Introduction
Some time back my mom asked my younger brother to get butter from the grocery shop. As soon as he returned, she recalled that curd was also required. He was forced to go again and get it from the shop. Had my mom remembered things and asked him to get both things at once, it would have save his time and travel expenses and most importantly eliminated redundancy. The same applies for SQL Server 2008.
Let’s say we have two databases “TestDB” and “SampleDB” and both of them have a table EMP with the description:
CREATE TABLE [dbo].[EMP](
[EID] [int] PRIMARY KEY,
[ENAME] [varchar](20) NULL,
[DEPT] [varchar](10) NULL)
Both of them host the same table but with different data. The data for TestDB is :
SELECT * FROM EMP;
EID ENAME DEPT
1 Keshav IT
2 Rohan HR
3 Madhav Finance
The content of SampleDB’s EMP table is:
SELECT * FROM EMP;
EID ENAME DEPT
1 Keshav HR
4 Sachin IT
Considering the TestDB’s EMP table as the source and SampleDB’s EMP table as the target, there is a requirement that:
- If there is a record match based on the EID (which is a Primary Key) in both the tables, keep the data for all the other fields in sync with the source. In this example, we have a match for EID 1. As the DEPT for EID 1 is not in sync, we would need to perform an
Update on the target EMP table with respect to the source. - If there is any record missing in the target with respect to the source, insert it. In this example, we have EID 2 and 3 missing in the target so there has to be two
Inserts in the target table. - If there is anything in the target which is not present in the source, delete it as we have to keep both the tables in sync completely. Here we have EID 4 in the target which is not present in the source. There has to be a
Delete operation performed on the target for removing the EID 4.
Conventionally, these requirements would need 1 Update, 2 Inserts, and 1 Delete operation to be fired separately. But SQL Server 2008 has included a very impressive Merge keyword which enables all of these to be taken care of in one go.
For the syntax of the Merge statement, go to MSDN.
A typical merge for the above requirement would be as below:
MERGE SampleDB.dbo.EMP AS Trgt
USING TestDB.dbo.EMP AS Src
ON Trgt.EID=Src.EID
WHEN MATCHED AND (Trgt.ENAME<>Src.ENAME OR Trgt.DEPT<>Src.DEPT) THEN
UPDATE SET Trgt.ENAME=Src.ENAME,Trgt.DEPT=Src.DEPT
WHEN NOT MATCHED THEN
INSERT VALUES (Src.EID,Src.ENAME,Src.DEPT)
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
This query will perform all the required operations in one go. Let’s strip each segment and try to understand it. The WHEN MATCHED clause along with the AND conditions takes care of our first requirement. This clause for EID 1 will update the DEPT as per the source.
The WHEN NOT MATCHED clause inserts all the records from the source to target as per the second requirement which is for EID 2, 3 in the source. And lastly, the WHEN NOT MATCHED BY SOURCE clause deletes all the records existing in the target but not in the source.
Advantages
- This keyword loads the data only once.
- Performs all the three operations in one go and syncs both the tables.
The final result on the target (SampleDB.dbo.EMP) being in sync with the source:
EID ENAME DEPT
1 Keshav IT
2 Rohan HR
3 Madhav Finance
Utility: Delta Derivation
That was a brief on the Merge keyword. The primary purpose of this article though is to provide one of the most important utilities of this Merge keyword. This keyword can simplify a very complex scenario of Delta Derivation in the field of data warehousing. In a typical downstream data storage system where data from the application databases (DB) are pumped into the warehouses (WH) and stored, there are constant jobs running between the DB and WH to pull in any new table from these DBs and sync the existing tables in the WH with respect to the DBs.
The Merge keyword can simplify this requirement to a great extent. Let’s explore how. I will present a very typical scenario I have faced and we shall take it from there.
Requirement
Let’s try to get the requirement very clearly:
- We have an AppDB hosting production tables where all the transactions occur.
The tables are such that all the esisting tables or those being freshly added are prefixed with TBL_.
- Also there is a WareHouseDB (on a separate server) which is a repository of this DB. This database warehouses all the tables.
- There are regular jobs scheduled and each time a job runs, it syncs up with the AppDB. For any new table at the source, it simply pulls the complete table to the target, and for existing tables, the job syncs up the records.
- Additionally, each of the tables in the source has a field which is a primary key clustered index.
- Sync up is based on three basics precisely, which are as per the Merge example above.
- If there is a record match based on the Primary Key column in both the tables, keep the data for all the other fields in sync with the source.
- If there is a record missing in the target with respect to the source, insert it.
- If there is anything in the target which is not present in the source, delete it as we have to keep both the tables in sync completely.
Based on these inputs, we are to design a job such that these requirements are met.
Technical Solution
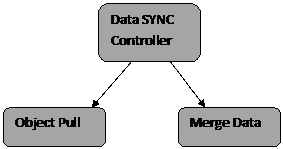
Looking at the requirement above, the technical plan is to create three Stored Procedures as per the diagram.
We will have to break up the requirements into three modules:
- Create a Master Stored Procedure with the name DataSyncController. This SP will be responsible for invoking the other two procedures.
- The ObjectPull procedure will simply connect to the source AppDB and pull the new tables created at the source and warehouse it at the destination. This will be invoked by the DataSyncController procedure for the appropriate tables.
- The MergeData procedure will execute for existing tables and will sync them based on the requirements above. This will be invoked by the DataSyncController procedure for the appropriate tables.
- The DataSyncController procedure will invoked by the SQL job as per the desired schedule.
Dependencies

All the components in the three procedures and the SQL job will reside on the WareHouseDB and will work in a Pull mechanism at regular intervals as per the configured schedule.
There will be a single dependency: there should be a linked server connectivity from the WareHouseDB to AppDB to be able to Pull the data as per the schedule.
Code
1. DataSyncController Procedure
Let's try to understand the procedure. The procedure takes two parameters as input: ServerName which is the source server name where the AppDB is hosted, and DatabaseName which is the AppDB in our case. Next, the proc tries to identify if there is a linked server connectivity to the AppDB server; if negative, it reports and aborts. If there is a linked server connectivity, the code loops across all the existing tables with a “TBL_” prefix. Within the loop, the code identifies if the table is a new addition on the AppDB. If so, it calls the ObjectPull procedure. If the table already exists in the WareHouseDB, it finds the clustered index Colum name and then calls the MergeData procedure.
CREATE PROCEDURE [dbo].[DataSyncController]
@ServerName SYSNAME,
@DatabaseName SYSNAME
AS
BEGIN
DECLARE @SqlString NVARCHAR(4000)
DECLARE @Count INT
DECLARE @LSrv INT
DECLARE @TableName SYSNAME
DECLARE @IndexColumnName SYSNAME
SELECT @LSrv=COUNT(1) FROM SYS.servers WHERE name=@ServerName
IF (@LSrv=0)
PRINT 'There is no Linked Server established with the Server '+
@ServerName+'. Create a Linked Server and re-try.'
ELSE
BEGIN
SET @SqlString = 'SELECT @TableNameOUT = MIN(NAME)
FROM ['+@ServerName+'].'+@DatabaseName+'.SYS.OBJECTS
WHERE NAME LIKE ''TBL_%'' AND TYPE_DESC=''USER_TABLE'''
EXEC SP_EXECUTESQL @SqlString,
N'@TableNameOUT SYSNAME OUTPUT',
@TableNameOUT=@TableName OUTPUT
WHILE (@TableName IS NOT NULL)
BEGIN
SET @SqlString='SELECT @CountOUT=COUNT(1)
FROM SYS.OBJECTS
WHERE NAME='''+@TableName+
''' AND TYPE_DESC=''USER_TABLE'''
EXEC SP_EXECUTESQL @SqlString,
N'@CountOUT INT OUTPUT',
@CountOUT=@Count OUTPUT
IF (@Count=0)
EXEC ('EXEC dbo.ObjectPull '''+@ServerName+''','''+
@DatabaseName+''','''+@TableName+'''')
ELSE
BEGIN
SET @SqlString='SELECT @IndexColumnNameOUT=MIN(SC.NAME) FROM ['+
@ServerName+'].'+@DatabaseName+'.SYS.Columns SC INNER JOIN ['+
@ServerName+'].'+@DatabaseName+
'.SYS.Index_Columns SIC ON SIC.Column_ID' +
'=SC.Column_ID AND SIC.Object_ID=SC.Object_ID INNER JOIN ['+
@ServerName+'].'+@DatabaseName+
'.SYS.Indexes SI ON SI.Index_Id=SIC.Index_ID ' +
'WHERE SC.Object_ID=(SELECT Object_ID FROM ['+@ServerName+'].'+
@DatabaseName+'.SYS.Objects WHERE name='''+
@TableName+''')AND SI.Type=1'
PRINT @SqlString
EXEC SP_EXECUTESQL @SqlString,
N'@IndexColumnNameOUT SYSNAME OUTPUT',
@IndexColumnNameOUT=@IndexColumnName OUTPUT
EXEC ('EXEC dbo.MergeData '''+@ServerName+''','''+@DatabaseName+''','''+
@TableName+''','''+@IndexColumnName+'''')
END
SET @SqlString = 'SELECT @TableNameOUT = MIN(NAME)
FROM ['+@ServerName+'].'+@DatabaseName+'.SYS.OBJECTS
WHERE NAME LIKE ''TBL_%'' AND TYPE_DESC=''USER_TABLE'' AND NAME>'''+
@TableName+''''
EXEC SP_EXECUTESQL @SqlString,
N'@TableNameOUT SYSNAME OUTPUT',
@TableNameOUT=@TableName OUTPUT
END
END
END
2. ObjectPull Procedure
This procedure simply takes the server name, database name, and the table name as the input and based on those, it simply connects to the AppDB and pulls the object.
CREATE PROCEDURE [dbo].[ObjectPull]
@ServerName SYSNAME,
@DatabaseName SYSNAME,
@ObjectName SYSNAME
AS
BEGIN
EXEC('SELECT * INTO '+@ObjectName+' FROM ['+@ServerName+'].'+
@DatabaseName+'.dbo.'+@ObjectName)
END
GO
3. MergeData Procedure
Lastly, the MergeData procedure takes the server name, database name, table name, and the clustered index column name. One important point about the code is, the Merge keyword has a restriction of not being able to access any remote tables via linked servers. Hence we have dumped the AppDB table data into a ##Temp table.
Code explanation: The first step is to drop any ##Temp table from the tempdb and then dump the entire table’s data from the source table in the AppDB database into the destination server’s tempdb’s ##Temp table. Then create a loop to build @MatchedString, @UpdateString, and @InsertString.
MERGE SampleDB.dbo.EMP AS Trgt
USING TestDB.dbo.EMP AS Src
ON Trgt.EID=Src.EID
WHEN MATCHED AND (Trgt.ENAME<>Src.ENAME OR Trgt.DEPT<>Src.DEPT) THEN
UPDATE SET Trgt.ENAME=Src.ENAME,Trgt.DEPT=Src.DEPT
WHEN NOT MATCHED THEN
INSERT VALUES (Src.EID,Src.ENAME,Src.DEPT)
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
The highlighted code above shows the kind of code we are trying to build via the loop. This is dynamically built for any table based on the columns in the table. Once that is in place, the Merge statement is built dynamically, taking tempdb.dbo.##Temp as the source and the WareHouseDB’s (current DB where this proc would be running) table as the target. This brings the table in sync with the source.
CREATE PROCEDURE [dbo].[MergeData]
@ServerName SYSNAME,
@DatabaseName SYSNAME,
@ObjectName SYSNAME,
@IndexColumnName SYSNAME
AS
BEGIN
DECLARE @MinCol SYSNAME
DECLARE @MinColID INT = 1
DECLARE @TempVar SYSNAME
DECLARE @MatchedString NVARCHAR(2000)
DECLARE @UpdateString NVARCHAR(2000)
DECLARE @InsertString NVARCHAR(2000)
DECLARE @SqlString NVARCHAR(2000)
IF EXISTS(SELECT 1 FROM tempdb.sys.objects WHERE name LIKE '##Temp')
DROP TABLE ##Temp
EXEC('SELECT * INTO ##Temp FROM ['+@ServerName+'].'+
@Databasename+'.dbo.'+@ObjectName)
SET @SqlString=
'SELECT @MinColOUT=MIN(NAME)
FROM TempDB.sys.columns
WHERE object_id=(
SELECT object_id
FROM TempDB.sys.objects
WHERE name Like ''##Temp%''
)AND Column_ID='+CAST(@MinColID AS VARCHAR(5))
EXEC SP_EXECUTESQL @SqlString,
N'@MinColOUT SYSNAME OUTPUT',
@MinColOUT = @MinCol OUTPUT
SET @TempVar=@MinCol
SET @MatchedString='(Trgt.'+@TempVar+'<>Src.'+@TempVar
SET @UpdateString='Trgt.'+@TempVar+'=Src.'+@TempVar
SET @InsertString='(Src.'+@TempVar
WHILE (@MinColID < = (SELECT MAX(Column_Id) FROM tempdb.sys.columns
WHERE object_id =(Select object_id from
Tempdb.sys.Objects WHERE name Like '##Temp%' )))
BEGIN
SET @MinColID +=1
SET @SqlString=
'SELECT @MinColOUT=MIN(NAME)
FROM TempDB.sys.columns
WHERE object_id=(
SELECT object_id
FROM TempDB.sys.objects
WHERE name Like ''##Temp%''
)AND Column_ID='+CAST(@MinColID AS VARCHAR(10))
EXEC SP_EXECUTESQL @SqlString,
N'@MinColOUT SYSNAME OUTPUT',
@MinColOUT = @MinCol OUTPUT
IF (@MinCol IS NOT NULL)
BEGIN
SET @TempVar=@MinCol
SET @MatchedString=@MatchedString+' OR Trgt.'+@TempVar+'<>Src.'+@TempVar
SET @UpdateString=@UpdateString+',Trgt.'+@TempVar+'=Src.'+@TempVar
SET @InsertString=@InsertString+',Src.'+@TempVar
END
END
SET @SqlString=
'MERGE INTO dbo.'+@ObjectName+' AS Trgt
USING tempdb.dbo.##Temp AS Src
ON Trgt.'+@IndexColumnName+' = Src.'+@IndexColumnName+'
WHEN MATCHED AND '+@MatchedString+') THEN
UPDATE SET '+@UpdateString+'
WHEN NOT MATCHED THEN
INSERT VALUES '+@InsertString+')
WHEN NOT MATCHED BY SOURCE THEN
DELETE;'
EXEC (@SqlString)
END
GO
4. SQL Job
A SQL job could be easily configured as per a desired schedule to run every two days or weekly depending upon the frequency of transaction or network load. This SQL job hosted at the WareHouseDB will invoke the DataSyncController procedure and complete the full pull and delta derivation. This will sync the AppDB and WareHouseDB.
This was a typical example where the Merge keyword could be put to use. It does a great job in delta derivation (change syncing). There could be different approaches to this requirement. I have put forward a very simple, robust, and very flexible dynamic code. Hope this will be helpful to the readers.

