In my first article about database performance tuning I have described indexing strategies and I have mentioned some aspects you should keep in mind during designing your indexes. Now I will continue to discuss about database tuning. In this second article I will tell you about index maintenance.
There is nothing really new that indexes have their right to exist in SQL Server. Implementing indexes is not so trivial task because well designed index strategy can rapidly increase performance of database but on the other hand awkward indexes can cause performance degradation. As almost everything in database need maintenance, indexes need it too. Index maintenance is an uncommon and very difficult task because some operations could take a long time and you must keep this in mind when you are planning maintenance.
As DBA you must ensure optimal performance of the database. As I mentioned above one of the key tasks is index maintenance. Making a good index means to minimize I/O operations. There are some activities you as DBA should perform:
- Reorganizing and rebuilding indexes. This process involves defragmenting of indexes and optimization of disk space.
- Using the Fill factor option to fine tune the index data storage and performance.
- Performing index operations online by using the LINE index option to provide user access to data during index operations.
- Configuring parallel Index operations by using the max degree of parallelism option.
- Using the Query optimizer to develop optimal query plans based on statistics.
- Improving the performance of bulk copy operations on tables with clustered and non clustered indexes.
- Selecting suitable Recovery model of the database for index operations and listing the types of logging available.
About all of this activities we will discuss later int this article. At the beginning I consider to be appropriate to determine some basic terms which we will use later.
Understand Clustered indexes is very easy in the area of index selection. Clustered indexes are basically keys that reference each row uniquely. Even if you define a clustered index and do not declare it as unique, SQL Server still makes the clustered index unique behind the scenes by adding a 4-byte "uniqueifier" to it. The additional "uniqueifier" increases the width of the clustered index, which causes increased maintenance time and slower searches. Since clustered indexes are the key that identifies each row, they are used in every query.
When we start talking about non-clustered indexes, things get confusing. Queries can ignore non-clustered indexes for the following reasons:
- High fragmentation – If an index is fragmented over 40%, the optimizer will probably ignore the index because it's more costly to search a fragmented index than to perform a table scan.
- Uniqueness – If the optimizer determines that a non-clustered index is not very unique, it may decide that a table scan is faster than trying to use the non-clustered index. For example: If a query references a bit column (where bit = 1) and the statistics on the column say that 75% of the rows are 1, then the optimizer will probably decide a table scan will get the results faster versus trying to scan over a non-clustered index.
- Outdated statistics – If the statistics on a column are out of date, then SQL Server can misguide the benefit of a non-clustered index. Automatically updating statistics doesn't just slow down your data modification scripts, but over time it also becomes out of sync with the real statistics of the rows. Occasionally it's a good idea to run sp_updatestats or UPDATE STATISTICS.
- Function usage – SQL Server is unable to use indexes if a function is present in the criteria. If you're referencing a non-clustered index column, but you're using a function such as convert(varchar, Col1_Year) = 2004, then SQL Server cannot use the index on Col1_Year.
- Wrong columns – If a non-clustered index is defined on (col1, col2, col3) and your query has a where clause, such as "where col2 = 'somevalue'", that index won't be used. A non-clustered index can only be used if the first column in the index is referenced within the where clause. A where clause, such as "where col3 = 'someval'", would not use the index, but a where clause, like "where col1 = 'someval'" or "where col1='someval and col3 = 'someval2'" would pick up the index.
- The index would not use col3 for its seek, since that column is not after col1 in the index definition. If you wanted col3 to have a seek occur in situations such as this, then it is best if you define two separate non-clustered indexes, one on col1 and the other on col3.
To store data, SQL Server uses pages that are 8 kb data blocks. The amount of data filling the pages is called the fill factor, and the higher the fill factor, the more full the 8 kb page is. A higher fill factor means fewer pages will be required resulting in less IO/CPU/RAM usage. At this point, you might want to set all your indexes to 100% fill factor; however, here is the gotcha: Once the pages fill up and a value comes in that fits within a filled-up index range, then SQL Server will make room in an index by doing a "page split."
In essence, SQL Server takes the full page and splits it into two separate pages, which have substantially more room at that point. You can account for this issue by setting a fill-factor of 70% or so. This allows 30% free space for incoming values. The problem with this approach is that you continually have to "re-index" the index so that it maintains a free space percentage of 30%.
While indexes can speed up execution of queries several fold as they can make the querying process faster, there is overhead associated with them. They consume additional disk space and require additional time to update themselves whenever data is updated, deleted or appended in a table. Also when you perform any data modification operations (INSERT, UPDATE, or DELETE statements) index fragmentation may occur and the information in the index can get scattered in the database. Fragmented index data can cause SQL Server to perform unnecessary data reads and switching across different pages, so query performance against a heavily fragmented table can be very poor. In this article I am going to write about fragmentation and different queries to determine the level of fragmentation. There are two major types of fragmentation: logical (external fragmentation) and SQL Server fragmentation.
Logical fragmentation occurs when an index leaf page is not in logical order, in other words it occurs when the logical ordering of the index does not match the physical ordering of the index. This causes SQL Server to perform extra work to return ordered results. For the most part, external fragmentation isn’t too big of a deal for specific searches that return very few records or queries that return result sets that do not need to be ordered. Page splits could occur in case of:
- insert or updates
- heavy deletes that can cause pages be removed from the page chain, resulting in dis-contiguous page chain
This type of fragmentation occurs when there is too much free space in the index pages. Typically, some free space is desirable, especially when the index is created or rebuilt. You can specify the Fill Factor setting when the index is created or rebuilt to indicate a percentage of how full the index pages are when created. If the index pages are too fragmented, it will cause queries to take longer (because of the extra reads required to find the dataset) and cause your indexes to grow larger than necessary. If no space is available in the index data pages, data changes (primarily inserts) will cause page splits as discussed above, which also require additional system resources to perform. Internal fragmentation usually occurs when:
- random deletes resulting in empty space on data pages
- page-splits due to insert or updates
- shrinking the row such as when updating a large value to a smaller value
- using fill factor of less than 100
- using a large row sizes
Extent fragmentation occurs when the extents of a table or index are not contiguous with the database leaving extents from one or more indexes intermingled in the file. This can occur due to:
- random deletes, which could leave some of the pages in an extent unused while the extent itself is still reserved as part of the table’s space allocation. Think of it like Internal fragmentation, but in extents instead of pages
- deletes on ranges of contiguous rows within the table, causing one or more entire extents to become de-allocated, thus leaving a gap between the surrounding extents of the table or index
- interleaving of a table’s data extents with the extents of other objects
Heavily fragmented indexes can degrade query performance significantly and cause the application accessing it to respond slowly. To help you identify the amount of fragmentation SQL Server 2005 and 2008 come with sys.dm_db_index_physical_stats dynamic management function.
The following query returns DETAILED information about fragmentation level of AdvendureWorks2008R2 database.
select
OBJECT_NAME(stats.object_id) as [Object_Name],
idx.name as [Index_Name] ,
stats.avg_fragmentation_in_percent,
stats.avg_page_space_used_in_percent
from
(select OBJECT_ID, index_id, avg_fragmentation_in_percent, avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats (DB_ID('AdventureWorks2008R2'),null,null,null,'DETAILED')
where index_id<>0) as stats
join sys.indexes idx
on idx.object_id=stats.object_id
and idx.index_id = stats.index_id
You have to focus on 2 values. First is
avg_fragmentation_in_percent column to identify external fragmentation and the second is
avg_page_space_used_in_percent to identify internal fragmentation. When index has
avg_fragmentation_in_percent value greater than 10 that indicates, that index is highly fragmented. Internal fragmentation is indicated when
avg_page_space_used_in_percent value falls below 75.
When you want to resolve some fragmentation issues, SQL Server offers you 2 ways how to fix issues: ALTER INDEX ... REORGANIZE or ALTER INDEX ... REBUILD.
In SQL Server 2005 the ALTER INDEX REORGANIZE statement has replaced the DBCC INDEXDEFRAG statement. A single partition of a partitioned index can be reorganized using this statement.
This statement reorganizes the leaf level of the clustered and non clustered indexes on tables and views are reorganized and reordered to match the logical order—i.e. left to right of the leaf nodes. The index is organized within the allocated pages and if they span more than one file they are reorganized one at a time. No pages are migrated between files. Moreover, pages are compacted and empty pages created as a consequence are removed and the disk space released. The compaction is determined by the fill factor value in sys.indexes catalog view. Large object data types contained in clustered index or underlying tables will also be compacted by default if the LOB clause is present.
The good news is that the reorganize process is economical on the system resources and is automatically performed online. There are no long term blocking locks which jam up the works!
DBAs are advised to reorganize the index when it is minimally fragmented. Heavily fragmented indexes will require rebuilding. Microsoft recommends reorganising an index when 60 < avg_page_space_used_in_percent < 75 or 5 < avg_fragmentation_in_percent < 30.
When an index is rebuilt, it is dropped and a new one is created. This process is very resource intensive and removes external and internal fragmentation. External fragmentation is removed by reordering the index rows in contiguous pages. Internal fragmentation is removed by fill factor. You can use ONLINE option which causes that table and it's indexes are available for selecting and data modification.
When you are rebuilding an index by defaul SQL Server locks table to prevent any data modification. To override this behavior you can use ONLINE option. In this case SQL Server does index rebuild in3 phases.
- Preparation phase
- Build
- Final
In preparation phase all system metadata are collected to create a new empty index structure. Snapshot of table is defined and row versioning is used to provide transaction-level read consistency. Any concurrent write operations on the table are blocked for a very short time.
During build phase the data is scanned, sorted, merged and inserted into the target. Concurrent user select, insert, update, and delete operations are applied to both the preexisting indexes and any new indexes being built.
Before the final phase, all uncommitted update transactions must be completed. All read and write operations are blocked for a very short time until this phase is completed. System metadata is updated to replace source object by the target.
SQL Server 2005 Enterprise Edition supports using multiple processors by the following index creation and rebuild statements:
CREATE INDEXDROP INDEX (only for clustered indexes)ALTER TABLE ADD CONSTRAINT (only for index constraints)ALTER TABLE DROP CONSTRAINT (only for clustered indexes)
The number of processors used depends on the 'max degree of parallelism' configuration option and the amount of free resources at the time when the index is being created to rebuilt. Using all available processors for building large indexes would provide the best performance; however, this could also cause severe shortage of resources for user queries. Therefore if SQL Server determines that the system is busy it will only use a subset of processors for index operations. You can impose further restrictions for processor usage on index operations by using
MAXDOP query hint, for example, the following statement limits the
ALTER INDEX statement to 2 processors:
ALTER INDEX PK_DimProduct_ProductKey ON DimProduct REBUILD WITH (MAXDOP = 2)
If MAXDOP hint specifies 1 all index operations will be sequential and not parallel; 0 is the default value and does not restrict the number of processors. Any value above 1 will be interpreted as number of processors to be considered, however, the actual number of processors used for building an index might be lower depending on system load.
Parallel index operations might be particularly resource intensive for non-aligned partitioned indexes. This is because SQL Server must build one sort table for each partition (either on the respective file group where the partition is stored or in tempdb, depending on whether SORT_IN_TEMPDB option is used). If the index is aligned with the table partitioning scheme or with the clustered index then sort tables are built sequentially for each partition. But for non-aligned indexes all sort tables are built in one operation unless you set maximum degree of parallelism to 1. The higher the degree of parallelism the more sort tables must be built for non-aligned partitioned indexes at the same time and therefore, the more memory will be required. If the system doesn't have enough memory to create enough sort tables for an index on a table with numerous partitions the operation will fail. If so, you can normally work around the problem by specifying lower degree of parallelism.
As I mentioned earlier one of the key task of DBA is to maintain indexes. Sometimes indexes need to rebuild. This task could be a time consuming in case of many indexes. ALTER INDEX statement allows you to rebuild your indexes but you must specify object name for which you want to rebuild indexes.Using ALTER INDEX ALL option allows you to rebuild all indexes for specified table or view but what if you have a lot of tables? That could be a problem because you must create ALTER statement for all tables or views you want to rebuild indexes. Here I provide you a script for rebuilding all indexes for all tables and databases.
DECLARE @Database VARCHAR(255)
DECLARE @Table VARCHAR(255)
DECLARE @cmd NVARCHAR(500)
DECLARE @fillfactor INT
SET @fillfactor = 90
DECLARE DatabaseCursor CURSOR FOR
SELECT name FROM MASTER.dbo.sysdatabases
WHERE name NOT IN ('master','msdb','tempdb','model','distribution')
ORDER BY 1
OPEN DatabaseCursor
FETCH NEXT FROM DatabaseCursor INTO @Database
WHILE @@FETCH_STATUS = 0
BEGIN
SET @cmd = 'DECLARE TableCursor CURSOR FOR SELECT ''['' + table_catalog + ''].['' + table_schema + ''].['' +
table_name + '']'' as tableName FROM ' + @Database + '.INFORMATION_SCHEMA.TABLES
WHERE table_type = ''BASE TABLE'''
EXEC (@cmd)
OPEN TableCursor
FETCH NEXT FROM TableCursor INTO @Table
WHILE @@FETCH_STATUS = 0
BEGIN
IF (@@MICROSOFTVERSION / POWER(2, 24) >= 9)
BEGIN
SET @cmd = 'ALTER INDEX ALL ON ' + @Table + ' REBUILD WITH (FILLFACTOR = ' +CONVERT(VARCHAR(3),@fillfactor) + ')'
EXEC (@cmd)
END
ELSE
BEGIN
DBCC DBREINDEX(@Table,' ',@fillfactor)
END
FETCH NEXT FROM TableCursor INTO @Table
END
CLOSE TableCursor
DEALLOCATE TableCursor
FETCH NEXT FROM DatabaseCursor INTO @Database
END
CLOSE DatabaseCursor
DEALLOCATE DatabaseCursor
This script rebuilds all indexes for all tables and databases. If you want to rebuild indexes only for some databases, just rewrite:
WHERE name NOT IN ('master','msdb','tempdb','model','distribution')
to
WHERE name IN ('myDB1','myDB2')
This script was created by Greg Robidoux and more about this you can find here
Indexes can rapidly affects performance of database. Too few indexes can cause scans and hence dramatically increase response time of your application. Too many indexes causes overhead for index maintenance during data updates and also a bloated database. It is very difficult to know what indexes are being used and how they are being used. Sometimes is very good to get rid of indexes that are not used. For this type of task SQL Server comes with many new dynamic management views. Two new views that provide data about index usage are sys.dm_db_index_operational_stats and sys.dm_db_index_usage_stats.
This dynamic management view gives you information about insert, update and delete operations for particular index. This dmv also provides information about locking, latching and access methods. There are several columns that are returned from this type of view:
leaf_insert_count - total count of leaf level insertsleaf_delete_count - total count of leaf level deletesleaf_update_count - total count of leaf level updatesrow_lock_count - total count of row locksrow_lock_wait_count - total count of times the Database Engine waited on a row lockpage_latch_wait_count - total count of times the Database Engine waited, because of latch contention
SELECT OBJECT_NAME(A.[OBJECT_ID]) AS [OBJECT NAME],
I.[NAME] AS [INDEX NAME],
A.LEAF_INSERT_COUNT,
A.LEAF_UPDATE_COUNT,
A.LEAF_DELETE_COUNT
FROM SYS.DM_DB_INDEX_OPERATIONAL_STATS (NULL,NULL,NULL,NULL ) A
INNER JOIN SYS.INDEXES AS I
ON I.[OBJECT_ID] = A.[OBJECT_ID]
AND I.INDEX_ID = A.INDEX_ID
WHERE OBJECTPROPERTY(A.[OBJECT_ID],'IsUserTable') = 1
Here is the output from the above query. From this view we can get an idea of how many inserts, updates and delete operations were performed on each table and index.
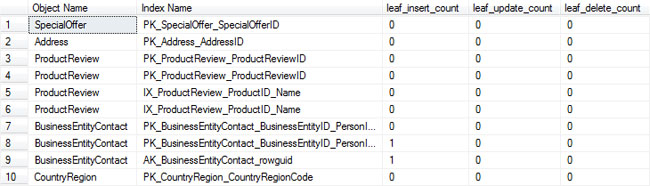
This view gives you information about overall access methods to your indexes. There are several columns that are returned from this DMV, but here are some helpful columns about index usage:
user_seeks - number of index seeksuser_scans - number of index scansuser_lookups - number of index lookupsuser_updates - number of insert, update or delete operations
SELECT OBJECT_NAME(S.[OBJECT_ID]) AS [OBJECT NAME],
I.[NAME] AS [INDEX NAME],
USER_SEEKS,
USER_SCANS,
USER_LOOKUPS,
USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS AS S
INNER JOIN SYS.INDEXES AS I
ON I.[OBJECT_ID] = S.[OBJECT_ID]
AND I.INDEX_ID = S.INDEX_ID
WHERE OBJECTPROPERTY(S.[OBJECT_ID],'IsUserTable') = 1
Here is the output from the above query. From this view we can get an idea of how many seeks, scans, lookups and overall updates (insert, update and delete) occurred.

Following example returns all indexes that have not been used.
SELECT
DB_NAME() AS DatabaseName,
OBJECT_NAME(idx.OBJECT_ID) AS TableName,
idx.NAME AS IndexName,
idx.index_id
FROM
sys.objects obj
JOIN sys.indexes idx ON obj.OBJECT_ID = idx.OBJECT_ID
WHERE
not exists (SELECT
stats.index_id
FROM
sys.dm_db_index_usage_stats stats
WHERE idx.OBJECT_ID = stats.OBJECT_ID
AND idx.INDEX_ID = stats.INDEX_ID) AND obj.TYPE <> 'S'
ORDER BY DatabaseName, TableName, IndexName
In this query we are listing each user table, all of its indexes and the columns that make up the index. The issue with this query is that you have a row for each column in the index which could get confusing if you have a lot of indexes.
SELECT
obj.name as TableName,
idx.name as IndexName,
idxcols.key_ordinal,
cols.name as ColumnName
FROM
sys.objects obj
join sys.indexes idx
ON obj.object_id = idx.object_id
join sys.index_columns idxcols
ON idx.object_id = idxcols.object_id
and idx.index_id = idxcols.index_id
join sys.columns cols
ON idxcols.object_id = cols.object_id
and idxcols.column_id = cols.column_id
WHERE
obj.TYPE <> 'S'
ORDER BY TableName, IndexName, key_ordinal
In this query we use most of Query 3, but we are doing a PIVOT so we can see the index and the index columns in one row. This only accounts for 7 index columns, but it could easily be increased to handle more in the PIVOT operation. Here is another tip related to the use of PIVOT, Crosstab queries using PIVOT in SQL Server 2005. if you would like to better understand how PIVOT works.
SELECT TABLENAME, INDEXNAME, INDEXID, [1] AS COL1, [2] AS COL2, [3] AS COL3,
[4] AS COL4, [5] AS COL5, [6] AS COL6, [7] AS COL7
FROM (SELECT A.NAME AS TABLENAME,
B.NAME AS INDEXNAME,
B.INDEX_ID AS INDEXID,
D.NAME AS COLUMNNAME,
C.KEY_ORDINAL
FROM SYS.OBJECTS A
INNER JOIN SYS.INDEXES B
ON A.OBJECT_ID = B.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS C
ON B.OBJECT_ID = C.OBJECT_ID
AND B.INDEX_ID = C.INDEX_ID
INNER JOIN SYS.COLUMNS D
ON C.OBJECT_ID = D.OBJECT_ID
AND C.COLUMN_ID = D.COLUMN_ID
WHERE A.TYPE <> 'S') P
PIVOT
(MIN(COLUMNNAME)
FOR KEY_ORDINAL IN ( [1],[2],[3],[4],[5],[6],[7] ) ) AS PVT
ORDER BY TABLENAME, INDEXNAME;
In this query we tie in our PIVOT query above with sys.dm_db_index_usage_stats so we can look at only the indexes that have been used since the last time the stats were reset.
SELECT TABLENAME, INDEXNAME, INDEX_ID, [1] AS COL1, [2] AS COL2, [3] AS COL3,
[4] AS COL4, [5] AS COL5, [6] AS COL6, [7] AS COL7
FROM (SELECT A.NAME AS TABLENAME,
A.OBJECT_ID,
B.NAME AS INDEXNAME,
B.INDEX_ID,
D.NAME AS COLUMNNAME,
C.KEY_ORDINAL
FROM SYS.OBJECTS A
INNER JOIN SYS.INDEXES B
ON A.OBJECT_ID = B.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS C
ON B.OBJECT_ID = C.OBJECT_ID
AND B.INDEX_ID = C.INDEX_ID
INNER JOIN SYS.COLUMNS D
ON C.OBJECT_ID = D.OBJECT_ID
AND C.COLUMN_ID = D.COLUMN_ID
WHERE A.TYPE <> 'S') P
PIVOT
(MIN(COLUMNNAME)
FOR KEY_ORDINAL IN ( [1],[2],[3],[4],[5],[6],[7] ) ) AS PVT
WHERE EXISTS (SELECT OBJECT_ID,
INDEX_ID
FROM SYS.DM_DB_INDEX_USAGE_STATS B
WHERE DATABASE_ID = DB_ID(DB_NAME())
AND PVT.OBJECT_ID = B.OBJECT_ID
AND PVT.INDEX_ID = B.INDEX_ID)
ORDER BY TABLENAME, INDEXNAME;
This query also uses the PIVOT query along with sys.dm_db_index_usage_stats so we can also see the stats on the indexes that have been used.
SELECT PVT.TABLENAME, PVT.INDEXNAME, [1] AS COL1, [2] AS COL2, [3] AS COL3,
[4] AS COL4, [5] AS COL5, [6] AS COL6, [7] AS COL7, B.USER_SEEKS,
B.USER_SCANS, B.USER_LOOKUPS
FROM (SELECT A.NAME AS TABLENAME,
A.OBJECT_ID,
B.NAME AS INDEXNAME,
B.INDEX_ID,
D.NAME AS COLUMNNAME,
C.KEY_ORDINAL
FROM SYS.OBJECTS A
INNER JOIN SYS.INDEXES B
ON A.OBJECT_ID = B.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS C
ON B.OBJECT_ID = C.OBJECT_ID
AND B.INDEX_ID = C.INDEX_ID
INNER JOIN SYS.COLUMNS D
ON C.OBJECT_ID = D.OBJECT_ID
AND C.COLUMN_ID = D.COLUMN_ID
WHERE A.TYPE <> 'S') P
PIVOT
(MIN(COLUMNNAME)
FOR KEY_ORDINAL IN ( [1],[2],[3],[4],[5],[6],[7] ) ) AS PVT
INNER JOIN SYS.DM_DB_INDEX_USAGE_STATS B
ON PVT.OBJECT_ID = B.OBJECT_ID
AND PVT.INDEX_ID = B.INDEX_ID
AND B.DATABASE_ID = DB_ID()
ORDER BY TABLENAME, INDEXNAME;
All of this examples are taken from http://www.mssqltips.com/tip.asp?tip=1545
History
- 22 August - Original version posted

