This article presents a set of language agnostic coding guidelines. Code that is produced using these guidelines will be more maintainable than code written without using these guidelines.
This article presents a set of language agnostic coding guidelines. I have no doubt that some developers will take issue with one or more of these guidelines. But each has a rationale that may help lessen the angst. However, if adopted in toto, I assure that code that is produced will be much more maintainable than code written without using these guidelines.
Introduction
I know. I know. Most programmers view coding standards and guidelines as intrusions upon their creative and artistic talents. But consider for a moment that most probably these programmers are developing software for someone else (e.g., a company, a client, etc.) as a work for hire. If that is the case, the software that is developed is not an artistic work in the sense that the programmer can copyright it. Furthermore, the programmer does not own the software. And lastly, the programmer is under pressure (aka a fast-paced environment) wherein thoughts of maintainability are put aside for another day that usually never comes.
Author's Background and Perspective
I believe that most programmers try to produce maintainable code. But if they are not using coding standards, they generally fail in their attempt. Maybe it's because today's programmers enter the work force differently than in the past. As recently as the late 1990's, entry level programmers were assigned to maintenance tasks. Seldom were they given responsibilities for the development or design of original software. The result? Programmers learned from the mistakes of others - most importantly as how not to code software. And in most instances, these maintenance programmers vowed that they would never do to others as others had done to them.
Software that is not being developed is being maintained. Software is maintained because it contains an error. I define an error as either a failure on the part of a programmer to correctly implement a requirement or a failure on the part of the architect or designer to correctly state a requirement. In programmer parlance, the former is simply a "bug"; the latter is euphemistically called an "enhancement."
So what do coding standards do for a programmer? Note that there must be some payoff or else there is really no reason for a programmer to spend the time to comply. The payoff is simply readability. And readability increases maintainability. Regardless of whether you are the original developer or a programmer assigned to repair or enhance software, you must understand what the code does before you can modify it.
Many years ago, as a graduate student, I wrote a rather complex piece of software that would fit a high-speed rail transportation guideway into a right of way composed of multiple parcels. The path of the guideway had to minimize lateral acceleration. The problem, illustrated in the following figure, is that it is normally impossible to purchase parcels that allow a straight-line guideway (the dotted line). Rather we must resort to purchasing a number of parcels that allow a guideway to connect the two ends (the solid line).
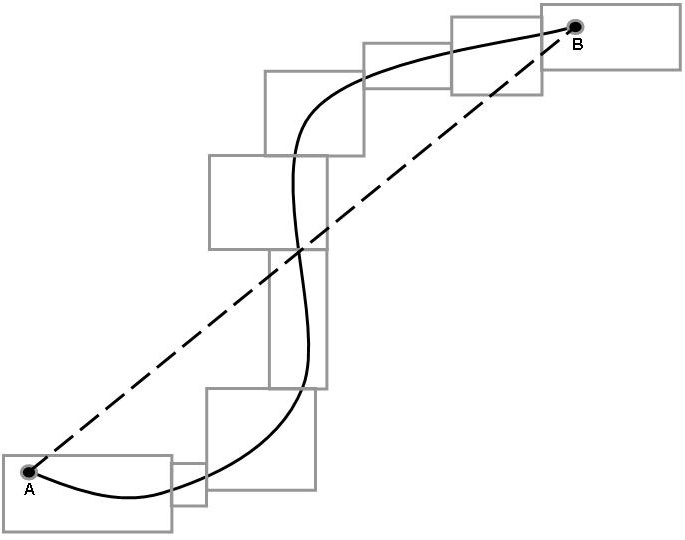
I was pleased with the software; it did what it was supposed to do. A few years later, a problem came up that could be solved using this software with minor modifications. I reopened the software and found to my horror that it was unusable. At the time I was coding the original software I had no consideration for style, especially style that aided following programmers (including me) to understand the solution. The result was a truly unnecessary "reinvention of the wheel."
About the same time that I found myself frustrated by my own coding style, a book named The Elements of Programming Style was published. The authors (Brian Kernighan and P. J. Plauger), both respected computer scientists, wrote a set of guidelines that, had I followed them, would have allowed me to recover my earlier code. To me, the greatest lesson in the book was: "write software as if you were writing for someone else - for in six months you will be someone else!"
What does it mean to write for someone else? I suggest that it means to use a clear writing style and consistent formatting scheme. That's what these guidelines are all about.
The Guidelines
What follows are coding guidelines that are, hopefully, language agnostic. Specific examples may use C or C# as their exemplar languages. But the guidelines themselves are not tied to either C or C#.
Acknowledgement
I wish to acknowledge the contribution of Derek M. Jones of Knowledge Software whose web pages located at
These pages provided the basis for much of the rationale for these guidelines.
The Prime Objective
Consistency is the most important guideline in the clear writing of computer programs. If the original programmer mixes styles, the following maintenance programmer is more easily distracted from repair. This raises the cost of maintenance.
Identifier Spelling
I don't think that there is any disagreement that the identifiers should be self-describing. The major disagreements appear to come when identifier spelling is the issue. Camel-case. Pascal-case. Uppercase. Lowercase. Underscores. Hungarian notation. All are methods that appeal to one or another segment. But it also appears that the evangelists for one method over another are merely espousing some personal preference and not stating some fact but stating an opinion. I believe that this is inconsistent with a rational approach to the issue.
- Create identifiers from complete English Words.
- Limit the use of abbreviations to an authorized set.
Rationale
Pronounceability is an easy-to-apply method of gauging the extent to which a spelling matches the characteristics of character sequences found in a developer's native language. Given a choice, character sequences that are easy to pronounce are preferred to those that are difficult to pronounce.
- Separate English words with underscores. This form of separation distinguishes programmer defined identifiers from system defined identifiers that usually represent entry points into, say, APIs.
- Use lowercase letters for variable identifiers.
- Use title case (first-letter capitalization) for enum, struct, class, interface, delegate, namespace, etc. identifiers.
- Use uppercase letters for enum value identifiers and const variable identifiers.
- Use uppercase letters for abbreviations.
Rationale
Written English separates words with white space. When an identifier spelling is composed of several distinct subcomponents, using an underscore character between the subcomponents is the closest available approximation to a reader’s experience with prose (i.e., separation by spaces).
Some developers capitalize the first letter of each subcomponent. Such usage creates character sequences whose visual appearances are unlike those on which readers have been trained. For this reason, additional effort will be needed to process them. In some cases, the use of one or more additional characters may increase the effort needed to comprehend constructs containing the identifier (perhaps because of line breaks needed to organize the visible source).
- Choose identifiers that are self-contained and meaningful.
Rationale
There are benefits to readers of identifier spellings that evoke semantic associations. However, reliably evoking the desired semantic associations in different readers is very difficult to achieve. Given a choice, an identifier spelling that evokes, in many people, semantic associations related to what the identifier denotes is preferred to spellings that evoke them in fewer people or commonly evokes semantic associations unrelated to what the identifier denotes.
- Distinguish identifiers by their initial letters.
Rationale
The start of English words is more significant than the other parts for a number of reasons. The mental lexicon appears to store words by their beginnings and spoken English appears to be optimized for recognizing words from their beginnings. This suggests that it is better to have differences in identifier spelling at the beginning (e.g., cat, bat, mat, and rat) than at the end (e.g., cat, cab, can, and cad).
Rationale
In any context, a word should have a single meaning. For instance, it is not necessary to know the meaning (after preprocessing) of a, b and c, to comprehend a=b+c. This statement is not necessarily true in computer languages that support overloading.
Indentation (See Visual Studio, below)
- Use a consistent indentation scheme that enhances edge detection.
Rationale
The visual receiving area of the brain responds selectively to the orientation of edges. In one theory of perceptual organization, edge detection is the first operation performed on the signal that appears as input to the human visual system. Source code is read from left to right, top to bottom. It is common practice to precede the first non-whitespace character on a sequence of lines to start at the same horizontal position. This usage has been found to reduce the effort needed to visually process lines of code that share something in common; for instance, statement indentation is usually used to indicate block nesting.
Edge detection would appear to be an operation that people can perform with no apparent effort. An edge can also be used to speed up the search for an item if it occurs along an edge. In the following two sequences of declarations, less effort is required to find a particular identifier in the second block of declarations. In the first block, the reader first has to scan a sequence of tokens to locate the identifier being declared. In the other block, the locations of the identifiers are readily apparent.
Block Declaration
1 private List < Color > known_colors;
private Panel [ ] panels = null;
private Sort_By sort_by = Sort_By.HSL;
private ToolTip tooltip = new ToolTip ( );
2 private List < Color > known_colors;
private Panel [ ] panels = null;
private Sort_By sort_by = Sort_By.HSL;
private ToolTip tooltip = new ToolTip ( );
Edge detection also improves comprehension in reading method declarations. In the following two declarations, less effort is required to understand the declaration in the second declaration. In the first, the reader first has to scan a sequence of tokens to locate an identifier. In the second, the identifiers are readily apparent.
Block Declaration
1 [ DllImport ( "gdi32.dll", EntryPoint = "BitBlt" ) ]
public static extern bool BitBlt ( IntPtr hdcDest, int nXDest,
int nYDest, int nWidth, int nHeight,
IntPtr hdcSrc, int nXSrc, int nYSrc,
int dwRop );
2 [ DllImport ( "gdi32.dll",
EntryPoint = "BitBlt" ) ]
public static extern bool BitBlt ( IntPtr hdcDest,
int nXDest,
int nYDest,
int nWidth,
int nHeight,
IntPtr hdcSrc,
int nXSrc,
int nYSrc,
int dwRop );
- Use a consistent scheme for statement indentation.
Rationale
There are two common statement indentation schemes. They take the following forms:
if ( x ) if ( x )
{ {
if ( y ) if ( y )
{ {
F ( ) ; F ( );
} }
else else
{ {
G ( ) ; G ( );
} }
} }
One of these two forms must be chosen to be used to indent statement bodies. There is no preferred way to indent statement bodies. Rather, the developer's preference is the determining factor. Again, the single rule is simply to be consistent.
White Space (See Visual Studio, below)
- Use only the space character as white space.
Rationale
One of the ISO standards defines white space as the space character, the horizontal tab character, the vertical tab character, and the form feed character and suggests that they may be used to separate tokens. Using any of these characters, other than the space character, may cause the loss of a consistent indentation scheme.
There was a historic reason for using horizontal tabs in source code - the limited amount of available rotating mass storage. That reason no longer exists. Most computers are attached to giga- and even tetra-byte mass storage devices. As a result, source code no longer needs to conserve disk space. Additionally, using spaces has a significant advantage. Indentation using spaces creates a consistent indentation scheme, no matter what the display device may be (e.g., monitor, printed page, etc.).
For example, say that tabs are defined every eight character positions (the normal tab setting for a laser printer). A maintenance programmer makes a modification but uses spaces rather than tabs for indentation. It is quite possible that the new or modified lines will have an inconsistent indentation with respect to the rest of the code.
Another difficulty with tabs is how the display device interprets them. Let's say that a programmer sets the source code editor tabs to four character positions. Coding proceeds as normal. The programmer prints copies of the source code for a design review. Most laser printers define tabs every eight character positions. The result of printing the code is a significant rightward indentation, to the point that the programmer is faced with two options: print the code in landscape mode or reformat the source code. Neither is a particularly welcome task. What's worse, the problem could have been avoided by using spaces for indentation.
Source Code Line Length
- Limit source code lines to 70 characters.
Rationale
The "standard" letter size paper measures 8-1/2 x 11 inches and "standard" page margins are 1 inch on a side. A recommended minimum font size is 11 points. When source code is printed, the printed page is normally rendered in Courier New. When these provisions are met, the maximum width of an unbroken printed line is 70 Courier New characters.
On a monitor, requiring following programmers to scroll to the right to read a source code line is as arrogant as requiring a web page reader to scroll to the right. We don't do this to our web site visitors. Why do it to fellow programmers?
Breaking Lines
- When a source code line must be broken, to meet the preceding Source Code Line Length guideline, break the line after one of the following operators and punctuators:
{ [ ( . , : ;
+ - * / % & |
^ ! ~ = < > ?
?? :: ++ -- && || ->
== != <= >= += -= *=
/= %= &= |= ^= << <<=
- or after one of the keywords that indicate that the statement is not complete:
as in is new
Rationale
When source is being read, the reader gains a valuable visual clue that the line has been broken if one of these operators, punctuators, or keywords is the last token on the line.
Token Separation (See Visual Studio, below)
- Separate following tokens from a comma by a space character.
- Separate binary operators from their operands by a space.
- Separate all other tokens from each other by a space character.
Code Folding
Rationale (used with permission)
What I only realized afterwards was that code folding was encouraging me to write bigger and bigger methods, and not bother to break them up into smaller bite-sized methods. The result was that I too often ended up with "write-once-maintain-never" programs with big monolithic methods.
Code folding has begun to reappear in modern IDEs. This is odd, because the problems that code folding originally addressed have since been eradicated in other, much neater, less transient ways - namely, object-oriented design.
If you're staring at your program and can't see the wood for the trees, code folding is the wrong answer. The answer is to structure your program better; encapsulate the details into different classes, use interfaces, small methods, and so on.
The other thing about code folding is that you end up wasting a lot of time folding methods, unfolding them, when this isn't really getting you anywhere. It feels like you're doing work because you're actively clicking away; but you're not actually making any progress. It's like trying to rearrange the contents of a cupboard by constantly opening and closing the cupboard doors.
Visual Studio
Earlier, in these guidelines, I've referred to this paragraph. Visual Studio provides assistance in meeting some of these guidelines. The white space and indentation guidelines can be automated within the Microsoft Visual Studio IDE. Under Tools→Options→Text Editor are a myriad of settings that control the formatting of source code. I strongly recommend that programmers take time to review these settings. One of the advantages is simply if you do not like the formatting of code given to you, you can simple cut all (Ctrl-A; Ctrl-X) and paste (Ctrl-V) the code. If your text editor settings are what you want, then Visual Studio IDE reformats the code to your liking (this can also be accomplished from the Edit→Advanced menu item).
Conclusion
As said earlier, there is no "right way" to format computer programs, no matter what the evangelists say. The only important rule is consistency. That rule, if violated, will result in unreadable code. And unreadable code is unmaintainable code.
I have been programming computers for decades. As I indicated earlier, developing usable guidelines was a defense against myself mechanism. But something has happened a number of times that increases my confidence in these guidelines. A few years after I left one project, written in Ada, I received a call from the programmer who was maintaining the driver I had written. He had recognized my coding signature and called to say "thank you." Although the driver was many hundreds of lines long, he was able to maintain the code easily.
History
- 08/04/2011 - Original Article

