Have you ever wondered how a newspaper site always displayed news of your interest?
How Google serves you with appropriate information that you are looking for?
How Youtube lists out videos of your likings?
How Amazon computed your buying pattern?
Interesting right?... Yes, there is someone sitting behind the scenes and reading your mind, constantly learning about your interests, quickly making best decisions about your likings, running complex algorithms and performing thousands of computations to derive your web browsing behavior.
So Who is Doing All These, Behind the Scenes?
"Recommender Systems" a huge and most complex system striving hard to serve the user with the "most appropriate" content in an automated fashion. These are the systems responsible for understanding user interests and behavior and present them with the contents in line with their expectations.
How Does Recommender System Work?
The functioning of recommender systems varies based on the business where they are deployed in, but most of these systems run intelligent algorithms to extract the most appropriate contents from a large set of options available. These intelligent algorithms are not static, but they are constantly modified based on user responses for the contents presented.
Few of these recommender systems start from nothing and get going with constantly learning about user interests over a period of time and based on this data, it decides on the contents to be presented further.
Like this, different recommender systems use different techniques to arrive at best choice of contents.
Let's Understand these Algorithms by Solving a Real Time Problem
Problem Statement
You being the editor of "Yahoo" home page, your responsibility is to choose "5" articles out of "30" available articles to be put on Yahoo India home page.
Why is This Issue Hard to Resolve?
Yes, this is really a complex problem, because the problem itself is very subjective. It's hard to derive at an algorithm which always returns the best predictions for all set of users. An algorithm which predicts extremely well for few set of users may turn out to be the worst algorithm for other set of people.
This is because the interests of people change from person to person, person 'A' likes sports news, person 'B' likes news about politics, person 'C' is a stock broker, person 'C' always looks for news from Hollywood, like this the tastes and interests of the people are subjective and tend to change even based on geography.
Solution
Here, I'll try to explain the solution for the above mentioned problem in simple terms, using two algorithms, one of them is a simple algorithm which is not very effective and the other one a highly effective algorithm based on the probability which is currently being used by many news agencies.
Algorithm 1 - Predictions Based on User Groups
This is a very simple algorithm which uses the following principle:
- Create multiple geographical areas.
- Consider a particular geographical area and predict interests of people in that locality .
- Come up with different segments based on predictions.
- The segments could be Sports, Politics, Cinema, Education, Science, Technology.
- Now assign users to these different segments based on predictions.
- At a given time, assign all the available articles from different categories to different segments.
- The article assigned to a segment which has highest number users gets first priority.
- Article assigned to a segment which has next highest number of users gets second priority. Like this, the priorities of articles are decided.
- Hence the algorithm arrives at ranking of all the available articles.
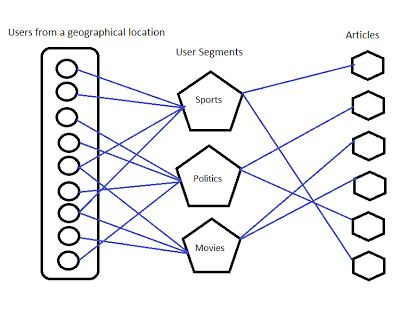
Predictions based on user groups
Algorithm 2 - Random Bucket Algorithm
This is the most efficient algorithm used in many recommender systems. This algorithm was invented by Charles Pierce, a physicist in the year 1877.
The algorithm works based on true randomization, and this randomization completely removes bias, which means no article is presented subjectively inline with interests of a particular group of users, but instead all the articles are presented randomly to a group of users who are also selected randomly.
Finally, based on the users feedback of liking or disliking of the article, probability is found-out for each article. The article with the highest probability gets first priority and the next article with the highest probability gets second priority and so on.
Let me explain this with a simple example. Say our goal is to find-out whether people like Coke most or Pepsi most, here is the trick.
- Randomly choose 10 people.
- Randomly distribute Coke or Pepsi to each one of them.
- Say 5 people got coke and 3 of them like it.
- And, say 5 people got Pepsi and only 1 of them likes it.
Which means the probability of people liking coke is more than the probability of people liking Pepsi.
Hence the conclusion is that most of the people like Pepsi than Coke, this algorithm though looks simple is very complicated and proven to be most effective under all circumstances.
That's all, I hope you have got a brief introduction about the most challenging yet interesting research area "Recommender Systems". Most of the search engine companies, news and online shopping giants shell out a lot of money and significant amount of time on this research area with an intent of building the best recommender systems which give out a huge customer base in return.
If you are interested in digging deeper into this topic.... Just Google it.. May be the best " Recommender System" will get you the most appropriate information.... :-)

