmer();
Document doc = new Document(sbRawText.ToString());
callback.Begin(0, doc.Words.Count);
for (int i = 0; i < doc.Words.Count; ++i)
{
if (callback.IsAborting)
{
callback.End();
return;
}
callback.SetText(String.Format("Reading word: {0}", i));
callback.StepTo(i);
if (!IsNumeric(doc.Words[i]))
{
string key = doc.Words[i].ToLower();
if (!arrStopWords.Contains(key))
{
ps.stemTerm(key);
string stemmedKey = ps.getTerm();
if (!stemmedWordsHash.Contains(stemmedKey))
{
stemmedWordsHash.Add(stemmedKey, 1);
wordsHash.Add(stemmedKey, key);
}
else
{
stemmedWordsHash[stemmedKey] =
(int)stemmedWordsHash[stemmedKey] + 1;
}
}
}
}
this.TreePanel.PopulateTreeMap(wordsHash, stemmedWordsHash);
}
catch (System.Threading.ThreadAbortException)
{
}
catch (System.Threading.ThreadInterruptedException)
{
}
finally
{
if (callback != null)
{
callback.End();
}
}
}
The Demo Application
Controls
Description of the toolbar buttons (in order from left to right):
- Open Text File: Open a text file document to visualize
- Input Text: Paste text into this dialog from another document to visualize (128k max, but can be changed to your liking)
- Stop Words: A dialog allowing you to modify the set of stop words**
- Font: A dialog allowing you set the display font
- Node Color: A dialog allowing you set the gradient colors for node display
- Scale Text: Toggle for scaling text relative to count
- Show Count: Toggle for showing/hiding word count in nodes**
- Minimum word count slider: Dynamically controls how many nodes to display based on word frequency
- Save as image: Save the treemap as a gif image
**NOTE: Document text is not retained in memory; it's only parsed, added to the treemap as nodes, and then discarded. So the Show Count and Stop Words features are only useful before opening/inputting text; it doesn't dynamically show/hide node counts or apply stop words.
Input Data
I've tried various document sizes, ranging from 400 to 6000 words - mostly presidential speeches and the like. In the project, I've included two text files: mlk.txt and kennedy.txt. These are Martin Luther King's "I Have a Dream" address at the March on Washington, August 28, 1963, and former United States President John F. Kennedy's 1961 State of the Union Address - 1,588 and 5,184 words respectively.
Another issue to be aware of is stop words. I've added a default set of stop words which is user configurable and greatly affects word parsing. The 430 stop words provided are fairly standard and cover a wide number of stop words without getting too aggressive.
Conclusion
While crude, un-optimized, not web-based, and entry level at best when compared to other tag/word cloud generators, the example could perhaps be a starting point for someone interested in the idea. It also may serve as a basic example using Microsoft's TreemapGenerator from the Data Visualization Components suite.
Attribution
Tony Capone's Google Groups posting for the TreemapGenerator code
Matthew Adams's Progress Dialog
Leif Azzopardi's port of the Porter's Porter stemming algorithm

