Summary
Most readers of The Code Project are familiar with various types of XML parsers in the .NET environment. This article series introduces to The Code Project community a new XML processing model called VTD-XML. It goes significantly beyond those traditional models by fundamentally overcoming many tough technical challenges hampering SOA and enterprise XML application development. The first part of this series demonstrates the benefits of VTD-XML as an indexer and as a parser with integrated XPath. The second part shows you how to benefit from VTD-XML's cutting, editing, and modifying capabilities, as well as introduces the concept of "document-centric" XML processing. The third part of this series shows you how to code your application in the C version of VTD-XML.
Public Enemy #1: DOM's Problem of Modifying XML
Suppose a DOM-based application modifies a particular text node of an XML document, below are the necessary steps to accomplish that:
- Decode characters
- Create string objects by taking apart the input document
- Allocate node objects to build the DOM tree
- Navigate to the text node (manually or by XPath)
- Attach a new text node
- Encode characters
- Byte concatenation
- Garbage collecting node and string objects
But, if you focus on the objective, I think that many readers will realize that the process outlined above doesn't really make sense. It is, in fact, absurd. DOM processing incurs at least the following three round-trip overheads in those steps:
- Every time a character is decoded, it eventually needs to be encoded again.
- Every time a document is taken apart of any change, it needs to be put back together (by concatenation).
- Every time an object (e.g., strings, nodes etc.) is allocated, it will eventually go out of scope and be garbage collected.
Because those round-trips pretty much restore the document to the original state, they are nothing but a waste of CPU cycles and memory. Notice that modifying a text node can be done far more efficiently by humans using a text editor. To edit a text node, just open the document with Notepad, move the cursor to the text node, make the change in-place, and save it! This time, the update is "incremental", meaning it does not touch irrelevant parts of the document. And, if we, humans, can edit XML like this, why can't XML parsers?
To me, the answer to this question reveals some of the deep-root technical problems in software development today. Below are some of my observations on this topic:
- It significantly impacts your application performance: When applications process XML in a read-only fashion, the base-line performance is decided by XML parsing. If applications both read and write XML data, the base-line performance is typically cut in half (as serialization and de-serialization are equal in performance).
- It is a common, but deep, problem: Have you wondered that given XML is ubiquitous, why nobody seems to be complaining? One way to look at this: because this is the way things have always been, and everyone seems to get used to it. To make matter worse, solutions don't exist to make the problem look obvious. So, we end up with an ubiquitous issue that is surprisingly non-obvious and from which there is almost no escape.
- Hidden from OO perspective: If you live in a pure OO world, the redundant de-serialization/serialization process-- the textbook approach of XML processing-- is very much the right thing to do. So, this problem is again hidden.
It is also worth noting that there is nothing small about this problem. It is, in my view, the biggest and toughest technical issue in enterprise IT today. Consider the ESB (Enterprise Services Bus) example I used in the first part of the series. Right now, the situation is, in my view, bad beyond belief. Because of the inefficient DOM parsing, those ESBs are already considered slow in read-only situations, especially for large XML messages. If the desired operations (such as policy enforcement) require both reading and writing, it is like adding insult to injury: no matter how trivial the change is, the entire XML message needs to be re-serialized, quickly degrading the overall performance to the point of unbearable.
So, my question becomes: Am I the only one seeing the elephant in the room?
How VTD-XML Changes the Picture
Simply put, VTD-XML provides a solution so spectacular that the problem is completely gone!
The first part in this article series introduced VTD-XML as a memory efficient, high performance XML parser with integrated indexing and XPath. Virtually every technical benefit of VTD-XML is, in one way or the other, the result of non-extractive parsing, meaning the original XML text is loaded in memory and fully preserved. However, the most important benefits of VTD-XML --the ones that truly set it apart from other XML processing models-- lie in its unique ability to manipulate XML document content at the byte level. Below are three distinct, yet related, sets of capabilities available in the latest version of VTD-XML.
- Incremental XML modifier—You can modify an XML document incrementally through the
XMLModifier, which defines three types of "modify" operations: inserting new content into any location (i.e., offset) in the document, deleting content (by specifying the offset and length), and replacing old content with new content—which effectively is a deletion and insertion at the same location. To compose a new document containing all the changes, you need to call XMLModifier's output(...) method. - XML slicer and splicer—You can use a pair of integers (offset and length) to address a segment of XML text so your application can slice the segment from the original document and move it to another location in the same or a different document. The
VTDNav class exposes two methods that allow you to address an element fragment: getElementFragment(), which returns a 64-bit integer representing the offset and length value of the current element, and getElementFragmentNs() (in the latest version), which returns an ElementFragmentNs object representing a "namespace-compensated" element fragment. The latest version also transparently supports transcoding, so you can perform cutting and pasting across documents with different encoding formats. - XML editor— You can directly edit the in-memory copy of the XML text using
VTDNav's overWrite(...) method, provided that the original tokens you're overwriting are wide enough to hold the new byte content.
Using VTD-XML as an incremental modifier to update the text node, you basically navigate the VTD records to the right location, stick in the change, and generate a new document-- exactly the same way you would do it with Notepad. Below is a simple application updating a text node using VTD-XML:
Here are the XML documents before and after the change.
| old.xml | new.xml |
<root attr1='va'>
<b> text </b>
<c> test </c>
</root>
|
<root attr1='va' >
<b> new text </b>
<c> test </c>
</root>
|
using com.ximpleware;
namespace example1
{
class Program
{
static void Main(string[] args)
{
VTDGen vg = new VTDGen();
if (!vg.parseFile("D:/codeProject/app2/example1/example1/old.xml", true))
return;
VTDNav vn = vg.getNav();
XMLModifier xm = new XMLModifier(vn);
if (vn.toElement(VTDNav.FIRST_CHILD))
{
int i = vn.getText();
if (i != -1)
xm.updateToken(i, " new text");
}
xm.output("D:/codeProject/app2/example1/example1/new.xml");
}
}
}
XML Processing: Object Oriented vs. Document Centric
Traditional XML processing models (such as DOM, SAX, and various object data binding tools) are designed around the notion of objects. The XML text-- merely the output of object serialization-- is relegated to the status of a second-class citizen. You base your applications on DOM nodes, strings, and various business objects, but rarely on the physical documents. If you have followed my analysis so far, it's become obvious that this object-oriented approach of XML processing makes little sense as it causes performance hits from virtually all directions (an in-depth discussion on the topic can be found in "the performance woe of binary XML"). Not only are object creations and garbage collection inherently memory and CPU intensive, but applications incur the cost of re-serialization with even the smallest changes to the original text.
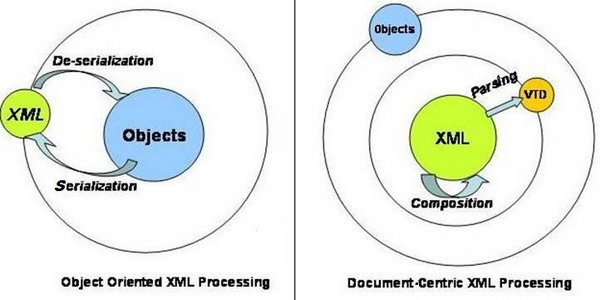
Figure 1. Object Oriented XML Processing vs. Document Centric XML Processing
What is "document-centric" XML processing? In non-extractive parsing, the XML text --the persistent data format-- is the starting point from which everything else comes about. Whether it is parsing, XPath evaluation, modifying content, or slicing element fragments, by default, you no longer work with objects. You only do that when it makes sense. More often than not, you treat documents purely as syntax, and think in bytes, byte arrays, integers, offsets, lengths, fragments, and namespace-compensated fragments. The first-class citizen in this paradigm is the XML text. And, the object-centric notions of XML processing, such as serialization and de-serialization (or marshalling and un-marshalling), as shown in Figure 1, are often displaced, if not replaced, by more document-centric notions of parsing and composition. Increasingly, you will find that your XML programming experience is getting simpler. And not surprisingly, the simpler, intuitive way to think about XML processing is also the most efficient and powerful (See Table 1 for the technical comparison of DOM and VTD-XML).
| Object Oriented XML Processing (DOM) | Document Centric XML Processing (VTD-XML) |
| Parsing | Slow due to object creation | Much faster (5x~10x of DOM) |
| Memory Usage | High (5~10x document size) | Low (1.3x~1.5x of document size) |
| Indexing | No | Yes (eliminates parsing overhead) |
| Modification | Require re-serialization | Incremental |
| Cutting, Pasting, Splitting, Splicing | No | Yes |
Table 1. Technical Comparison: OO XML Processing vs. Document Centric XML Processing
The Inflection Point for SOA
After reading many great articles posted on The Code Project, it seems to me that many readers in the community are career-long, ardent practitioners of the object oriented methodology. But in my view, OO may not always be the right tool for the job. The fact that the serialization/de-serialization problem becomes invisible when you approach XML processing from a pure object oriented perspective tells me that this design approach has practical limitations. In the world of distributed computing, the consensus is that objects don't distribute well across the process boundary (e.g., across the network). Starting from early 90's, the distributed computing community spent about 10 years attempting to figure out ways to make distributed objects (i.e., CORBA) work as if those objects reside in the same address space. But, the effort was eventually abandoned due to numerous technical issues (please visit the rise and fall of CORBA for further reading). Among those issues are tight-coupling, rigidity, and stifling complexity. It is those painful lessons of CORBA that lead us to SOA, which achieves loose-coupling and simplicity by explicitly exposing the XML messages (the wire format) as the public contract of your services. In other words, when building loosely coupled services, think in messages.
How does "document-centric" XML processing fits in, and enhances, the technical foundation of SOA? Simply put, by treating XML as documents (instead of serialization of objects), you gain not just loose coupling and simplicity, but efficiency as well. It usually doesn't make sense to think of XML in objects. Consider an SOA intermediary application that aggregates multiple services. Pretty much all it does is to splice together fragments from multiple documents to compose a single large document and shove it upstream. Where do objects come into the picture? Take the services dissemination point as another example. It is the exact opposite: large XML documents get split into multiple smaller ones, each of which is then forwarded to the respective recipient (downstream services) for further processing. Do you see the need to allocate a lot of objects? As more and more services come alive, you will discover that the composite services/applications are mostly about natively slicing, editing, modifying, splicing, and splitting documents. Traditional, object-oriented, design patterns are going to be less applicable. And, the moment you step across the boundary of OO and into a document-centric world, you will find that both the problem and solution become obvious. Everything suddenly seems to make sense again. But doing so may not be easy: you first need to have the courage to refuse to go along just to "get along," and do something that nobody around you seems to be doing. The web is undergoing a profound transformation around the concept of SOA. The experience you gained from doing SOA the right way should prove to be both rewarding and valuable in the end.

Figure 2. Slicing and Splicing XML Documents to Aggregate Services
In short, to prepare yourself for the upcoming wave of service-oriented computing, right now may be a good time to start embracing this "document-centric" view of XML processing.
Code Examples
For the rest of this article, I am going to show you how to use VTD-XML's cutting, splitting, editing, and transcoding capability to manipulate XML content with both flexibility and efficiency. To understand what the code does, each example places the input and output of the application side-by-side.
Remove an Attribute and an Element
| old.xml | new.xml |
<root attr1='va'>
<b> text </b>
<c> test </c>
</root>
|
<root attr1='va'>
<b> text </b>
<c> test </c>
</root>
|
using com.ximpleware;
namespace example2
{
class Program
{
static void Main(string[] args)
{
VTDGen vg = new VTDGen();
if (!vg.parseFile("D:/codeProject/app2/example2/example2/old.xml", true))
return;
VTDNav vn = vg.getNav();
XMLModifier xm = new XMLModifier(vn);
int i = vn.getAttrVal("attr1");
if (i != -1)
xm.removeAttribute(i - 1);
if (vn.toElement(VTDNav.FIRST_CHILD))
{
xm.remove();
}
xm.output("D:/codeProject/app2/example2/example2/new.xml");
}
}
}
Cut and Paste a Namespace Compensated Element Fragment Between Documents
| old.xml | old2.xml | new.xml |
<a>
<b> text</b>
<c> text</c>
<d> text</d>
</a>
|
='1.0'='utf-16le'
<root xmlns:bad='something'>
<ns:good xmlns:ns='' attr= 'val^'>
</ns:good>
<text> val_ </text>
</root>
|
<a>
<root xmlns:bad='something'>
<ns:good xmlns:ns='' attr= 'val^'>
</ns:good>
<text> val_ </text>
</root>
<b> text</b>
<root xmlns:bad='something'>
<ns:good xmlns:ns='' attr= 'val^'>
</ns:good>
<text> val_ </text>
</root>
<c> text</c>
<d> text</d>
</a>
|
using System;
using System.Collections.Generic;
using System.Text;
using com.ximpleware;
namespace example3
{
class Program
{
static void Main(string[] args)
{
VTDGen vg = new VTDGen();
if (vg.parseFile("D:/codeProject/app2/example3/example3/old2.xml",
true) == false)
return;
VTDNav vn = vg.getNav();
byte[] ba = null;
long l;
ba = vn.getXML().getBytes();
ElementFragmentNs efn = vn.getElementFragmentNs();
if (vg.parseFile("D:/codeProject/app2/example3/example3/old.xml",
false) == false)
return;
VTDNav vn2 = vg.getNav();
vn2.toElement(VTDNav.FIRST_CHILD);
XMLModifier xm = new XMLModifier(vn2);
xm.insertAfterElement(efn);
xm.insertBeforeElement(efn);
xm.output("D:/codeProject/app2/example3/example3/new.xml");
}
}
}
Re-Arrange Element Fragments
| input.xml | output.xml |
<root>
<a>text</a>
<b>text</b>
<c>text</c>
<a>text</a>
<b>text</b>
<c>text</c>
<a>text</a>
<b>text</b>
<c>text</c>
</root>
|
<root>
<a>text</a>
<a>text</a>
<a>text</a>
<b>text</b>
<b>text</b>
<b>text</b>
<c>text</c>
<c>text</c>
<c>text</c>
</root>
|
using System.IO;
using System.Collections.Generic;
using System.Text;
using com.ximpleware;
namespace example4
{
class Program
{
static void Main(string[] args)
{
AutoPilot ap1 = new AutoPilot();
AutoPilot ap2 = new AutoPilot();
AutoPilot ap3 = new AutoPilot();
ap1.selectXPath("/root/a");
ap2.selectXPath("/root/b");
ap3.selectXPath("/root/c");
byte[] ba1, ba2, ba3;
VTDGen vg = new VTDGen();
Encoding eg = System.Text.Encoding.GetEncoding("utf-8");
if (vg.parseFile("D:/codeProject/app2/example4/example4/input.xml", false))
{
VTDNav vn = vg.getNav();
ap1.bind(vn);
ap2.bind(vn);
ap3.bind(vn);
FileStream fos =
new FileStream("D:/codeProject/app2/example4/example4/new.xml",
System.IO.FileMode.OpenOrCreate);
ba1 = eg.GetBytes("<root />");
ba2 = eg.GetBytes("</root />");
ba3 = eg.GetBytes("\r\n");
byte[] ba = vn.getXML().getBytes();
fos.Write(ba1, 0, ba1.Length);
while (ap1.evalXPath() != -1)
{
long l = vn.getElementFragment();
int offset = (int)l;
int len = (int)(l >> 32);
fos.Write(ba3, 0, ba3.Length);
fos.Write(ba, offset, len);
}
ap1.resetXPath();
while (ap2.evalXPath() != -1)
{
long l = vn.getElementFragment();
int offset = (int)l;
int len = (int)(l >> 32);
fos.Write(ba3, 0, ba3.Length);
fos.Write(ba, offset, len);
}
ap2.resetXPath();
while (ap3.evalXPath() != -1)
{
long l = vn.getElementFragment();
int offset = (int)l;
int len = (int)(l >> 32);
fos.Write(ba3, 0, ba3.Length);
fos.Write(ba, offset, len);
}
ap3.resetXPath();
fos.Write(ba3, 0, ba3.Length);
fos.Write(ba2, 0, ba2.Length);
}
}
}
}
Edit an Indexed Template then Dump it into a File
| Input.vxl's text content | output.xml |
<a attr=' '>
<b> </b>
</a>
|
<a attr=' val '>
<b>text </b>
</a>
|
using System;
using System.Collections.Generic;
using System.Text;
using com.ximpleware;
namespace example6
{
class Program
{
static void Main(string[] args)
{
VTDGen vg = new VTDGen();
VTDNav vn = vg.loadIndex("D:/codeProject/app2/example6/example6/input.vxl");
int i = vn.getAttrVal("attr");
Encoding eg = System.Text.Encoding.GetEncoding("utf-8");
if (i != -1)
{
vn.overWrite(i,eg.GetBytes(" val"));
}
if (vn.toElement(VTDNav.FIRST_CHILD))
{
i = vn.getText();
vn.overWrite(i, eg.GetBytes("text"));
}
vn.dumpXML("D:/codeProject/app2/example6/example6/out.xml");
}
}
}
Recap and Conclusion
I hope that this article has done its job describing to you how VTD-XML fundamentally solves the common issue of DOM and SAX. The simplest problem, in my view, is also the biggest problem, not just because it affects everyone, but it is so deep that you have gotten used to it already. This is where VTD-XML again stands out. Be it parsing, indexing, modifying, cutting, splitting, or splicing XML documents, VTD-XML excels in virtually every aspect imaginable, while breaking new grounds in others. But, to reap the full benefit of VTD-XML, you need to first step out of the comfort zone of object-oriented thinking and start to think XML as documents. As the world of IT transitions towards a Services Oriented architecture, I am confident that you will discover, in many ways, that the "document-centric" approach to XML processing naturally lends itself to designing and implementing your SOA infrastructure. To me, this is why VTD-XML is the future of XML processing and why the best has to yet to come!
If you have visited VTD-XML's project site, you probably have noticed that VTD-XML has a C version that delivers the exact set of functionalities as its C# counter-part. But unlike C#, C is neither OO, nor based on VM. Worse, C doesn't even support exceptions. So, there are interesting challenges to port VTD-XML from C# to C. In the next part of this series, I will discuss how to overcome those challenges to maximize code reuse and reduce the porting effort to minimum.
Related Articles
History
- March 13 2008 - Initial submission.
- April 5 2008 - Added Related Articles section.

