Overview
(Note: A whitepaper related to this article is available here.)
As the lingua franca of the Internet, XML has become an indispensable part of IT infrastructure. As more web services applications start to exchange XML messages over the network, we begin to see the emergence of the new generation of "XML-aware" network routers and switches. However, to meet the high throughput and low latency requirements, those purpose-built appliances need XML processing technology that goes beyond traditional, software-based, XML processing models. A closely related topic is porting XML processing on chip. Situated at the seventh layer of OSI (Open Systems Interconnection), XML processing, when implemented on custom hardware, can be thought of as the functional extension of network (co-)processors. But it is a very different layer-seven problem.
The goal of this article is threefold:
- To outline a set of design considerations as the technical foundation for porting XML processing on chip.
- To discuss why DOM and SAX are not ideal candidates for hardware implementation.
- To introduce a new XML processing technique called Virtual Token Descriptor, and explain why it is uniquely suited for hardware implementation.
Introduction
When people talk about the overhead of XML, it is usually one of these two things: verbosity and performance. XML is designed to be the data exchange format for Web applications, and verbosity of XML is a cost that comes with many of its core benefits, such as platform independence and human readability. Fortunately, bandwidth and disk storage are both being commoditized rapidly. For example, many enterprise data centers are starting to see the deployment of 10Gbit Ethernet at the core of the network. Compared to verbosity, which ties directly to the physical characteristics of XML, performance is a different story. To process XML messages, application developers usually choose a processing model, whether it is DOM, SAX, or PULL, to access and interact with XML data. So, strictly speaking, performance is not an issue of XML per se, but instead an issue of XML processing models. DOM is widely known to be both slow and wasteful in memory usage. Alternatives to DOM, SAX, and PULL are difficult to use, leaving much of the burden for developers to bear.
Improving XML's performance could be important for a number of application areas. For middleware, people are often concerned with the CPU load of application servers, as well as the number of transactions performed per unit time. For network switches and routers handling XML messages for security and routing purposes, the typical metrics of interest are throughput and latency. It is critical for those purpose-built devices to achieve the kind of performance that people expect out of network appliances.
Looking at what has happened in the networking industry over the past 20 years, one can find a common trend. Whenever there is an emerging performance bottleneck, people resort to custom hardware, typically in the form of ASIC (Application Specific Integrated Circuit) or FPGAs (Field Programmable Gate Array), for enhanced processing capability. At layer two and three of OSI, network processors and switching fabrics configured in massive parallels enable backbone routers to handle millions of packets per second. At layer four, TOEs (TCP Offload Engines) perform the dirty work of terminating a Gbit TCP connection, and thereby free up host processors to focus on application specific processing. At layer six, VPN (Virtual Private Networking) based either on SSL (Secure Socket Layer) or IP-SEC makes extensive use of custom hardware to handle data encryption and signing that would otherwise drain the CPU's processing cycles. Dedicated ASICs performing deep content inspection and pattern matching are a prime reason why web switches and intrusion detection systems (both at layer 7) can keep up with multi-GB network in enterprise data centers.
Because XML processing is a layer seven problem, it is natural to look for ways to make use of ASICs to solve XML's performance issue. But this time, it is not quite so simple. Pushing deeply into the realm of layer seven, ASIC-based XML processing is subject to constraints specific to both XML and custom hardware.
And there are more questions to think about: why can ASICs significantly outperform CPUs? What are the strengths of custom hardware? What are the weaknesses? Ultimately, it is by answering all of these questions that one derives the essential characteristics of the solution. Sometimes, finding the solution is more about finding the right problem. In the end, solving XML's performance problems is about improving the processing model.
Technical Considerations of XML Processing on a Chip
CPU Vs. Custom Hardware
Also known as general-purpose processors, CPUs (Center Processing Unit) are the most important component of computers. The most noticeable feature of CPUs is that they can be programmed to do pretty much everything, whether it is about decoding MP3 music, running Microsoft Word, or playing video games. CPUs have their own, architecture-specific instruction set. To program CPUs, application developers usually write code in some kind of programming language, then compile the code into instructions, which in turn get executed by the processor. Similar to English letters, which can be combined in various ways to produce the entire vocabulary, an instruction set defines a set of instructions whose combinations describe any application behavior. An important function of compilers is mapping application code, which essentially describes the application behavior, to instructions. A processor has its own bag of performance-enhancing tricks: many modern processors can fetch, as well as re-order, multiple independent instructions so they can be executed in parallel by on-chip execution units.
However, because CPUs are designed to be flexible enough to do anything, the architecture is not optimized for any specific tasks. The mapping between an application's behavior and the corresponding assembly code often introduces unnecessary processing overhead. For example, take a small piece of C code and compile it using gcc -S. On Linux, the output assembly file is usually much more verbose than the C code. As it turns out, there is a class of computation problems for which the processing overhead due to the general-purpose design becomes significant. The common characteristics of those problems are that they have low data dependency and that they require a simple set of operations be performed repetitively over a large amount of data. The best way to improve their efficiency is to optimize at the highest abstraction layer - the architecture level. This is not the strength of CPUs because they only see instructions, and therefore can only optimize the execution at the instruction level.
Compared to CPUs, custom hardware, typically in the form ASICs or FPGAs, is not nearly as programmable. Being application specific, custom hardware lacks the flexibility of general-purpose processors, and is designed to take on a narrow set of functions. But not doing everything allows it to completely bypass the intermediate, "instruction mapping," stage and directly use logic gates, such as registers, NANDs, NORs, and XORs, to describe the application behavior. Because of this, custom hardware is able to optimize at the architecture level to maximize the processing efficiency. Some of the benefits are smaller die sizes, less heat consumption, and higher performance, even running at a much slower clock rate than CPUs.
To illustrate the differences between optimization at the architecture level and at the instruction level, here is an analogy: suppose a man goes to a shopping mall to buy 10 things. Once his shopping plan is final (corresponding to a CPU executing instructions), he can certainly pick the fastest car and the shortest route in order to speed up things. But unfortunately, his plan is to make 10 round trips between home and the mall. So, it should be obvious to most that the plan itself is not optimal because he only needs to make one round trip to make all of the purchases. By optimizing at the highest level (the shopping plan), he can save a lot of time even with a slower car.
Certainty vs. Uncertainty
There are other ways to name this comparison: constant vs. variable, or a priori knowledge vs. a posteriori knowledge. The fact is that the more certainty there is about a design problem, the easier it becomes to optimize the design. For example, most C compilers improve runtime efficiency by folding constant expressions during compile time. As a counterexample, Java's StringBuffer class, not knowing the desired capacity ahead of time, continuously performs memory allocation and copying, and produces garbage when the number of characters significantly exceeds the original capacity. For custom hardware, it is often desirable to keep internal states simple and in constant length, because registers — most commonly on-chip data storage units — are usually constant in length.
Be Stateless
It is well known that to design a scalable distributed system, one should keep state information to a minimum. Otherwise, the overhead of storing and managing state quickly becomes the performance killer. This is a big reason why redirect servers are preferred over the proxy setting, for both SIP and DNS. For custom hardware design, being stateless is even more important. Unlike general-purpose processors that have the luxury of calling malloc(), custom hardware often has a set of fixed length registers and a limited amount of linear memory buffer not capable of excessive buffering. So, the most efficient memory access pattern for custom hardware is forward-only, flow-through in order to minimize buffering.
Structs, Objects, and Integers
C's struct provides a way to bind together multiple member variables/fields into a single entity. In object-oriented languages, the notion of object is actually a souped-up version of struct with additional support of access control and member methods. Both a struct and an object are, at the programming language level, quite different from primitive data types such as an integer. However, the physical representations of a struct, an object, and an integer have one thing in common: they are all small memory blocks filled with bits. This similarity is important in ASIC/FPGA design. On a chip, there is no such thing as an object or a struct, and pretty much everything consists of a constant number of bits so they can be stored in registers to represent the state. As to the binding part, one can actually split all the bits into different groups to represent different variables. For example, a 32-bit register can bind together four 8-bit integers, two 16-bit integers, or even 32 single-bit Booleans. So in a way, an integer is a hardware guy's object.
Ethernet and PCI
Ethernet is the pervasive LAN (Local Area Network) technology connecting PCs, servers, storages, and printers. PCI (Peripheral Component Inter-connect) is the local bus technology designed to interconnect a CPU and attached devices. On the surface they seem irrelevant, as they are designed for different applications. However, there is one important similarity related to XML processing. At the physical level, both the PCI bus and the Ethernet bus consist of a set of wires over which only arrays of bytes can be moved. In other words, if custom hardware exports data to software applications, the data need to be persistent. And not surprisingly, this design constraint applies to both IPC and RPC.
A DES Decryption Problem
The Data Encryption Standard (DES) is a widely used symmetrical block-cipher algorithm whose ASIC implementation is well known to be able to deliver GB per second sustained throughput. At the top level, DES decryption converts 64-bit cipher blocks into 64-bit plain-text blocks based on a pre-negotiated 64-bit key value. A system-level view of DES on a chip exhibits, in many ways, the constraints and design principles of how to take advantage of custom hardware. First, a DES chip does nothing but decryption, and does it much faster than a CPU because the algorithm is burned right into silicon. Second, the design is stateless; except for a few internal state registers, every 64-bit input has its own corresponding 64-bit output, and no buffering is needed. Third, the 64-bit data blocks moved across the PCI bus are constant in length and naturally persistent. And because of this, application code residing in a separate memory space is able to benefit from the horsepower of custom hardware. Overall, the DES problem provides a good prototype for ASIC-based XML parsing. After all, why change things if they work so well?
Problems of Porting DOM/SAX on a Chip
DOM and SAX are the two natural candidates for custom hardware implementation because many XML applications are developed using these two processing models. However, it turns out that there are two kinds of problems that prevent them from being ported on a chip. The first one is technical issues. The second is about whether performance improvement due to custom hardware is significant enough to justify the effort in the first place.
It actually makes sense to port DOM on a chip because building a DOM tree is often the most processing-intensive part of an application. However, DOM on a chip does not work very well. The first show stopper: the in-memory representation of a DOM tree, consisting of many objects stitched together using pointers, is not inherently persistent, and therefore cannot be transported across the process address space as is. What if custom hardware produces some sort of serialized DOM? Here comes the second show stopper: the cost of converting the serialized DOM into an in-memory tree becomes prohibitively expensive so that there is little tangible performance benefit to port DOM on a chip. Additionally, even if DOM on a chip is possible, the cost of garbage collecting all the objects would put a cap on the overall performance gain achievable using custom hardware.
Implementing SAX on a chip also faces a few technical problems. When an application uses SAX to parse XML, the parsing code and the application logic are interwoven. This style of parsing means the application needs to initiate a lot of expensive device calls. As an alternative, the chip can produce some form of serialized SAX events. But, this approach, again, won't provide any substantial performance benefit because of the object creation cost to regenerate the SAX events. However, the biggest problem with SAX on a chip is that SAX parsing itself is usually not a significant performance bottleneck for an application. So, porting SAX on a chip is simply solving the wrong problem.
VTD: XML Processing One Bit at a Time
In one of my previous articles, I pointed out that the traditional, extractive style of tokenization has a simple, "non-extractive" alternative based entirely on the starting offset and length. VTD is a binary encoding specification that builds on this "non-extractive" tokenization. A VTD record, shown below, is a 64-bit integer that encodes the starting offsets, lengths, types, and nesting depth of tokens in XML. Also, VTD requires that the XML document be kept intact in memory.
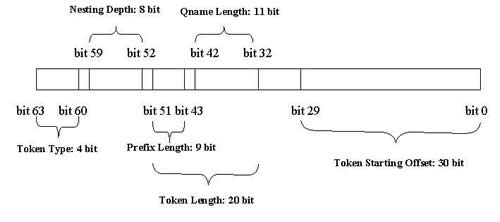
VTD-XML, which is the name of both the open source, Java-based, XML processing API and the corresponding XML processing model, internally makes use of the VTD specification to represent the tokenized form of XML. In addition, VTD-XML also introduces the concept of Location Caches (LCs) as a way to provide a hierarchical view of an XML info-set. A complete technical description on LCs can be found at the project web site.
Alluding to previous technical discussions, VTD is ideally suited for custom hardware implementation. One way to look at this is that VTD turns an XML processing problem into the DES encryption. The fact that VTD records are constant in length makes it possible for custom hardware to feature a stateless, flow-through, "process-then-discard" architecture that requires minimum buffering. By burning the VTD algorithm on chip, the design can optimize at the architecture level to achieve significant performance improvement over general purpose processors. Specifying parameter encoding at the bit layout level ensures platform independence and interoperability among different implementations. Finally, because VTD records are constant in length, they are addressable using integers. In other words, VTD records are persistent post-binding, meaning they can be transported across the PCI bus, and bypass the step — and the associated cost — of allocating a large number of objects, so software applications at the receiving end can take maximum performance benefit of custom hardware.
Nevertheless, the implications of VTD do not end with custom hardware. In fact, VTD-XML provides DOM-like random access with only 1/3-1/5 of DOM 's memory usage. The reasons are:
- To avoid per-object overhead: In many VM-based, object-oriented programming languages, per-object allocation incurs a small amount of memory overhead. A VTD record is immune to the overhead because it is not an object.
- Bulk-allocation of storage: Fixed in length, VTD records can be stored in large memory blocks, which are more efficient to allocate and GC. By allocating a large array for 4096 VTD records, one incurs the per-array overhead (16 bytes in JDK 1.4) only once across 4096 records, thus reducing per-record overhead to very little.
By reducing object creation cost, VTD-XML is able to achieve very high performance even in software. In fact, VTD-XML typically outperforms a SAX parser with NULL content handlers by 100%. And, it is also worth mentioning that VTD-XML uniquely, and efficiently, enables incremental update.
A Quick Summary and the Road Ahead
In summary, porting XML on a chip has its technical challenges. It is about more than just finding solutions: Porting DOM or SAX on a chip simply doesn't work very well. It is actually about finding the right problem to solve. VTD, a simple solution based on a proven design, overcomes the problems of DOM and SAX, and allows software to seamlessly and sensibly take advantage of custom hardware.
But, VTD is only a starting point. Below is a list of potential topics, as well as future development, concerning the design, implementation, and applications of VTD:
- VTD on a chip: This article focuses on parsing VTD on a chip. It would be interesting to think about moving XPath and validation on a chip. A hint: The output of XPath description is inherently persistent.
- VTD on disk: Because VTD records are inherent, they can be persisted on disk as a natural, general-purpose XML indexing scheme.
- VTD on wire: VTD records can be attached with XML documents to eliminate repetitive parsing for network switches and routers, and middleware applications consuming incoming XML data.
Further Reading

