Introduction
This is the second article in a short series where I go in depth with the .NET RegEx engine and Regex class. The first part treated nested RegEx constructions in depth. In this part, I'll study the balancing group and the .NET Regex class and related objects - again using nested constructions as my main focus.
If you are an experienced RegEx developer, please feel free to fast forward to the part "Manipulating nested constructions."
RegEx Anatomy
The Capture class is an essential part of the Regex class. In fact both the Group and the Match class inherit from the Capture class. The class is a specific .NET invention and even though many developers won't ever need to call this class explicitly, it does have some cool features, for example with nested constructions.
According to the .NET documentation, an instance of the Capture class contains a result from a single sub expression capture.
This is easier to grasp with an example.
a+
This is a very simple RegEx that matches 1 or more successive a's. Given the input string aa the RegEx will match the whole string "in one capture". The Match object created will contain one Group object (because a Match object always contains one ordinal 0 Group object), and this Group object will contain one Capture. But we can change this behaviour by manipulating the RegEx a bit:
(a)+
Now the RegEx contains 2 Group objects:
Groups[0]: aa //i.e. the whole match
Groups[1]: a //i.e. the last capture in the parenthesis
Remember that when putting something in a parenthesis, what you actually do is that you tell the RegEx engine to treat what's inside the parenthesis as a Group. It is important that the Group class consists of zero or more Capture objects and always returns the latest capture in the group.
What about the rest of the captures? You guessed right. They are still stored in the Captures collection in the Group object:
Groups[0].Value: aa //i.e. the whole match
Groups[1].Value: a //i.e. the last capture in the group
Groups[1].Captures[0].Value: a //i.e. the first capture in the group
Groups[1].Captures[1].Value: a //i.e. the second capture in the group
// - this is equal to Groups[1]
At first glance this might just seem awkward - why would you need all of those Capture objects? But they do have some cool features.
Manipulating Nested Constructions
Remember the nested constructions from Part I in this article series? Here is what they looked like:
"
(?>
"\b (?<DEPTH> )
|
\b" (?<-DEPTH> )
|
[^"]*
)*
(?(DEPTH)(?!))
"
With this RegEx we'll use this input string:
he said "The Danish capital "Copenhagen" is a nice place" and laughed
Now, applying the RegEx to this input string returns:
match.Value: "The Danish ... nice place"
match.Groups["DEPTH"].Value: ""
match.Groups["DEPTH"].Captures.Count: 0
This looks a bit strange. The RegEx engine creates a Group, but it doesn't contain anything... The reason is that we emptied the group from within the RegEx. Remember how (?<DEPTH>) pushes a capture on the stack and (?<-DEPTH>) pops the stack? Because the double-quotes are nested, the RegEx continues pushing/popping the stack until it ends up empty. This is what the code (?(DEPTH)(?!)) is actually testing! Therefore the DEPTH Group is created but has no captures.
What if we want to get information about the captures afterwards? We've just deleted them to test correct nesting! - And we've observed that the DEPTH Group is empty... The answer to this challenge is the balancing group. The .NET documentation is almost unreadable on this topic. Thus I won't quote it. Instead, I'll try demonstrating the idea.
We already know that a named capture creates a stack and pushes each capture on the stack. This is done with the code (?<STACKNAME>).
We also know that we can pop the stack with the code (?<-STACKNAME>).
Finally we can test if the stack exists with the code (?(STACKNAME) then | else).
As you might already notice, the balanced group looks like a cross between (?<STACKNAME>) and (?<-STACKNAME>). And actually, that's a good way to look at it.
Let's walk through an example:
(?# line 1) (
(?# line 2) (?<OPEN>)"\b
(?# line 3) |
(?# line 4) \b" (?<QUOTE-OPEN>)
(?# line 5) |
(?# line 6) [^"]*
(?# line 7) )*
(?# line 8) (?(OPEN)(?!))
This matches either an opening quote (followed by a word boundary), a closed quote (following a word boundary) or any character which is not a double quote.
This example does the same as we saw in the examples with nested parenthesis in the last article. It pushes an empty element on the OPEN stack (line 2) when an opening quote is matched, and it pops the OPEN stack when a closing element is matched (line 4). Finally it tests whether the stack is empty (line 8).
But the pop command looks a bit different: (?<QUOTE-OPEN>). This command can be divided into two parts. If we begin backwards, the last part is identical to (?<-OPEN>) which pops the OPEN stack. The first part on the other hand is pushing an element on a new stack - the QUOTE stack. I've illustrated what happens in the figure below.
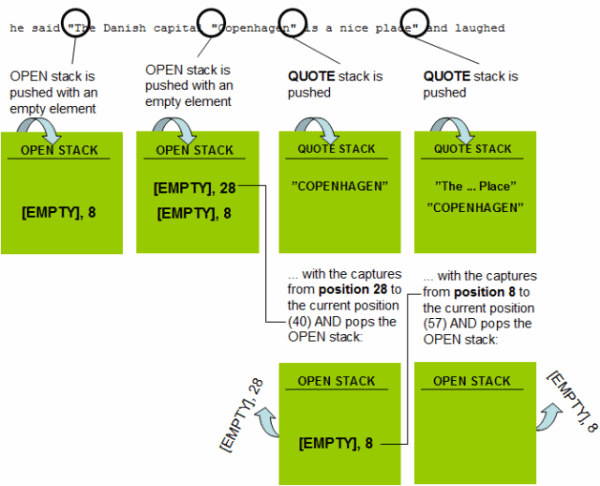
Hence the QUOTE stack contains two captures which can be addressed at runtime like this.
//return "Copenhagen":
Match.Groups["QUOTE"].Captures[0];
//return "The Danish capital "Copenhagen" is a nice place":
Match.Groups["QUOTE"].Captures[1];
In other words. The balancing group pushes and pops two different stacks at the same time. Let's call the stacks PUSH and POP respectively. First it looks at the top of the POP stack. Then it addresses everything that is matched "from" the position of the capture in the top of the POP stack and "up until" the current position. It then pushes this on the PUSH stack and pops the POP stack. Go through the figure again one step at a time - it's really worth understanding the balanced group. Below I've tried to generalize this concept.

In fact, the pop command that we've used before: (?<-DEPTH>), is a balanced group! It omits the PUSH stack and only pops a stack. The case is that in the balanced group syntax (?<NAME1-NAME2>) the first part (NAME1) is optional. If we leave it out, the balanced group just pops NAME2.
Peeking the Stack: Nesting with Multiple Parenthetic Symbols
Unfortunately it is not possible to peek a stack and test the result directly. For example you might want to match constructions nested with both parenthesises and square brackets such as ([]).
On puzzleware.net the algorithm below is posted for this purpose (rewritten a bit):
1. Do ONE of the following (a) to (e)
a. Match '(' and push it on the stack LEVEL
b. If the top of the stack LEVEL is '(' then try to match ')'
and pop the stack
c. Match '[' and push it on the stack LEVEL
d. If the top of the stack LEVEL is '[' then try to match ']'
and pop the stack
e. Otherwise match any character (or nothing) except a (, ), [ and ]
2. Repeat (1) zero or more times.
3. Finally test if the stack LEVEL is empty
The basic idea is to keep the latest kind of opening parenthesis matched on top of the stack. With this knowledge we only allow the correct closing parenthesis to match the opening parenthesis.
As already described, the problem is how to peek the stack. This is not directly possible which is also stated in the mentioned blog post here, and therefore this is only an algorithm of how it "could" be done.
But, actually, if we use balanced grouping we can get around this problem. It won't be pretty, but it works.
We want to make sure that we only capture the correct closing bracket. So, take a look at a short example:
Paul a [les table repeint(es)]
This sentence is from Chomsky's 'The Minimalist Program'. First, we'll rewrite the peeking algorithm a bit:
The previous 1b looked like this:
1b. If the top of the stack LEVEL is '(' then try to match ')'
and pop the stack
The new version looks like this:
1b.
i. Lookahead to make sure the next symbol is ')'
ii. If the symbol before the last capture on the stack was a '('
then try to match ')'
iii. Pop the stack
This makes a difference because now we can use a balanced group. Here's the RegEx:
(?# line 01) (?>
(?# line 02) \( (?<LEVEL>)(?<CURRENT>)
(?# line 03) |
(?# line 04) (?=\))
(?# line 05) (?<LAST-CURRENT>)
(?# line 06) (?(?<=\(\k<LAST>)
(?# line 07) (?<-LEVEL> \))
(?# line 08) )
(?# line 09) |
(?# line 10) \[ (?<LEVEL>)(?<CURRENT>)
(?# line 11) |
(?# line 12) (?=\])
(?# line 13) (?<LAST-CURRENT>)
(?# line 14) (?(?<=\[\k<LAST>)
(?# line 15) (?<-LEVEL> \] )
(?# line 16) )
(?# line 17) |
(?# line 18) [^()\[\]]*
(?# line 19) )+
(?# line 20) (?(LEVEL)(?!))
I don't blame you if you can't grasp this expression immediately, but I will encourage you to take the time and let me walk you through it - it's quite a rewarding example.
First, we break it down in two parts. Lines 2 - 8 match ( and ) while lines 10 - 15 match [ and ]. These are the main parts. Additionally line 18 matches any character that is not (, ), [ and ], and line 20 tests if the LEVEL stack is empty.
We'll focus on the first of the two main parts, i.e. lines 2 - 8. When we understand this part, we'll understand the whole expression.
First (line 2) we try to match an opening parenthesis (. If this succeeds, we push two different stacks with empty elements: LEVEL and CURRENT. The two stacks have different purposes. The LEVEL stack makes sure that the number of opening and closing parenthesis matched are equal. We'll use the CURRENT stack to "peek" the LEVEL stack. Hereby we make sure that we match the correct kind of opening parenthesis with the correct kind of closing parenthesis. I've put the word peek in double quotes indicating that we're actually cheating a bit, but we'll get back to this later.
Now, to match the opening ( with a closing ) we have set some restrictions. First line 4 states that the following symbol must be a closing parenthesis. This is not very surprising. But line 5 is quite interesting. Here we use balanced grouping to push a new stack (LAST). What happens is that we take everything which is matched since the last CURRENT stack until the current position and push this whole capture on the LAST stack. Remember that the CURRENT stack is always pushed just after a ( or [ (line 2 and 10). On the LAST stack we then push everything that is matched since the last ( or [ up until the current position.
In the figure below, I've illustrated the process.
I have left out the LEVEL stack because the only job for this stack is to test that the number of nestings are correct.
The relation between the OPEN stack and the LAST stack is more fun. Here the CURRENT stack is used to determine if the closing parenthesis should be ) or ]. The trick is a positive lookbehind (in lines 6 and 14). The RegEx engine looks behind to test if the latest match is equal to the top of the LAST stack. This will always be the case! Therefore it is possible to prefix this lookbehind statement with either a \( or a \[. If the symbol before the top of the LAST stack is ( then a ) is matched and vice versa.
This lookbehind is a bit expensive though! It would be much easier if it was possible to catch all of the parenthesises in one stack and solely test which kind of parenthesis resides on the top of the stack. But - as far as I know - this is not possible. At least not yet, so if you need to do a peek, the pattern described here is possibly the only way.
The expression has one major advantage though. As you can see in the figure, all of the parenthesis matched are stored in the LAST stack which is never popped. This enables us to request the parenthesis one at a time:
foreach (System.Text.RegularExpressions.Capture capture
in match.Groups["LAST"].Captures)
{
Console.WriteLine(capture.Value);
}
In our example this will return:
es
les table repeint(es)
Points of Interest
The balancing group is hard to understand. And it is not very well documented. I hope this article does part of the job. The balancing group also turns out to be very useful in various cases, first of all when we need to address each of the captures in a nested pattern. Secondly we are able to use the balancing group to mimic a peek on the stack and match nested constructions with multiple parenthetic symbols.

