Introduction
We had an interesting (read: aggravating) issue with search engines. Some could see us, some couldn't. It was driving us nuts. Below is a quick summary of what we saw, what we tried, and what finally fixed the issue.
Let us be a warning for others.
Google
Google has a nice system that allows you to check up on what they are indexing and see what errors they are seeing. What we saw was over a million "page not found" errors. Clearly we don't have a million pages but we do have pages that can be called in different ways with different querystring values so part of this million was made up of mal-formed requests for some of our pages.
As the days went by after the upgrade we saw this number of not founds diminish rapidly and this was a Good Thing. There was, however, one page that was being reported as missing that really stumped us: www.codeproject.com
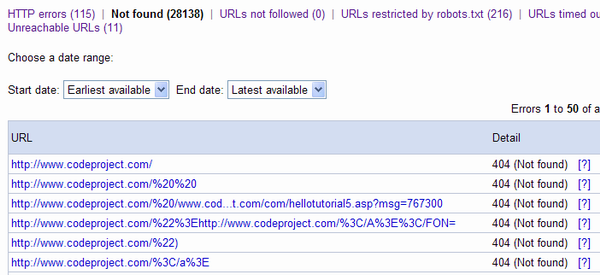
We looked everywhere. On the servers, on our test machines, under the couch. Everywhere we looked we could see the homepage. Our old index.asp was being sent to the new index.aspx correctly. Our default document was set correctly so that www.codeproject.com would go to www.codeproject.com/index.aspx. We tried accessing the homepage via proxies, via raw HTTP clients, via web-based screen captures. We even checked our logs and clearly the homepage was not missing, yet Google was reporting a 404 error.
One thought we has was that the page was being served correctly for Human Beings but not for search bots. We sent requests to our servers using the same user agent that Google would use and everything was fine.
We considered that we had been black-banned. We have the domains codeproject.com, www.codeproject.com, www.thecodeproject.com and others and, for convenience, point them to the same content. This is (now) an absolute no-no so we feared that our inadvertent convenience had caused a problem. We removed the automatic redirect from these alternate domains (much to many's discontent) and knew that if we had been banned it could be weeks before we saw any improvement.
We then considered that maybe Google was unable to actually get to our servers because of network issues. However, every so often a new version of a page would pop up on Google so clearly they were seeing us. We were also seeing Googlebot appearing in our logs so they were here.
We did see that one page was consistently and embarrasingly being indexed. It was our error page. A simple, no fuss "oops, we have a problem" page.
We considered the index problem may be a load issue. Maybe they hit us so hard that they were overloading the servers and only getting error pages. This didn't seem right, though, because it was easy to spot when we were being spidered and site performance was essentially unaffected by their spidering.
We then, luckily, saw another page that was being indexed. It was a page about templates whose title included "<>". It was the only page being indexed. Everything else was 404.
ASP.NET Custom Error Handling is Bad
The plot then thickened. We realised that the standard ASP.NET custom error system would return an error 302 (Page Found but temporarily moved) error instead of a 404 error. Google was reporting a 404 error yet our system was actually incapable of generating an actual 404.
An aside: If you run an ASP.NET site then do yourself a favour and do some reading on how ASP.NET handles custom errors. Then, rip out the standard ASP.NET way of doing it and handle your errors in your Application's Application_Error (global.aspx.cs) and your page's OnError. This is a topic for another article.
So what was going on?
Yahoo could see us. Everyone else could see us. Google could get to us. The pages were being served correctly. Yet Google was reporting our homepage as 404 Not Found.
Back in October 2007 I made a small change to our meta tags. Originally they were in the form
<meta name="Keywords" content="Free source code, tutorials" >
but I changed these to
<meta name="Keywords" content="Free source code, tutorials" />
in preparation for moving to XHTML.
XHTML
XHTML requires, among other things, that all tags are either self closing ("<tag />") or have a closing tag (<tag>...</tag>). HTML 4 allows unclosed tags (eg <img ...>) but pretty much every modern browser you are likely to use has no problem if you close a tag in an HTML document that doesn't need closing. In fact modern browsers let you get away with absolute murder when it comes to HTML and this is where the issue started.
To specify whether your HTML page is HTML or XHTML you provide a DOCTYPE declaration at the top of the page. eg
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
for HTML 4.01, or
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
for strict adherence to the XHTML format.
The Problem
The problem we faced was that we had specified HTML 4.01 in our DOCTYPE but were trying to use XHTML style tags (i.e. self closing meta tags). IE had no problem with it. Firefox, Opera and even my blackberry had no problem with it (or if they did have a problem they were polite enough not to say anything). Yahoo didn't have a problem.
But Google did.
Google saw the DOCTYPE as being HTML 4.01. It then saw meta tags with a trailing "/>". It became scared and confused and decided that the only thing to do was report the page as not found.
Our custom error page had no meta tags so it was fine. Our article about templates had <> in the title which caused Googlebot enough confusion that it forgot about the self-closing meta tags and indexed the article.
We removed the "/"s from the meta tags and within 24hrs we were reindexed.
Another Problem
We thought we had solved the issue. Our homepage had been found and we were getting some Google love again. Unfortunately our articles were not being found.
The issue turned out to be a related problem: We included javascript that was of the form
document.write("<tag value=...
The problem here is that Googebot seemed to be having problems with this. We assumed Googlebot would ignore the javascript but a search engine trying to stop page hijacking and scams cannot afford to ignore javascript. The specific problem was that the open "<" was messing the parser so again a quick solution:
document.write(unescape("%3Ctag value=...
Our articles are now being indexed and, again, the Google love.
Lessons Learned
The obvious lessons learned in this exercise are:
- Don't blindly trust reporting tools. Use them as a guide and use them in conjunction with other standard tests
- Learn your HTML. If you want to use XHTML then do it properly. If you can't use XHTML (for example, if you don't have 100% control over the markup you are presenting) then choose a DOCTYPE and stick to that DOCTYPE.
- Encode your HTML correctly. URLs that contain '&' in their query strings need to be specified as '&'. Angle brackets in Javascript should be escaped.
- Validate your HTML. We are guilty of serving non-validating HTML but that which isn't validating correctly isn't affecting our search results or user experience. Yet. We are now moving to fix this.
The biggest problem for us was in recognising that there was a problem in the first place. The lag between problems appearing and it affecting search results can be in the order of weeks or months so there was a tendency to blame those factors most immediate - the rewrite, server issues, new servers - when in fact it was a pre-existing condition completely unrelated to our upgrade.
Another problem was a lack of appreciation for standards. W3C has HTML validators that we knew we failed but there was always a feeling of "so what?" The site rendered perfectly fine on the browsers we had access to. Why should this cause a problem?
And the final problem, for us, was Google's error reporting and feedback mechanism. We tried contacting Google a number of times but have still had absolutely no response from them. They are the biggest in the world so have the biggest customer service load in the world but they also have the resources to manage this better than they currently do. Making matter worse was the mis-reporting of the issues we found. A simple "HTML validation error" would have allowed us to spot the mistake faster.
Whether we like it or not, the information accessed on the internet is mostly controlled by what Google suggests in its search results. In the end it was a little worrying to see that the biggest search engine was the most fragile in terms of its ability to index information. It may pay to consider this when next you google something online.

