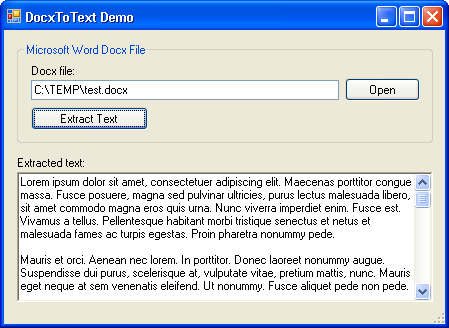
Introduction
At last, Microsoft has turned to XML-based format for storing document content. At the same time, it created a small problem for developers who need to index and search in Microsoft Word *.docx files. It's not a problem on a computer with Microsoft Office 2007 installed, but what is there to do if your application works on a server without Office and still needs to get text from Word files? Well, there are three options:
- Install Microsoft Office 2007 and use its DLLs.
- Use some third party libraries like "Office Open XML C# Library."
- Write your own code.
In fact, there is another option: use the DocxToText class described below.
DocxToText Class
This class performs only one function: it extracts text from a given *.docx file. However, before we dig into the code, I'll remind you that a Microsoft Word *.docx file is an Open XML document combining texts, styles, graphics and so on into a single ZIP archive. Therefore we have to "unpack" the *.docx file to get to its guts. If you work with .NET Framework 3.0, you can use the Package class in the System.IO.Packaging namespace. However, working with .NET Framework 2.0, I used the open-source ZIP library SharpZipLib.
If you rename your *.docx file to *.zip and open it in your archiver, you will see a list of packed files like this:

First of all, we have to read the [Content_Types].xml file and find the location of the document.xml file. Usually, Microsoft hides it in the /word sub-directory, but it can be anywhere if the file was not created by Microsoft Word. Then we have to parse the document.xml file and extract text from it. A ReadNode() method does all the dirty work: it pulls out text strings, paragraphs, tabs and carriage returns, and concatenates it into final text.
Full text of the DocxToText class:
public class DocxToText
{
private const string ContentTypeNamespace =
@"http://schemas.openxmlformats.org/package/2006/content-types";
private const string WordprocessingMlNamespace =
@"http://schemas.openxmlformats.org/wordprocessingml/2006/main";
private const string DocumentXmlXPath =
"/t:Types/t:Override[@ContentType="" +
"application/vnd.openxmlformats-officedocument." +
"wordprocessingml.document.main+xml\"]";
private const string BodyXPath = "/w:document/w:body";
private string docxFile = "";
private string docxFileLocation = "";
public DocxToText(string fileName)
{
docxFile = fileName;
}
#region ExtractText()
public string ExtractText()
{
if (string.IsNullOrEmpty(docxFile))
throw new Exception("Input file not specified.");
docxFileLocation = FindDocumentXmlLocation();
if (string.IsNullOrEmpty(docxFileLocation))
throw new Exception("It is not a valid Docx file.");
return ReadDocumentXml();
}
#endregion
#region FindDocumentXmlLocation()
private string FindDocumentXmlLocation()
{
ZipFile zip = new ZipFile(docxFile);
foreach (ZipEntry entry in zip)
{
if (string.Compare(entry.Name, "[Content_Types].xml", true) == 0)
{
Stream contentTypes = zip.GetInputStream(entry);
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.PreserveWhitespace = true;
xmlDoc.Load(contentTypes);
contentTypes.Close();
XmlNamespaceManager nsmgr =
new XmlNamespaceManager(xmlDoc.NameTable);
nsmgr.AddNamespace("t", ContentTypeNamespace);
XmlNode node = xmlDoc.DocumentElement.SelectSingleNode(
DocumentXmlXPath, nsmgr);
if (node != null)
{
string location =
((XmlElement) node).GetAttribute("PartName");
return location.TrimStart(new char[] {'/'});
}
break;
}
}
zip.Close();
return null;
}
#endregion
#region ReadDocumentXml()
private string ReadDocumentXml()
{
StringBuilder sb = new StringBuilder();
ZipFile zip = new ZipFile(docxFile);
foreach (ZipEntry entry in zip)
{
if (string.Compare(entry.Name, docxFileLocation, true) == 0)
{
Stream documentXml = zip.GetInputStream(entry);
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.PreserveWhitespace = true;
xmlDoc.Load(documentXml);
documentXml.Close();
XmlNamespaceManager nsmgr =
new XmlNamespaceManager(xmlDoc.NameTable);
nsmgr.AddNamespace("w", WordprocessingMlNamespace);
XmlNode node =
xmlDoc.DocumentElement.SelectSingleNode(BodyXPath,nsmgr);
if (node == null)
return string.Empty;
sb.Append(ReadNode(node));
break;
}
}
zip.Close();
return sb.ToString();
}
#endregion
#region ReadNode()
private string ReadNode(XmlNode node)
{
if (node == null || node.NodeType != XmlNodeType.Element)
return string.Empty;
StringBuilder sb = new StringBuilder();
foreach (XmlNode child in node.ChildNodes)
{
if (child.NodeType != XmlNodeType.Element) continue;
switch (child.LocalName)
{
case "t":
sb.Append(child.InnerText.TrimEnd());
string space =
((XmlElement)child).GetAttribute("xml:space");
if (!string.IsNullOrEmpty(space) &&
space == "preserve")
sb.Append(' ');
break;
case "cr":
case "br":
sb.Append(Environment.NewLine);
break;
case "tab":
sb.Append("\t");
break;
case "p":
sb.Append(ReadNode(child));
sb.Append(Environment.NewLine);
sb.Append(Environment.NewLine);
break;
default:
sb.Append(ReadNode(child));
break;
}
}
return sb.ToString();
}
#endregion
}
To extract text from a *.docx file using the DocxToText class, you need a few lines of code:
DocxToText dtt = new DocxToText(docxFileName);
string text = dtt.ExtractText();
Conclusion
The class is a bit primitive, but it performs its main function: to just extract text. It was quite enough to implement indexing and full-text search in *.docx files in my document storage and management system Heliocode Doc@Hand. The class does not extract page headers and footers; it does not process numbering and custom XML; similarly, it knows nothing about the data binding used in documents. If you improve the class, I'll be glad to hear about it.
History
September 17, 2007 - Initial release
Jevgenij lives in Riga, Latvia. He started his programmer's career in 1983 developing software for radio equipment CAD systems. Created computer graphics for TV. Developed Internet credit card processing systems for banks.
Now he is System Analyst in Accenture.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






![Rose | [Rose]](https://codeproject.global.ssl.fastly.net/script/Forums/Images/rose.gif)


