Introduction
The ADO.NET objects provided with VS.NET allow you to retrieve data from a database or other sources, and stores this data in objects called DataSets or DataTables. In fact, the DataSet is a collection of DataTables. One commonly used method available with DataTables is Select(). It allows a developer to perform simple filtering against a DataTable and returns the result as a collection of DataRows. Presently, there is no way to perform a Distinct Query against a DataTable. I just found out that there is a way to perform a Distinct query in .NET. The DataView object exposes a method called ToTable(). This method expects a boolean flag to determine distinct or not, and the fields you wish to distinct on. While this method actually does return distinct rows from a DataTable, it appears that it should only be used for small recordsets. When used on a DataTable with 40,000 rows, it took about 18 seconds. I would imagine that it is pretty quick with a hundred or so. But, if you wish to distinct a large table, there is no better way. Until now.
Background
I had recently encountered a problem with a server being too slow to process user requests for the large amount of data that was returned. I needed to retrieve data and completely manipulate the data in memory to reduce the number of trips made to SQL Server. One major obstacle was the fact that I needed to apply a Distinct query against my DataTable. I quickly found out that it wasn't possible. There was an article from Microsoft that demonstrated a simple Distinct, but it wasn't robust enough to serve my needs. It only allowed for a single column to be specified, and I needed an unknown number of columns at different times. I worked and reworked the Microsoft example until I was finally able to handle multiple columns, filtering/conditions, and sorting.
Using the Code
Within the object, there is only one major method called SelectDistinct(). It is overloaded about ten times to allow flexibility in coding. To use my object, simply instantiate the object and call the SelectDistinct method.
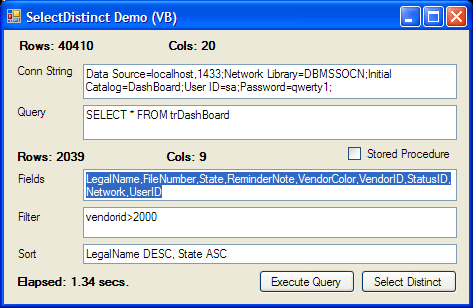
I have included a demo application that will allow you to specify a SQL connection string and a query or Stored Procedure, so that you can test the performance and accuracy of the SelectDistinct object.
dsh = New clsDSH(dt)
Dim dt2 as DataTable = dsh.SelectDistinct(Fields,Filter,Sort)
dsh = New clsDSH()
Dim dt2 as DataTable = dsh.SelectDistinct(dt,Fields,Filter,Sort)
The code examples assume that "dt" has been defined and filled already. Take note that the "dsh" object, in both cases, will actually retain a copy of the DataTable, and can be accessed via the .Table property.
After completing the object, I discovered that it could be made to run faster. I originally did the whole thing with two DataTables, taking only the unique rows and placing them into the new table and returning that table from the object. To my dismay, that was slower than anyone could have imagined. To make a very long story short, I ended up hashing each DataRow and using that hash to compare and produce a distinct table. Unfortunately, the DataRow.GetHashCode() method wasn't distinct enough to be utilized. Luckily, I found that if I carefully converted each DataRow into a string and then executed String.GetHashCode(), it worked. And it worked fast. Currently, the object can take 40,000 records and turn them into around 2000 distinct records in a little over a second! Maybe it could be faster, maybe not. **Update** - Based on some of the code provided to me by srkinyon, I rewrote the object to incorporate some of his ideas, and reorganized and stripped out anything that was no longer necessary. That includes the previously mentioned hashing. Now the object is capable of performing a Distinct query on a DataTable with over 40,000 rows in about 0.6 second. That's ~3 times faster than it was before. Now, that's fast. I have to admit though that I had a slight redundancy in my code as well. Although, the majority of the speed increase seems to have come from the fact that I am now storing the data column values as the objects they are; "object" instead of converting them to a string, and then hashing that. I also have to admit that hashing isn't reliable enough to be used for distinct purposes. So, kudos to srkinyon. If anyone else can make it even faster or better, don't hesitate.
I also added a couple of extra properties for the heck of it. One is RecordCount, which should be self explanatory. Also, ElapsedTime which stores the total time the last Distinct call took. A slight waste of time, but I wanted to know how fast the object is.
Points of Interest
I found out during my development cycle that even the smallest things can slow you down tremendously. Even a .Trim() or a .Split(). So use them wisely.
Also, I wrote the same object in C# which is also available on this site, so you can have it both ways :) Incidentally, there was no real difference in speed between the two languages.
History
None.

