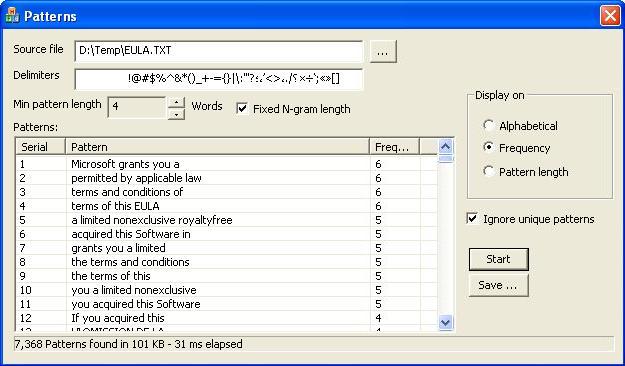
Contents
Introduction
In this article, I introduce a very fast algorithm to extract text patterns from large size text and give statistical information about patterns' frequency and length. Actually, the idea of this algorithm came to me when one of my friends asked me to give him an idea for extracting patterns from text. I told him immediately that he could use the LZW compression algorithm, take the final dictionary and drop the compressed buffer, and then he could have a dictionary containing all text patterns with each pattern frequency. I don't know if he understood me or not, but I decided to do it later. If pattern word count is fixed (N), then it is a generation for N-gram of the input sequence.
Background
N-gram
An n-gram is a sub-sequence of n items from a given sequence. n-grams are used in various areas of statistical natural language processing and genetic sequence analysis. The items in question can be characters, words or base pairs according to the application. For example, the sequence of characters "Hatem mostafa helmy" has a 3-gram of ("Hat", "ate", "tem", "em ", "m m", ...), and has a 2-gram of ("Ha", "at", "te", "em", "m ", " m", ...). This n-gram output can be used for a variety of R&D subjects, such as Statistical machine translation and Spell checking.
Pattern Extraction
Pattern extraction is the process of parsing a sequence of items to find or extract a certain pattern of items. Pattern length can be fixed, as in the n-gram model, or it can be variable. Variable length patterns can be directives to certain rules, like regular expressions. They can also be random and depend on the context and pattern repetition in the patterns dictionary.
Algorithm Idea for Variable Length Pattern Extraction
The algorithm introduced here is derived from the LZW compression algorithm, which includes a magic idea about generating dictionary items at compression time while parsing the input sequence. If you have no idea about LZW, you can check it out at my article, Fast LZW compression. And of course, the algorithm inherits the speed of my implementation to LZW, plus extra speed for two reasons:
- The parsing item is a word, not a letter
- There's no destination buffer, as there is no need for a compressed buffer
The algorithm uses a binary tree to keep extracted patterns that give the algorithm excellent speed at run-time to find and fetch new items to the dictionary. Let us discuss the algorithm pseudo code. We have some figures to clarify the idea with an algorithm flow chart and a simple example.

Example: the input words sequence w0w1w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6
Assume n equals 2; then the initial pattern will be w0w1. After applying the algorithm steps, the resultant dictionary would be as in the fourth column:
| Input Sequence | Pattern | Step | Dictionary | Frequency |
w0w1w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1 | Words available? | | |
w0w1w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1 | Add to dictionary | w0w1 | 3 |
w0w1w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1 | Pattern exists? | | |
w1w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w1w2 | Take new pattern | | |
w1w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w1w2 | Words available? | | |
w1w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w1w2 | Add to dictionary | w1w2 | 1 |
w1w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w1w2 | Pattern exists? | | |
w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w2w3 | Take new pattern | | |
w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w2w3 | Words available? | | |
w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w2w3 | Add to dictionary | w2w3 | 2 |
w2w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w2w3 | Pattern exists? | | |
w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w3w4 | Take new pattern | | |
w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w3w4 | Words available? | | |
w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w3w4 | Add to dictionary | w3w4 | 2 |
w3w4w0w1w5w6w7w2w3w4w0w1w5w6 | w3w4 | Pattern exists? | | |
w4w0w1w5w6w7w2w3w4w0w1w5w6 | w4w0 | Take new pattern | | |
w4w0w1w5w6w7w2w3w4w0w1w5w6 | w4w0 | Words available? | | |
w4w0w1w5w6w7w2w3w4w0w1w5w6 | w4w0 | Add to dictionary | w4w0 | 2 |
w4w0w1w5w6w7w2w3w4w0w1w5w6 | w4w0 | Pattern exists? | | |
w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1 | Take new pattern | | |
w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1 | Words available? | | |
w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1 | Add to dictionary | | |
w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1 | Pattern exists? | | |
w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1w5 | Add word to pattern | | |
w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1w5 | Words available? | | |
w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1w5 | Add to dictionary | w0w1w5 | 2 |
w0w1w5w6w7w2w3w4w0w1w5w6 | w0w1w5 | Pattern exists? | | |
w1w5w6w7w2w3w4w0w1w5w6 | w1w5 | Take new pattern | | |
w1w5w6w7w2w3w4w0w1w5w6 | w1w5 | Words available? | | |
w1w5w6w7w2w3w4w0w1w5w6 | w1w5 | Add to dictionary | w1w5 | 2 |
w1w5w6w7w2w3w4w0w1w5w6 | w1w5 | Pattern exists? | | |
w5w6w7w2w3w4w0w1w5w6 | w5w6 | Take new pattern | | |
w5w6w7w2w3w4w0w1w5w6 | w5w6 | Words available? | | |
w5w6w7w2w3w4w0w1w5w6 | w5w6 | Add to dictionary | w5w6 | 1 |
w5w6w7w2w3w4w0w1w5w6 | w5w6 | Pattern exists? | | |
w6w7w2w3w4w0w1w5w6 | w6w7 | Take new pattern | | |
w6w7w2w3w4w0w1w5w6 | w6w7 | Words available? | | |
w6w7w2w3w4w0w1w5w6 | w6w7 | Add to dictionary | w6w7 | 1 |
w6w7w2w3w4w0w1w5w6 | w6w7 | Pattern exists? | | |
w7w2w3w4w0w1w5w6 | w7w2 | Take new pattern | | |
w7w2w3w4w0w1w5w6 | w7w2 | Words available? | | |
w7w2w3w4w0w1w5w6 | w7w2 | Add to dictionary | w7w2 | 1 |
w7w2w3w4w0w1w5w6 | w7w2 | Pattern exists? | | |
w2w3w4w0w1w5w6 | w2w3 | Take new pattern | | |
w2w3w4w0w1w5w6 | w2w3 | Words available? | | |
w2w3w4w0w1w5w6 | w2w3 | Add to dictionary | | |
w2w3w4w0w1w5w6 | w2w3 | Pattern exists? | | |
w2w3w4w0w1w5w6 | w2w3w4 | Add word to pattern | | |
w2w3w4w0w1w5w6 | w2w3w4 | Words available? | | |
w2w3w4w0w1w5w6 | w2w3w4 | Add to dictionary | w2w3w4 | 1 |
w2w3w4w0w1w5w6 | w2w3w4 | Pattern exists? | | |
w3w4w0w1w5w6 | w3w4 | Take new pattern | | |
w3w4w0w1w5w6 | w3w4 | Words available? | | |
w3w4w0w1w5w6 | w3w4 | Add to dictionary | | |
w3w4w0w1w5w6 | w3w4 | Pattern exists? | | |
w3w4w0w1w5w6 | w3w4w0 | Add word to pattern | | |
w3w4w0w1w5w6 | w3w4w0 | Words available? | | |
w3w4w0w1w5w6 | w3w4w0 | Add to dictionary | w3w4w0 | 1 |
w3w4w0w1w5w6 | w3w4w0 | Pattern exists? | | |
w4w0w1w5w6 | w4w0 | Take new pattern | | |
w4w0w1w5w6 | w4w0 | Words available? | | |
w4w0w1w5w6 | w4w0 | Add to dictionary | | |
w4w0w1w5w6 | w4w0 | Pattern exists? | | |
w4w0w1w5w6 | w4w0w1 | Add word to pattern | | |
w4w0w1w5w6 | w4w0w1 | Words available? | | |
w4w0w1w5w6 | w4w0w1 | Add to dictionary | w4w0w1 | 1 |
w4w0w1w5w6 | w4w0w1 | Pattern exists? | | |
w0w1w5w6 | w0w1 | Take new pattern | | |
w0w1w5w6 | w0w1 | Words available? | | |
w0w1w5w6 | w0w1 | Add to dictionary | | |
w0w1w5w6 | w0w1 | Pattern exists? | | |
w0w1w5w6 | w0w1w5 | Add word to pattern | | |
w0w1w5w6 | w0w1w5 | Words available? | | |
w0w1w5w6 | w0w1w5 | Add to dictionary | | |
w0w1w5w6 | w0w1w5 | Pattern exists? | | |
w0w1w5w6 | w0w1w5w6 | Add word to pattern | | |
w0w1w5w6 | w0w1w5w6 | Words available? | | |
w0w1w5w6 | w0w1w5w6 | Add to dictionary | w0w1w5w6 | 1 |
w0w1w5w6 | w0w1w5w6 | Pattern exists? | | |
w1w5w6 | w1w5 | Take new pattern | | |
w1w5w6 | w1w5 | Add to dictionary | | |
w1w5w6 | w1w5 | Pattern exists? | | |
w1w5w6 | w1w5w6 | Add word to pattern | | |
w1w5w6 | w1w5w6 | Words available? | | |
w1w5w6 | w1w5w6 | Add to dictionary | w1w5w6 | 1 |
w1w5w6 | w1w5w6 | Pattern exists? | | |
w5w6 | w5w6 | Take new pattern | | |
w5w6 | w5w6 | Words available? | | |
w5w6 | w5w6 | Add to dictionary | | |
w5w6 | w5w6 | Pattern exists? | | |
| | Take new pattern | | |
| | Words available? | | |
| | Exit | | |
Algorithm Pseudo Code
ConstructPatterns(src, delimiters, n, fixed)
{
des = AllocateBuffer()
Copy(des, src)
DiscardDelimiters(des, delimiters)
dic = InitializePatternsDictionary()
pattern = InitializeNewPattern(des)
While(des)
{
node = dic.Insert(pattern)
if(!fixed AND node.IsRepeated)
AddWordToPattern(des, pattern)
else
pattern = InitializeNewPattern(des)
UpdateBuffer(des)
}
}
Code Description
ConstructPatterns
This function receives the input buffer, copies it to a destination buffer, and parses it to add found patterns to the dictionary. The constructed dictionary is a binary tree template CBinaryTree<CPattern, CPattern*, int, int> m_alpDic with a key of type CPattern.
void CPatternAlaysis::ConstructPatterns(BYTE *pSrc, int nSrcLen,
LPCSTR lpcsDelimiters ,
int nMinPatternWords ,
bool bFixedNGram )
{
...
...
...
...
m_alpDic.RemoveAll();
CBinaryTreeNode<CPattern, int>* pNode = m_alpDic.Root;
int nPrevLength;
CPattern node(m_pDes, GetPatternLength(
m_pDes, nPrevLength, nMinPatternWords));
while(node.m_pBuffer < m_pDes+nDesLen)
{
pNode = m_alpDic.Insert(&node, -1, pNode);
pNode->Key.m_nFrequency = pNode->Count;
if(bFixedNGram == false && pNode->Count > 1)
node.m_nLength += AddWordToPattern(node.m_pBuffer+node.m_nLength);
else
{ node.m_pBuffer += nPrevLength;
node.m_nLength = GetPatternLength(node.m_pBuffer,
nPrevLength, nMinPatternWords);
pNode = m_alpDic.Root;
}
}
}
Note: The first good point in this function is that it allocates one buffer for the dictionary and all dictionary nodes point to their start buffer, keeping their buffer length in the class CPattern. So, no allocation or reallocation is done during the algorithm.
class CPattern
{
public:
CPattern() {}
CPattern(BYTE* pBuffer, int nLength)
{
m_pBuffer = pBuffer, m_nLength = nLength;
}
CPattern(const CPattern& buffer)
{
*this = buffer;
}
public:
BYTE* m_pBuffer;
int m_nLength;
int m_nFrequency;
inline int compare(const CPattern* buffer);
{ ... }
inline void operator=(const CPattern* buffer)
{
m_pBuffer = buffer->m_pBuffer;
m_nLength = buffer->m_nLength;
}
};
The function does the steps of the pseudo code. The second good point is the usage of a binary tree CBinaryTree to keep the dictionary, with a very good trick here:
The function Insert() of the tree takes a third parameter to start the search from. In normal cases, this parameter should be the tree Root. However, if a pattern is found and a new word is added to it, then we can start the search for the pattern from the current node, as it must be under current node. This is because it is only the previous pattern plus a new word.
In the case of a new pattern, we should start the search from the tree root, so we have this line at the bottom of the function:
pNode = m_alpDic.Root;
GetPatterns
This function doesn't construct patterns. It just retrieves the constructed patterns with three types of sort: Alphabetical, Frequency and Pattern length. The returned patterns are stored in a vector of patterns (OUT vector<CPattern*>& vPatterns).
Alphabetical
CBinaryTreeNode<CPattern, int>* pAlpNode = m_alpDic.Min(m_alpDic.Root);
while(pAlpNode)
{
if(pAlpNode->Count > 1 || !bIgnoreUniquePatterns)
vPatterns.push_back(&pAlpNode->Key);
pAlpNode = m_alpDic.Successor(pAlpNode);
}
Frequency
CBinaryTree<CValue<int>, int, vector<CPattern*>,
vector<CPattern*>* > displayDic;
CBinaryTreeNode<CPattern, int>* pAlpNode = m_alpDic.Min(m_alpDic.Root);
while(pAlpNode != NULL)
{
if(pAlpNode->Count > 1 || !bIgnoreUniquePatterns)
displayDic.Insert(pAlpNode->Count)->
Data.push_back(&pAlpNode->Key);
pAlpNode = m_alpDic.Successor(pAlpNode);
}
CBinaryTreeNode<CValue<int>, vector<CPattern*>* pNode =
displayDic.Max(displayDic.Root);
while(pNode)
{
for(vector<CPattern*>::iterator i = pNode->Data.begin(),
end = pNode->Data.end(); i != end; i++)
vPatterns.push_back(*i);
pNode = displayDic.Predecessor(pNode);
}
Pattern length
CBinaryTree<CValue<int>, int, vector<CPattern*>,
vector<CPattern*>* > displayDic;
CBinaryTreeNode<CPattern, int>* pAlpNode = m_alpDic.Min(m_alpDic.Root);
while(pAlpNode != NULL)
{
if(pAlpNode->Count > 1 || !bIgnoreUniquePatterns)
displayDic.Insert(pAlpNode->Key.m_nLength)->
Data.push_back(&pAlpNode->Key);
pAlpNode = m_alpDic.Successor(pAlpNode);
}
CBinaryTreeNode<CValue<int>, vector<CPattern*>* pNode =
displayDic.Max(displayDic.Root);
while(pNode)
{
for(vector<CPattern*>::iterator i = pNode->Data.begin(),
end = pNode->Data.end(); i != end; i++)
vPatterns.push_back(*i);
pNode = displayDic.Predecessor(pNode);
}
GetPatternCount
This function retrieves the stored patterns count.
int CPatternAlaysis::GetPatternCount()
{
return m_alpDic.Count;
}
Points of Interest
Algorithm Accuracy
The algorithm doesn't give accuracy about pattern frequency in the case of variable length patterns (not n-gram with fixed n). That is because the algorithm constructs patterns while parsing the sequence and checks each constructed pattern with the dynamic dictionary. So, if any pattern is first added to the dictionary, a new pattern is constructed starting from the second word of the previous pattern with length n (min pattern length).
Cross-Document Co-reference
Cross-Document Co-reference is the process of finding a relation between documents. In other words, we can say that two documents are related if the two documents contain similar patterns. This subject is studied in many articles, but I found that the best one is "A Methodology for Cross-Document Coreference" by Amit Bagga and Alan W.Biermann. My algorithm may be helpful to generate patterns that can be taken to find a relation between patterns. The good point here is the very good speed of the algorithm, so it can be used for large numbers of documents like the web. However, directed patterns are better than random patterns to find documents' co-reference.
-
This is an algorithm introduced by Sergey Brin to collect related information from scattered web sources. I like this idea very much and invite all of you to read his article and search the web for its implementation or even its flowchart. My algorithm can't be used here, as it collects patterns without any guided information about retrieved patterns. However, the FIPRE algorithm is a semi-directed algorithm, as it guides the initial pattern search with regular expressions to identify the required pattern, like "book title" and "author name." Alternatively, if the algorithm collects mails, it will include all regular expressions for mails like that:
[^ \:\=@;,,$$**++\t\r\n""'<>/\\%??()&]+@[Hh]otmail.com
[^ \:\=@;,,$$**++\t\r\n""'<>/\\%??()&]+@[Yy]ahoo.com
[^ \:\=@;,,$$**++\t\r\n""'<>/\\%??()&]+@(AOL|aol|Aol).com
Updates
- 10/09/2007: Posted version v0.9000
- 23/09/2007: Updated the source file vector.cpp to initialize the vector buffer with zeros
- 31/10/2007: Updated the header file vector.h to solve "insert" function bug
References
Thanks to...
God

