Introduction
When I started work with SSIS, I did not know even what SSIS is and what it does. So I just started to read and make short notes for all its features. I am explaining some of the important definitions and process flow in this article. I will explain each control and its configurations in the coming parts. Here I am emphasizing on the architecture, behavior and important items of SSIS. The content I have provided belongs to "MSDN" and "Pro SQL Server 2005 Integration Services".
Overview of SSIS
SQL Server Integration Services (SSIS) is a platform for building high performance data integration and workflow solutions. It allows creation of packages or SSIS packages which are made up of tasks that can move data from source to destination and alter it if required. SSIS is basically an ETL (Extraction, Transformation, and Load) tool whose main purpose is to do extraction, transformation and loading of data but it can be used for several other purposes, for example, to automate maintenance of SQL Server databases, update multidimensional cube data or send e-mails detailing the status of the operation as defined by the user. SSIS is a component of SQL Server 2005/2008 and is the successor of DTS (Data Transformation Services) which had been in SQL Server 7.0/2000.
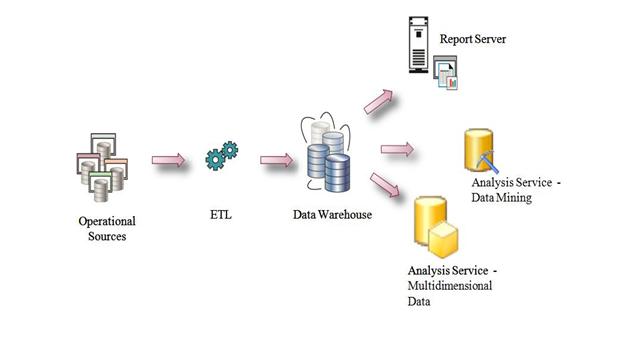
Typical Use of Integration Services
- Merging Data from Heterogeneous Data Stores
- Populating Data Warehouses and Data Marts
- Cleaning and Standardizing Data
- Building Business Intelligence into a Data Transformation Process
- Automating Administrative Functions and Data Loading
Glossary
Package
Packages are the root of the hierarchy. Although an SSIS solution can contain a number of packages, they are not held, logically or physical, in any kind of container.
Container
The level beneath the package can be either a container or some kind of executable (a Control Flow executable). A container is a logical construct that can hold other containers or components grouped together under the “super-container.”
Executable
A component that implements the necessary SSIS interfaces and so makes itself available for use within SSIS. An example is the Script Component, which supports the running of Visual Basic.NET code within your package against contained Data Flow.
Variables
SSIS provides support for strongly typed part–Common Type System (CTS)–compliant variables as a part of any container or package.
Scope
Scope refers to the visibility and usability of a variable to a piece of code, based on where in the code the variable is defined. For example, a variable with global scope is defined at package level and is visible to and usable by any package, container, or component in the hierarchy beneath it. By contrast, a variable defined at Data Flow task level is visible only to that task and its subtasks.
Precedence constraints
Control Flow design surface may have multiple Control Flow items, in this situation we need to decide which item will execute first. Using Precedence Constraints, we can define processing flow for Control Flow items. We can define different flow based on success or failure of any item.
Event Handlers
Event handlers are offered at most levels of the package hierarchy. The types of event handlers differ depending upon the type of object against which you want to handle events.
SSIS Architecture
Microsoft SQL Server Integration Services (SSIS) consist of four key parts:
- SSIS Service
- SSIS Object Model
- SSIS runtime engine and the runtime executables
- SSIS dataflow engine and the dataflow components

Integration Services Service
- Monitors running Integration Services packages and manages the storage of packages
- Integration Services object model
- Includes native and managed application programming interfaces (API) for accessing
- Integration Services tools, command-line utilities, and custom applications
SSIS Run-time Engine & executables
- Runs packages
- Supports logging, debugging, config, connections, & transactions
- SSIS Run-time executables
- Package, Containers, Tasks and Event Handlers
SSIS Data-flow Engine & components
- Provides In-Memory buffers to move data
- Calls Source Adaptors to files & DBs
- Provides Transformations to modify data
- Destination Adaptors to load data into data stores
- Components
- Source, Destination Adaptors & transformations
SQL Server Business Intelligence Development Studio
SQL Server Business Intelligence Development Studio (BIDS) allows users to create / edit SSIS packages using a drag-and-drop user interface. BIDS is very user friendly and allows you to drag-and-drop functionalities. There are a variety of elements that define a workflow in a single package. Upon package execution, the tool provides color-coded, real-time monitoring.
Components of SSIS Package include
Control Flow
Control flow deals with orderly processing of tasks, which are individual, isolated units of work that perform a specific action ending with a finite outcome (such that can be evaluated as either Success, Failure, or Completion). While their sequence can be customized by linking them into arbitrary arrangements with precedence constraints and grouping them together or repeating their execution in a loop with the help of containers, a subsequent task does not initiate unless its predecessor has completed.
Elements of Control Flow include
Container
Containers provide structure in packages and services to tasks in the control flow. Integration Services include the following container types, for grouping tasks and implementing repeating control flows:
- The
Foreach Loop container: It enumerates a collection and repeats its control flow for each member of the collection. The Foreach Loop Container is for situations where you have a collection of items and wish to use each item within it as some kind of input into the downstream flow. For Loop Container: It’s a basic container that provides looping functionality. A For loop contains a counter that usually increments (though it sometimes decrements), at which point a comparison is made with a constant value. If the condition evaluates to True, then the loop execution continues. - Sequence Container: One special kind of container both conceptually and physically can hold any other type of container or Control Flow component. It is also called “container container”, or super container.
Tasks
Tasks do the work in packages. Integration Services includes tasks for performing a variety of functions.
- The Data Flow task: It defines and runs data flows that extract data, apply transformations, and load data.
- Data preparation tasks: It copies files and directories, downloads files and data, saves data returned by Web methods, or works with XML documents.
- Workflow tasks: It communicates with other processes to run packages or programs, sends and receives messages between packages, sends e-mail messages, reads Windows Management Instrumentation (WMI) data, or watch for WMI events.
- SQL Server tasks: It accesses, copy, insert, delete, or modify SQL Server objects and data.
- Analysis Services tasks: It creates, modifies, deletes, or processes Analysis Services objects.
- Scripting tasks: It extends package functionality through custom scripts.
- Maintenance tasks: It performs administrative functions, such as backing up and shrinking SQL Server databases, rebuilding and reorganizing indexes, and running SQL Server Agent jobs.
Precedence constraints
Precedence constraints connect containers and task in packages into an ordered control flow. You can control the sequence execution for tasks and containers, and specify conditions that determine whether tasks and containers run.
Data Flow
It’s processing responsibilities by employing the pipeline paradigm, carrying data record by record from its source to a destination and modifying it in transit by applying transformations. (There are exceptions to this rule, since some of them, such as Sort or Aggregate require the ability to view the entire data set before handing it over to their downstream counterparts). Items which are used to creating a data flow categorize into three parts.
Elements of Data Flow include
Elements of Data Flow are categorized into three parts:
- Data Flow Sources: These elements are used to read data from different type of sources like (SQL Server, Excelsheet, etc.)
- Data Flow Transformations: These elements are used to do process on data like (cleaning, adding new columns, etc.)
- Data Flow Destinations: These elements are used save processed data into desired destination. (SQL Server, Excelsheet, etc.)
Data Flow Source
Different items which can communicate in various types of source data are listed below:
- DataReader Source: The
DataReader source uses an ADO.NET connection manager to read data from a DataReader and channel it into the Data Flow. - Excel Source: The Excel source connects to an Excel file and, selecting content based on a number of configurable settings, supplies the Data Flow with data. The Excel Source uses the Excel
connectionmanager to connect to the Excel file. - Flat File source: Formats of which include CSV and fixed-width columns—are still popular. For many reasons, individual circumstances can dictate the use of CSV files over other formats,which is why the Flat File Source remains a popular Data Flow data source.
- OLE DB Source: The OLEDB Source is used when the data access is performed via an OLE DB provider. It’s a fairly simple data source type, and everyone is familiar with OLE DB connections.
- Raw file Source: The Raw File Source is used to import data that is stored in the SQL Server raw file format. It is a rapid way to import data that has perhaps been output by a previous package in the raw format.
- XML Source: The XML Source requires an XML Schema Definition (XSD) file, which is really the most important part of the component because it describes how SSIS should handle the XML document.
Data Flow Transformation
Items in this category are used to perform different operations to make data in desired format.
- Aggregate: The Aggregate transformation component essentially encapsulates number of aggregate functions as part of the Data Flow, like
Count, Count distinct, Sum, Average, Minimum, Maximum, Group By with respect to one or more columns. - Audit: The Audit transformation exposes system variables to the Data Flow that can be used in the stream. This is accomplished by adding columns to the Data Flow output. When you map the required system variable or variables to the output columns, the system variables are introduced into the flow and can be used.
- Character Map: It performs
string manipulations on input columns Like Lowercase, Uppercase, etc. - Conditional Split: The Conditional Split task splits Data Flow based on a condition. Depending upon the results of an evaluated expression, data is routed as specified by the developer.
- Copy Column: The Copy Column task makes a copy of a column contained in the input-columns collection and appends it to the output-columns collection.
- Data Conversion: It is converting data from one type to another. Just like Type Casting.
- Data Mining Query: The data-mining implementation in SQL Server 2005 is all about the discovery of factually correct forecasted trends in data. This is configured within SSAS against one of the provided data-mining algorithms. The DMX query requests a predictive set of results from one or more such models built on the same mining structure. It can be a requirement to retrieve predictive information about the same data calculated using the different available algorithms.
- Derived Column: One or more new columns are appended to the output-columns collection based upon the work performed by the task, or the result of the derived function replaces an existing column value.
- Export Column: It is used to extract data from within the input stream and write it to a file. There’s one caveat: the data type of the column or columns for export must be
DT_TEXT, DT_NTEXT, or DT_IMAGE. - Fuzzy Grouping: Fuzzy Grouping is for use in cleansing data. By setting and tweaking task properties, you can achieve great results because the task interprets input data and makes “intelligent” decisions about its uniqueness.
- Fuzzy Lookup: It uses a reference (or lookup) table to find suitable matches. The reference table needs to be available and selectable as a SQL Server 2005 table. It uses a configurable fuzzy-matching algorithm to make intelligent matches.
- Import Column: It is used to import data from any file or source.
- Lookup: The Lookup task leverages reference data and joins between input columns and columns in the reference data to provide a row-by-row lookup of source values. This reference data can be a table, view, or dataset.
- Merge: The Merge task combines two separate sorted datasets into a single dataset that is expressed as a single output.
- Merge Join: The Merge Join transform uses joins to generate output. Rather than requiring you to enter a query containing the
join, however (for example SELECT x.columna, y.columnb FROM tablea x INNER JOIN tableb y ON x.joincolumna = y.joincolumnb), the task editor lets you set it up graphically. - Multicast: The Multicast transform takes an input and makes any number of copies directed as distinct outputs. Any number of copies can be made of the input.
- OLE DB Command: The OLE DB command transform executes a SQL statement for each row in the input stream. It’s kind of like a high-performance cursor in many ways.
- Percentage Sampling: The Percentage Sampling transform generates and outputs a
dataset into the Data Flow based on a sample of data. The sample is entirely random to represent a valid cross-section of available data. - Pivot: The Pivot transformation essentially encapsulates the functionality of a pivot query in SQL. A pivot query demoralizes a normalized data set by “rotating” the data around a central point—a value.
- Row Count: The Row Count task counts the number of rows as they flow through the component. It uses a specified variable to store the final count. It is a very lightweight component in that no processing is involved, because the count is just a property of the input-rows collection.
- Row Sampling: The Row Sampling task, in a similar manner to the Percentage Sampling transform I discussed earlier, is used to create a (pseudo) random selection of data from the Data Flow. This transform is very useful for performing operations that would normally be executed against a full set of data held in a table. In very high-volume OLTP databases, however, this just isn’t possible at times. The ability to execute tasks against a representative subset of the data is a suitable and valuable alternative.
- Sort: This transform is a step further than the equivalent
ORDER BY clause in the average SQL statement in that it can also strip out duplicate values. - Script Component: The Script Component is using for scripting custom code in transformation. It can be used not only as a transform but also as a source or a destination component.
- Slowly Changing Dimension: The Slowly Changing Dimension task is used to maintain dimension tables held in data warehouses. It is a highly specific task that acts as the conduit between an OLTP database and a related OLAP database.
- Term Extraction: This transformation extracts terms from within an input column and then passes them into the Data Flow as an output column. The source column data type must be either
DT_STR or DT_WSTR. - Term Lookup: This task wraps the functionality of the Term Extraction transform and uses the values extracted to compare to a reference table, just like the Lookup transform.
- Union All: Just like a
Union All statement in SQL, the Union All task combines any number of inputs into one output. Unlike in the Merge task, no sorting takes place in this transformation. The columns and data types for the output are created when the first input is connected to the task. - Unpivot: This task essentially encapsulates the functionality of an unpivot query in SQL. An unpivot query increases the normalization of a less-normalized or denormalized data set by “rotating” the data back around a central point—a value.
Data Flow Destination
Finally, processed data will saved at destination with the help of these items.
- Data Mining Model Training: It trains data-mining models using sorted data contained in the upstream Data Flow. The received data is piped through the SSAS data-mining algorithms for the relevant model.
- DataReader Destination: The results of an SSIS package executed from a .NET assembly can be consumed by connecting to the
DataReader destination. - Dimension Processing: Dimension Processing is another SSAS-related destination component. It is used to load and process an SSAS dimension.
- Excel Destination: The Excel Destination has a number of options for how the destination Excel file should be accessed. (
Table or View, TableName or ViewName variable, and SQL Command) - Flat File Destination: The Flat File Destination component writes data out to a text file in one of the standard flat-file formats: delimited, fixed width, fixed width with row delimiter.
- OLE DB Destination: The OLE DB Destination component inserts data into any OLE DB–compliant data source.
- Partition Processing: The Partition Processing destination type loads and processes an SSAS partition. In many ways, it is almost exactly the same as the Dimension Processing destination—at least in terms of configuration. You select or create an SSAS connection manager, choose the partition to process, and then map input columns to the columns in the selected partition.
- Raw File Destination: The Raw File Destination is all about raw speed. It is an entirely native format and can be exported and imported more rapidly than any other connection type, in part because the data doesn’t need to pass through a connection manager.
- Recordset Destination: The Recordset Destination creates an instance of an ActiveX Data Objects (ADO) Recordset and populates it with data from specified input columns.
- SQL Server Destination: The SQL Server Destination provides a connection to a SQL Server database. Selected columns from the input data are bulk inserted into a specified table or view. In other words, this destination is used to populate a table held in a SQL Server database.
- SQL Server Mobile Destination: The SQL Server Mobile Destination component is used to connect and write data to a SQL Server Mobile (or SQL Server Compact Edition) database.
Conclusion
As I mentioned before, here we emphasized more on the capabilities and overview of SSIS. We will talk more about each control and explore each control with examples in later parts of this series.
We two people created this document with example, so the next part is uploaded with my counterpart on code project. Please check below link for the working example.
History
- 1st July, 2011: Initial version

