Introduction
Selenium is a tool for automating Web Browsers. Instead of testing websites manually, developers use this tool to test their website automatically. It works just as though a user would be using the website on his/her system. Although it is popular for testing websites, countless boring and repetitive web tasks can and should be automated.
Let's get started.
Diagrammatic Representation
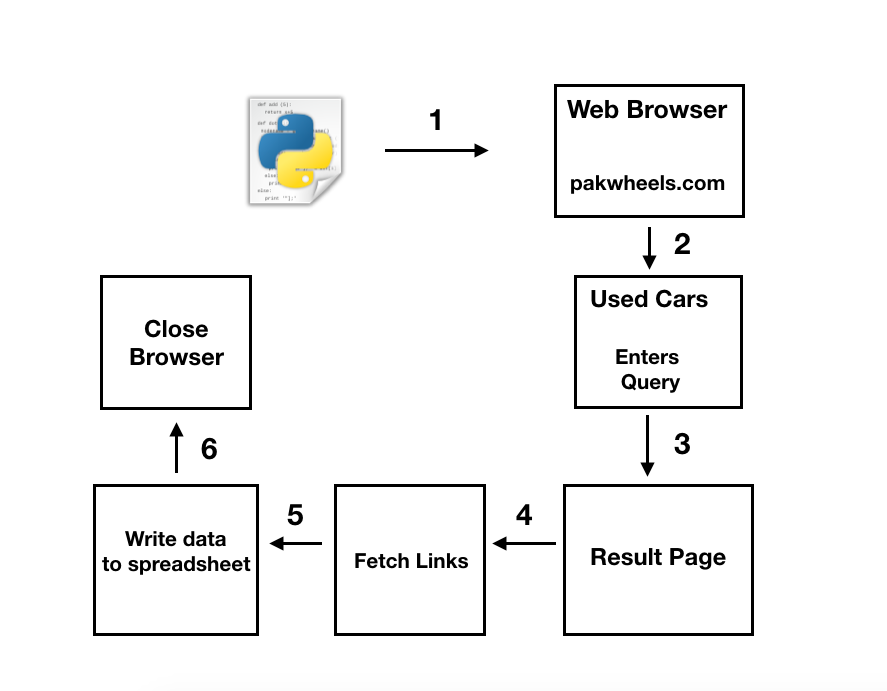
- Program opens the browser and browses to pakwheels.com.
- It further navigates to their Used Cars section and inputs the following query:
- Car Make or Model: Honda Civic
- Location: Islamabad
- Year Range: 2008 - 2012
- Price Range: 10 - 18 Lacs
- The resulted page displays 29 ads on the main page, satisfying the query.
- The program gets the links of the 29 ads.
- Saves the required data to an Excel Spreadsheet
- Finally closes the browser
Technologies Used
- Selenium: Version 3.141.0
- xlwt: Version 1.3.0
- Python: Version 3.6.5
Prerequisites
- Latest version of Firefox
- Python 3.6.5 installed
Setting Up
Note
Code Overview
In the initialization block, I'm importing all the required modules and packages, creating selenium objects such as driver and options, and I'm creating an Excel workbook with the help of xlwt.
Note
- I have initialized headless mode because it takes up less resources.
- This can be disabled if you comment out
options.add_argument('-headless').
The source code is as follows:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import Select
import xlwt
options = webdriver.FirefoxOptions()
options.add_argument('-headless')
driver = webdriver.Firefox(firefox_options=options)
workbook = xlwt.Workbook()
The program has three functions in total:
navigation()
The following function navigates to the used "Honda Civic" page.
- Opens up the browser and browses to pakwheels
- Waits for the pop-up to show up to close it
- Clicks on Used Cars
- Inputs the query
- Clicks on search
- Goes to the main page of the resulted query
The source code is as follows:
"""
- The function below, when called,
opens up the browser and goes to wwww.pakwheels.com and then navigates to their
used cars section.
- It then inserts queries into their query bar such as:
Car Make Model
City
Price Range
From - To Year
- Finally it clicks on the search button and the page with the inserted criteria opens
"""
def navigation():
driver.get("https://www.pakwheels.com")
WebDriverWait(driver, 500).until(EC.element_to_be_clickable_
((By.ID, 'onesignal-popover-cancel-button')))
driver.find_element_by_id('onesignal-popover-cancel-button').click()
time.sleep(5)
driver.find_element_by_link_text('Used Cars').click()
driver.find_element_by_id('more_option').click()
driver.find_element_by_name('home-query').send_keys('Honda Civic')
driver.find_element_by_class_name('chzn-single').click()
driver.find_element_by_id('UsedCity_chzn_o_4').click()
pr_range = driver.find_element_by_id('pr-range-filter')
pr_range.click()
driver.find_element_by_id('pr_from').send_keys('10')
driver.find_element_by_id('pr_to').send_keys('18')
pr_range.click()
yr_from = Select(driver.find_element_by_id('YearFrom'))
yr_to = Select(driver.find_element_by_id('YearTo'))
yr_from.select_by_value('2008')
yr_to.select_by_value('2012')
driver.find_element_by_id('used-cars-search-btn').click()
get_car_links()
I'm calling the navigation() function inside this so that selenium can navigate to the desired page.
The function does the following:
- Creates an empty list called links.
- Gets all the anchor tags of the Honda Civic ads.
- Through a
for-loop, appends all the href of the anchor tags in the links list. - Finally returns the list
The source code is as follows:
'''
- This function gets all the required links.
- Firstly it gets all the Anchor tags that has the required links
(class = "car-name ad-detail-path")
- Then through the for-loop, it further parses the anchor tags to get
the href from the anchor tags one by one and appends it to another list
called as links and returns that list.
'''
def get_car_links():
navigation()
links = []
elems = driver.find_elements(By.XPATH, '//a[@class = "car-name ad-detail-path"]')
for elem in elems:
links.append(elem.get_attribute('href'))
return links
scrape_output()
The final function takes in the list that has the links and does the following:
- Creates a sheet in the workbook
- Adds headings of the data that will be furnished in the workbook
- The
for-loop loops through the links and:
- Opens up the link
- Scrapes the data:
- Phone Number
- Milage
- Year
- Transmission
- Price
- Engine Capacity
- Color
- Registered City
- Writes the scraped data in the Workbook with the ad's link as well.
- These steps are done till the list is empty.
- And finally, saves the Workbook with the name "
output".
The source code is as follows:
'''
- The last function takes the returned list from the upper function.
- A new workbook is created and a sheet is added by the name of Report.
- The function scrapes the required data:
phone number
milage
car_year
transmission
price
engine_capacity
color
registration
and finally writes it to the worksheet with the ads' link as well.
'''
def scrape_output(links):
style = xlwt.easyxf('font: bold 1')
sheet1 = workbook.add_sheet('Report')
sheet1.write(0, 0, 'Phone Number', style)
sheet1.write(0, 1, 'Milage', style)
sheet1.write(0, 2, 'Year', style)
sheet1.write(0, 3, 'Transmission', style)
sheet1.write(0, 4, 'Price', style)
sheet1.write(0, 5, 'Engine Capacity', style)
sheet1.write(0, 6, 'Color', style)
sheet1.write(0, 7, 'Registration', style)
sheet1.write(0, 8, 'Link', style)
row = 1
for link in links:
driver.get(link)
driver.find_element(By.XPATH, '//button[@class =
"btn btn-large btn-block btn-success phone_number_btn"]').click()
phone_number = driver.find_element(By.XPATH, '//*[@id="scrollToFixed"]/
div[2]/div[1]/button[1]/span').text
milage = driver.find_element(By.XPATH,
'//*[@id="scroll_car_info"]/table/tbody/tr/td[2]/p').text
car_year = driver.find_element(By.XPATH,
'/html/body/div[2]/section[2]/div/div[2]/div[1]/div/table/tbody/tr/td[1]/p').text
transmission = driver.find_element(By.XPATH,
'//*[@id="scroll_car_info"]/table/tbody/tr/td[4]/p').text
price = driver.find_element(By.XPATH,
'//*[@id="scrollToFixed"]/div[2]/div[1]/div/strong').text
engine_capacity = driver.find_element(By.CSS_SELECTOR,
'
color = driver.find_element(By.CSS_SELECTOR,
'#scroll_car_detail > li:nth-child(4)').text
registration = driver.find_element(By.CSS_SELECTOR,
'#scroll_car_detail > li:nth-child(2)').text
sheet1.write(row, 0, phone_number)
sheet1.write(row, 1, milage)
sheet1.write(row, 2, car_year)
sheet1.write(row, 3, transmission)
sheet1.write(row, 4, price)
sheet1.write(row, 5, engine_capacity)
sheet1.write(row, 6, color)
sheet1.write(row, 7, registration)
sheet1.write(row, 8, link)
row += 1
workbook.save('output.xls')
Finally, the last bits of code.
In the try block, I'm chaining scrape_output() and get_car_links().
Finally, it closes the browser.
try:
print('Starting')
car_links = get_car_links()
scrape_output(car_links)
finally:
print('Done')
driver.quit()
Note
This project can also be viewed on my GitHub repo.

