Introduction
Since its inception, XML has been criticized for the overhead it introduces into the enterprise infrastructure. Business data encoded in XML takes 5 to 10 times more bandwidth to transmit in the network, and proportionally more disk space to store. While most agree that verbosity is inherent to XML's way of encoding information (e.g., extensive use of tags and pointy brackets), the explanation of XML's perceived performance issue remains inconclusive. A popular belief is that since XML is human-readable text, it has to be slow and inefficient. By the same token, proponents of binary XML seem to suggest that a compact encoding format, most noticeably the binary XML, would automatically lead to better processing performance.
Does it make sense for doctors to prescribe medicine without a diagnosis? Whether those perceptions and beliefs have a grain of truth or not, one thing is certain: without a solid understanding of XML's performance issue, it will be difficult, if not impossible, to devise meaningful solutions. So in this article, I'll attempt to dissect XML's performance issue by focusing on the following three key questions:
- Does XML have a performance issue?
- What is the real culprit behind XML's slow performance?
- Can binary XML fundamentally solve the problem?
Performance is Not an XML Issue Per Se
In networking system design, the OSI (Open System Interconnect) stack is the standard model that divides the functions of the network into seven layers. Each layer only uses the layer below, and only exports functionalities to the layer above. Compared with monolithic approaches, the advantages of OSI's layered approach are the robustness, resilience, and extensibility of the networking system in the face of rapid technology evolution. For example, any Voice over IP application will work without knowing the physical layer of the networks (e.g., using copper, fiber cable, or Wi-Fi) or the data link layer (e.g., Ethernet, Frame Relay, or ATM).
Likewise, we can take a similar layered approach to modeling XML-based applications. Figure 1 is a simplified view of this "XML protocol stack" consisting of three layers: the XML data layer, the XML parsing layer, and the application layer. The application layer only uses functions exported by the XML parsing layer, which translates the data from its physical representation (XML) into its logical representation (the infoset).

Figure 1. XML Application Stack
Several observations can be made concerning the perceived performance issue of XML. First and foremost, because the XML application can only go as fast as the XML parsers can process XML messages, performance is actually not an issue of XML per se, but instead an issue of the XML parsing layer. If an XML routing application (assuming minimum overhead at the application layer) can't keep pace with incoming XML messages at a gigabit per second, it's most likely because the throughput of XML parsing is less than that of the network. Consequently, the correct way to boost the application performance is to optimize the XML parsing layer. Just like tuning any software application, the best way to do it is to discover and then find ways to reduce or eliminate the overhead in XML parsers.
Object Allocation - The Real Culprit
To get a feel of the performance offered by current XML parsing technologies, I benchmarked the parsing throughput of the two types of widely used XML parsers: Xerces DOM and Xerces SAX. The benchmark applications are quite simple. They first read an XML document into memory, and then invoke parser routines to parse the document for a large number of iterations. The parsing throughput is calculated by dividing the file size by the average latency of each parsing iteration. For SAX parsing, the content handler is set to NULL. Several XML documents in varying sizes, tagginess, and structural complexity were chosen for the benchmark. The results, produced by a two-year old 1.7GHz Pentium M laptop, are summarized in Figure 2. The complete report -- which includes test setup, methodology, and code -- is available online here.
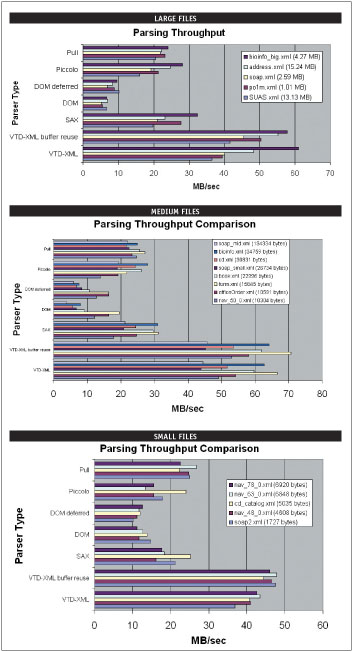
Figure 2. Parsing Performance Comparison Between DOM, SAX, Pull, and VTD-XML
The benchmark results are quite consistent with the well-known performance characteristics of DOM and SAX. First of all, the raw parsing throughput of SAX, at between 20MB/sec~30MB/sec, is actually quite respectable. However, by not exposing the inherent structural information, SAX essentially treats XML as CSV with "pointy brackets," often making it prohibitively difficult to use and unsuitable as a general-purpose XML parser. DOM, on the other hand, lets developers navigate in-memory tree structures. However, the benchmark results also show that, except for very small files, DOM is typically three to five times slower than SAX. Because DOM parsers usually use SAX internally to tokenize XML, by comparing the performance differences, it's clear that building the in-memory tree structure is where the bottleneck is. In other words, allocating all the objects and connecting them together dramatically slows everything down. As the next step, I ran JProfiler (from ej-Ttechnologies) to identify where DOM and SAX parsing spend all the CPU cycles. The results confirmed my early suspicion that the overhead of object allocation overwhelmingly bottlenecks DOM parsing and, to a lesser (but still significant) degree, SAX parsing as well.
Some readers may argue that DOM -- only an API specification -- doesn't preclude efficient, less object-intensive, implementations. Not so. The DOM spec is, in fact, based completely on the assumption that the hierarchical structure consists entirely of objects exposing the Node interface. The most any DOM implementation can do is alter the implementation of the object sitting behind the Node interface, and it's impossible to rip away the objects altogether. So, if the object creation is the main culprit, the DOM spec itself is the accomplice that makes any performance-oriented optimization prohibitively difficult. This is why, after the past eight years and countless efforts by all major IT companies, every implementation of DOM has only seen marginal performance improvement.
Binary XML Solves the Wrong Problem
Can binary XML fundamentally solve the performance issue of XML? Well, since the performance issue belongs to XML parsers, a better question to ask is whether binary XML can help make parsing more efficient. The answer has two parts: one for SAX, and the other for DOM.
Binary XML can improve the raw SAX parsing speed. There are a lot of XML-specific syntax features that binary XML can choose not to inherit. For example, binary XML can replace the ending tags with something more efficient, entirely avoiding attributes so SAX parsing no longer does uniqueness checking, or find other ways to represent the document structure. There are many ways to trim CPU cycles off SAX's tokenization cost. Proponents of binary XML often cite up to a 10x speed-up for the binary XML version of SAX over text XML.
However, they ignore the simple fact that SAX has serious usability issues. The awkward forward-only nature of SAX parsing not only requires extra implementation effort, but also incurs performance penalties when the document structure becomes only slightly complex. If developers choose not to scan the document multiple times, they'll have to buffer the document or build custom object models. In addition, SAX doesn't work well with XPath and, in general, can't drive XSLT processing (binary XML has to be transformed as well, right?). So pointing to SAX's raw performance for binary XML as a proof of binary XML's merit is both unfair and misleading. The bottom line: for an XML processing model to be broadly useful, the API must expose the inherent structure of XML.
Unfortunately, binary XML won't make much difference improving DOM parsing. This is for the simple reason that DOM parsing generally spends most CPU cycles on building in-memory tree structures, not on tokenization. So, the speed-up of DOM due to faster SAX parsing is quite limited. In other words, DOM parsing for binary XML will be slow as well. Going one step further, an object-graph based parser will have the same kind of performance issue for virtually any data format such as DCOM, RMI, or CORBA. XML is merely the scapegoat.
Reduce Object Creation - The Correct Approach
From my benchmark and profiling results, it's quite easy to see that the best way to remove the performance bottleneck in XML parsing is to reduce the object-creation cost of building the in-memory hierarchical structure. The possibilities are, in fact, endless, and only limited by the imagination. Good solutions can and will emerge, and among them is VTD-XML. To achieve high performance, VTD-XML approaches XML parsing through the two object-less steps:
- Non-extractive tokenization, and
- Hierarchical-directory-based random access
The result: VTD-XML drastically reduces the number of objects while still exporting the hierarchical structure to application developers and significantly outperforming SAX. (See Figure 3.)
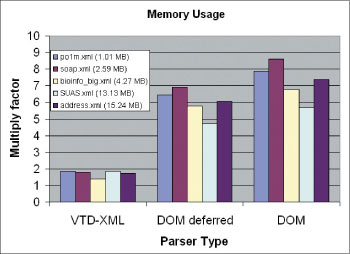
Figure 3: Memory Usage Comparison Between DOM and VTD-XML
Conclusion
To summarize, the right way is to find better parsing techniques beyond DOM and SAX that significantly reduce the object-creation cost of building XML's tree structure. Binary XML won't fundamentally solve XML's performance issue because the problem belongs to XML parsers, not XML.
History
- 23 February, 2008 -- Original version posted.
- 4 March, 2008 -- Article content updated.
- 18 March, 2008 -- Article content updated.
- 09 April, 2008 -- Article content updated.

