Before a couple of weeks one friend of mine told me, he had a problem with poor database performance. He asked me how to find what cause poor performance and how to fix this problem. I have some knowledge about database tuning and I advised him some recommendations. After some time I had the same problem with poor performance and It was important to fix this problem very soon. After this situation I realized that it would be a great to have same guide so I have decided to write o some article about that.
In this first article about database performance tuning I will describe some techniques about index tuning.
At the beginning is important that you understand indexes. SQL Server 2005 and 2008 supports two types of indexes for most data types: clustered and non-clustered. It also supports full-text indexes and XML indexes, but those types of indexes are relevant only for specific data types.
I think is important to shortly describe some basic terms before we will start discuss about indexing strategies.
The data is present in random order, but the logical ordering is specified by the index. The data rows may be randomly spread throughout the table. The non-clustered index tree contains the index keys in sorted order, with the leaf level of the index containing the pointer to the page and the row number in the data page. In non-clustered index:
- The physical order of the rows is not the same as the index order.
- Typically created on column used in JOIN, WHERE, and ORDER BY clauses.
- Good for tables whose values may be modified frequently.
Microsoft SQL Server creates non-clustered indices by default when CREATE INDEX command is given. There can be more than one non-clustered index on a database table. There can be as many as 249 non-clustered indexes per table in SQL Server 2005 and 999 non-clustered indexes per table in SQL Server 2008. It is appropriate to create non-clustered index on columns which are:
- Frequently used in the search criteria.
- Used to join other tables.
- Used as foreign key fields.
- Of having high selectivity (column which returns a low percentage (0-5%) of rows from a total number of rows on a particular value)
- Used in the ORDER BY clause.
- Of type XML (primary and secondary indexes need to be created; more on this in the coming articles).
Clustering alters the data block into a certain distinct order to match the index, resulting in the row data being stored in order. Therefore, only one clustered index can be created on a given database table. Clustered indices can greatly increase overall speed of retrieval, but usually only where the data is accessed sequentially in the same or reverse order of the clustered index, or when a range of items is selected.
Since the physical records are in this sort order on disk, the next row item in the sequence is immediately before or after the last one, and so fewer data block reads are required. The primary feature of a clustered index is therefore the ordering of the physical data rows in accordance with the index blocks that point to them. Some databases separate the data and index blocks into separate files, others put two completely different data blocks within the same physical file(s). Create an object where the physical order of rows is same as the index order of the rows and the bottom(leaf) level of clustered index contains the actual data rows.
Many developers tent to think that SQL Server stores data according to the order the records were entered into the table. This is not true. SQL Server stores data according to the way you create a clustered index. Keep in mind that SQL Server enforces PRIMARY KEY constraint by placing unique index on table. If there is no other clustered index on table, SQL Server will make PRIMARY KEY index cluster. When creating indexes other that PRIMARY KEY or UNIQUE KEY indexes, by default SQL Server will create them as non-clustered.
It is very important to have a clustered index on every table. If table does not have a clustered index, than all new records have to be added to the last data page occupied by the table. If table has a clustered index, than new records can be added to the last page or in the middle of the table. They can be added to the more suitable position according to he clustered index.
You can extend functionality of non-clustered indexes by including non-key columns to the leaf level of the non-clustered index. By including non-key columns, you can create non-clustered indexes that cover more queries. This indexes are called Covering indexes or Indexes with included columns. The notion of covering indexes is that SQL Server doesn’t need to user lookups between the non-clustered index and the table to return query results. Because a clustered index is the actual table, clustered index always cover queries. Included non-key columns have the following benefits:
- They can be data types not allowed as index key columns.
- They are not considered by the Database Engine when calculating the number of index key columns or index key size.
- A covering indexes always perform better than a non-covering indexes.
When you are creating covering index you should keep in mind some guidelines:
- Non-key columns are defined in the INCLUDE clause of the CREATE INDEX statement.
- Non-key columns can only be defined on non-clustered indexes on tables or indexed views.
- All data types are allowed except text, ntext, and image.
- Computed columns that are deterministic and either precise or imprecise can be included columns.
- As with key columns, computed columns derived from image, ntext, and text data types can be non-key (included) columns as long as the computed column data type is allowed as a non-key index column.
- Column names cannot be specified in both the INCLUDE list and in the key column list.
- Column names cannot be repeated in the INCLUDE list.
- A maximum of 1023 additional columns can be used as non-key columns (a table can have a maximum of 1024 columns).
Performance benefit gained by using covering indexes is typically great for queries that return a large number of rows (by the way this queries are called a non-selective queries). For queries that return only a small number of rows performance is small. But here you can ask, what is the small number of rows? Small numer of rows could be 10 rows for table with hundreds of rows or 1000 rows for table with 1 000 000 rows.
With SQL Server 2008 comes new type of index called Filtered Index. Filtered Index is a non-clustered index, especially suited to cover subset of data determined by simple WHERE clause. The B-tree containing rows for filtered index will contain only rows which satisfy the filter criteria used while creating index and hence well designed Filtered Index can rapidly improve query performance, reduce index maintenance costs and rapidly reduce index storage costs. Filtered index offers some benefits over standard full non-clustered index:
- As discussed above, the filtered index contains only those rows which satisfy the defined filter criteria. As a result it reduces the storage space requirement for the index. In the example below I will explain it more.
- The filtered statistics or statistics for a filtered index are more compact and accurate, because they consider only the rows in the filtered index and the smaller size of the filtered index reduces the cost/overhead of updating the statistics.
- The impact of data modification is less with a filtered index as it is updated only when the data of the index is impacted or a new record is inserted matching the filter criteria.
- Maintenance costs will be reduced as well since only a subset of rows will be in consideration while re-organizing or rebuilding the index.
- And most important, as it is an optimized non-clustered index, the query performance will improve if only a subset of data, which is covered by the filtered index criteria, is required.
In previous versions of SQL Server to get a similar benefit you had an option to use indexed vies. Using indexed views looks similar to filtered indexes but you can find some differences between this tho approaches. Here is a table with some of them:
| Expressions | Filtered Indexes | Indexes Views |
| Only One Column | A Filtered Index is created on
column(s) of a particular table. | Index Views can be created on
column(s) from multiple base tables. |
| Simple WHERE criteria | A Filtered Index can not use complex logic in its WHERE clause, for example the LIKE clause is not allowed, only simple comparison operators are allowed. | This limitation does not apply to indexed views and you can design your criteria as complex as you want. |
| Can do Online Rebuild | A Filtered Index can be rebuilt online. | Indexed views cannot be rebuilt online. |
| Non-Unique or Unique | You can create your Filtered Index as a non-unique index. | Indexed views can only be created as unique index. |
| Computed Columns | Computed Columns aren't supported in filtered indexes. | Indexed views can use Computed Columns. |
| Joins | Are not supported. | Are supported. |
Index Selectivity and Density are one of the basic terms I consider you should know about. Index selectivity represents the number of distinct key values in the table. Therefore a UNIQUE KEY and PRIMARY KEY will be perfectly selective. In general the higher selectivity of an index the better for SQL Server query optimizer. In case when index is not very selective query optimizer might decide that would be a more effective to provide table scan than index seek.
Index Density represents number of duplicate key values in the table. Therefore, more selective indexes will have lower density. Usually the best indexes will be ones with highest selectivity.
The fill factor option is provided for tuning index data storage and performance. The fill-factor value determines the percentage of space on each leaf-level page to be filled with data, reserving the remainder on each page as free space for future growth. For example, specifying a fill-factor value of 80 means that 20 percent of each leaf-level page will be left empty, providing space for index expansion as data is added to the underlying table. The empty space is reserved between the index rows rather than at the end of the index. The fill-factor value is a percentage from 1 to 100, and the server-wide default is 0 which means that the leaf-level pages are filled to capacity. Fill-factor values 0 and 100 are the same in all respects.
The fill-factor setting applies only when the index is created, or rebuilt. The SQL Server Database Engine does not dynamically keep the specified percentage of empty space in the pages. Trying to maintain the extra space on the data pages would defeat the purpose of fill factor because the Database Engine would have to perform page splits to maintain the percentage of free space specified by the fill factor on each page as data is entered. Here are some information you should take into consideration when you modifying fill factor:
- Depending on how the data is inserted, updated and deleted in the table dictates how full the leaf level pages should be in the table. To fine tune this setting typically takes some testing and analysis. This could be critical for large active tables in your database.
- If data is always inserted at the end of the table, then the fill factor could be between 90 to 100 percent since the data will never be inserted into the middle of a page. UPDATE and DELETE statements may expand (UPDATE) or decrease (DELETE) the space needed for each leaf level page. This should be fine tuned based on testing.
- If the data can be inserted anywhere in the table then a fill factor of 60 to 80 percent could be appropriate based on the INSERT, UPDATE and DELETE activity. However, it is necessary to conduct some testing and analysis to determine the appropriate settings for your environment.
- With all things being equal i.e. table size, SQL Server versions, options, etc., the lower the fill factor percentage the more storage that could be needed as compared to a higher fill factor where the pages are more compact.
- Another aspect to take into consideration is your index rebuild schedule. If you cannot rebuild your indexes on a regular schedule and if you have a high level of INSERT, UPDATE and DELETE activity throughout the table, one consideration may be to have a lower fill factor to limit the fragmentation. The trade-off may be that more storage is needed.
Creating indexes is a vital for system performance and future maintenance (we will discuss about it later in this article) of your SQL server database. Choosing appropriate indexes can improve your application performance significantly, often by order of magnitude. This is not as simple task as it might sound. There are several points you must consider when choosing indexes. Each index you define can improve performance of a SELECT query, but on the other hand can decrease performance of INSERT and UPDATE queries. The reason for this is that SQL Server automatically maintains index keys. Therefore, each time you issue a data modification statement, not only data modification SQL Server provides, but also index it updates each index defined on affected table. The performance degradation is noticeable in case of large tables with many indexes., or few indexes with long keys. In some cases it is suitable to drop index before updating or inserting new records and than recreate index. This is in case of large tables where you need to update or insert a large amount of data. You will find out that insert into table without indexes will be much more faster than into table with indexes.
There are a several tips you should keep in mind when implementing indexing.
- Keep indexes lean. Try to build indexes on one or few columns at most. Wide indexes take longer to scan than narrow indexes.
- Create the clustered index on every table. However, choose the column(s) for the clustered index judiciously. Try to create the clustered index on the column which is used most frequently for retrieving data.
- Try to create the clustered index on the column with high selectivity; that is the column that does not have many duplicate values.
- Try to create the clustered index on the column that will never be updated or will be updated infrequently. Every time the clustered index key is updated, SQL Server must maintain not just the clustered index but also the non-clustered indexes since non-clustered indexes contain a pointer to the clustered index. This is yet another reason why you shouldn't create the clustered index on multiple columns.
- By default, SQL Server creates the clustered index on the PRIMARY KEY column(s) unless the clustered index is created prior to creating the primary key. It is often beneficial to have the clustered index on the primary key, but sometimes you're better off saving the clustered index for other column(s). Feel free to override the default behavior if your testing shows that clustered index on a non-key column will help your queries perform better.
- SQL Server has to perform some maintenance when index keys are updated, so each additional index could impose a slight performance penalty on the performance of INSERT, UPDATE and DELETE statements. Nevertheless the cost of index maintenance could be far less than the performance improvement you'll reap for your SELECT statements. Therefore you can be fairly liberal with the number of non-clustered indexes.
- Be sure to eliminate duplicate indexes, that is, multiple indexes created on the same set of columns. Such indexes provide no additional benefit but use up extra disk space and might hinder performance of INSERT, UPDATE and DELETE statements.
- Check the default fill factor level configured at the server level. If you don't specify the FILLFACTOR option with CREATE INDEX statement, every new index will be created using the default fill factor. This may or may not be what you intend.
- Non-clustered indexes can be created in different file groups which can reside on separate disk drives to improve the data access i.o. I/O operations.
In a couple of articles I have found that the identity column is the best choice for clustered index, but you must keep in mind that this way shouldn’t be the best way because it force users to enter new data into the last data page of the table. This condition is sometimes referred to as a “hotspot” since there may be multiple users competing for the last available spot on a page and therefore making INSERT statements slow.
In some cases you can find tables that are never queried based on one column. In this case some developers prefer to create clustered index on set of columns that are most frequently used for data retrieving and uniquely identifies each record. This types of indexes are called composite clustered indexes. Maybe you consider this as a good idea because identity column has no business meaning in most cases. However, from a performance view you should avoid composite clustered indexes. Generally speaking, the leaner index, the faster SQL Server can scan or seek through it. For small tables (or data sets) composite indexes perform relatively well, but as number of records grows, performance decreases.
Creating indexes has some limitations. Not every columns can be added on index. Especially columns that are of the ntext, text, image, varchar(max), nvarchar(max), and varbinary(max)data types cannot be specified as index key columns. However, varchar(max), nvarchar(max),varbinary(max), and xml data types can participate in a nonclustered index as nonkey index columns.
It is very important to choose appropriate order of fields on each index. Bad order causes that index could be unused. First rule is that the most selective columns should go first. This rule sometimes can lead to misunderstanding that every index should contains most selective column as a leading column. Let’s consider you have table with 3 columns: ID, fname and lname. ID is most selective column with clustered index. Now you want to create non-clustered index for fname and lname. lname has higher selectivity than fname. If you want to create non-clustered index for the rest two columns, place lname on the first name and fname on the second. Don’t place ID column on index. Be very careful which column you place on the first name. This is because of the SQL server keeps histogram only for first column of an index. That means, that SQL Server knows only the actual distribution of values of the first column. If the first column is not selective, the index may not be used.
Here I will show you some basic examples which demonstrate how indexes can affect performance of queries. For test purposes I have created table [Person].[Person_Test] in database AdwentureWorks2008R2. This table has the same structure as [Person].[Person]. I have created this table because I don't want to change existing table.
If you run a query on table with no indexes, SQL Server does Table Scan against the table to look through every row to determine if any of the records have last name of "Brown". As you can see on picture below, This Query has an Estimated Subtree Cost of 2.84525. This value represents the total cost of the query optimizer for executing this query and all operations preceding it on the same subtree. The lower the number, the less resource intensive is execution of query for SQL Server.
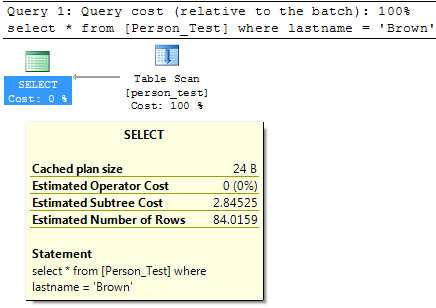
In this example we will create a non-cluster index on LastName column.
CREATE NONCLUSTERED INDEX [IX_Person_Test_LastName] ON [Person].[person_test]
(
[LastName] ASC
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
When you run this query, SQL Server uses index to do the Index Seek (instead of Table Scan) and after this operation It will need to do RID Lookup to get the actual data. On picture below you can see Estimated Execution Cost of 0.299353 that indicates, that this query performs much more better with index (in this case non-clustered index on LastName column).

Here I will demonstrate you how clustered index can affects performance. Before executing query You have to create a clustered index on LastName column.
CREATE CLUSTERED INDEX [IX_Person_Test_LastName_Clustered] ON [Person].[person_test]
(
[LastName] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
When this query runs, SQL Server does an Index Seek. The great thing is that index point directly to the actual data pages. As you can see, tha Estimated Subtree Cost is only 0.0155815. Using clustered indexes is the fastest access method for this type of query.
In this example we are only requesting LastName column. Since this query can be handled by just the non-clustered index, SQL Server does not need to access the actual data pages. Based on this query the Estimated Subtree Cost is only 0.0033832. As you can see this even better then previous example.
To take this a step further, the below output is based on having a clustered index on lastname and no non-clustered index. You can see that the subtree cost is still the same as returning all of the columns even though we are only selecting one column. So the non-clustered index performs better.
When you run this query, SQL Server uses index to do the Index Seek and after this operation It will need to do RID Lookup to get the actual data. On picture below you can see Estimated Execution Cost of 0.29934.
In this example you will see how covering index can improve performance of the query. Following script allows you to create covering index.
CREATE NONCLUSTERED INDEX [IX_Person_Test_LastName_Include_FirstName] ON [Person].[person_test]
(
[LastName] ASC
)INCLUDE (FirstName) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
In this query we are requesting 2 columns (LastName and FirstName). This query can be handled just by non-clustered index, because this index contains information about data pages of both columns. The Estimated Subtree Cost is 0.0033832 which is much more lower than in previous example.
In this example I will show you how to create filtered index and how can this type of index improve performance. Let's consider following query:
SELECT LastName from person.person_test where modifieddate<'2005-01-01'
In case there is no non-clustered filtered index on table SQL Server does full Table Scan. If you have a millions records in table, it could take a long time.
To improve query performance you can create non-clustered filtered index:
CREATE NONCLUSTERED INDEX [IX_Person_Test_LastName_Filtered_ModifiedDate] ON [Person].[person_test]
(
[LastName] ASC
)WHERE ModifiedDate <'2005-01-01' WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, önLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
As you can see the Estimated Subtree Cost is much more lower in case of non-clustered filtered index than in case without index.
When you are creating indexes, often the default options are used. This options create index in ascending order. This is usually the most logical way if creating an index, but in some cases this approach wouldn’t be the best. For example when you create index on ColumnA of TableA using default options, the newest data are at the end. This works perfectly when you want to get data in ascending order from the last recent at the top to the most recent at the end. But what if you need to get the most recent data at the top?. In this case you can create index in descending order. In a few following examples I will show you hot to create indexes in different order and how they can affect performance of queries. For all following examples I will use PurchasingOrderHeader of AdventureWorks2008R2 database.
In this first example we are just requesting OrderDate column of PurchasingOrderHeader.
You can see that Estimated Subtree Cost is 0.0380656. But what will happen if we use Order By clause? Let’s try to investigate.
When we user Order By clause SQL Server will sort requested data. As you can see, the sort operation is the most resource sensitive operation in this case and the overall Estimated Subtree cost is increased. To improve this query's performance we can create a non-clustered index on OrderDate column.
CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate]
ON [Purchasing].[PurchaseOrderHeader]
( [OrderDate] ASC )
If we run query again we will see that Estimated Subtree Cost is better than before because SQL Server query optimizer doesn't perform Sort operation. It just do Index Seek.
But here you can ask what if you need data in descending order. You can apply the same technique for indexes using descending order. I will show you that they can affect performance on the same way as indexes using ascending order.
When you run query which sorts records using descending option you can see that Estimated Subtree Cost is the same as in case of ascending order without index. For increasing performance of query you can create non-clustered index using descending option:
CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate]
ON [Purchasing].[PurchaseOrderHeader]
( [OrderDate] DESC )
History
- 7 August 2011 - Original version posted.
- 9 August 2011 - Filtered Indexes chapter updated.

