Introduction
Skip to the results
There is a performance penalty when using P/Invoke to cross the managed/unmanaged boundary. But how serious is this penalty? Can this penalty be reduced by not using
P/Invoke, but writing a C++/CLI library that exposes functions from a traditional API?
In this article, we will look into the performance of P/Invoke compared to a C++/CLI wrapper.
Background
I am currently working on the new version of my OpenGL wrapper and Scene Graph called SharpGL
(http://www.codeproject.com/KB/openGL/sharpgl.aspx).
OpenGL is a very 'talkative' API - the functions are called many thousands of times per second. Whilst working on this library I wondered, would it be faster
to write a C++/CLI class library to expose OpenGL functions or would it be faster to P/Invoke them directly? A brief Google suggested a C++/CLI wrapper but I wanted to look into this further.
I have written a tiny API called 'TraditionalAPI' which exposes three functions - this project invokes the functions a number of times using different methods.
Part 1: The Traditional API
The traditional API exposes three basic functions:
Test Function 1: IncrementCounter
This is the most basic function I could come up with, testing this function should be a good way of testing the overhead of a P/Invoke call:
unsigned int g_uCounter = 0;
TRADITIONALAPI_API void __stdcall TA_IncrementCounter()
{
g_uCounter++;
}
Test Function 2: Square Root
The second function calculates the square root of a double. No complicated marshalling should be required:
TRADITIONALAPI_API double __stdcall TA_CalculateSquareRoot(double dValue)
{
return ::sqrt(dValue);
}
Test Function 3: Dot Product
The next function calculates the dot product of two three-tuples. This function takes two arrays - so in the managed world we will have to pin memory to marshal this:
TRADITIONALAPI_API double __stdcall TA_DotProduct(
double arThreeTuple1[], double arThreeTuple2[])
{
return arThreeTuple1[0] * arThreeTuple2[0] + arThreeTuple1[1] *
arThreeTuple2[1] + arThreeTuple1[2] * arThreeTuple2[2];
}
Part 2: The C++/CLI Wrapper
The second part of the solution is a C++/CLI wrapper that wraps each function:
Test Function 1 Wrapper
void IncrementCounter()
{
::TA_IncrementCounter();
}
Nothing special here - this is a C++/CLI class so we will be able to call IncrementCounter from another .NET application.
Test Function 2 Wrapper
double CalculateSquareRoot(double value)
{
return ::TA_CalculateSquareRoot(value);
}
Again, nothing complicated is required for this function.
Test Function 3 Wrapper
double DotProduct(array<double>^ threeTuple1, array<double>^ threeTuple2)
{
pin_ptr<double> p1(&threeTuple1[0]);
pin_ptr<double> p2(&threeTuple2[0]);
return TA_DotProduct(p1, p2);
}
Now in this case, we actually have to do some work - pinning the managed arrays so that we can access them directly in the unmanaged API.
Part 3: The C# Test Application
The final part of the solution is a C# WPF application that runs the tests. The TraditionalAPI DLL can run each test function individually or run each test a number of times.
Because of this, we can compare the following:
- The time taken to run x tests directly in TraditionalAPI
- The time taken to run x tests via the C++/CLI interface
- The time taken to run x tests via P/Invoke
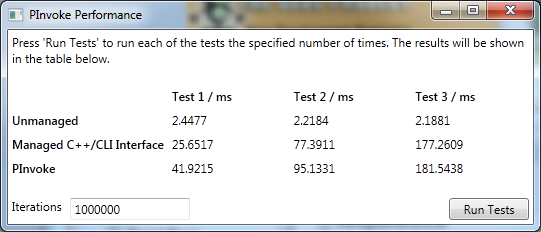
The Results
Below we have the results of running each test 10000 times:

And the results of running each test 100000 times:
Conclusion
Certainly not what I would have expected. According to my research, I was expecting to see the C++/CLI interface be at least an order of magnitude faster - as it does less error
checking than a P/Invoke call. Even in the case of a million function calls, the C++/CLI interface is barely faster than using P/Invoke.
As we would expect, the cost of calling any native function from a CLI application is very high if we are calling it many times - in the case of using a very talkative
API, it may even be worth writing a second C++ API that takes an aggregated set of parameters and calls the functions many times - the managed to unmanaged boundary is expensive.
Further Research
Has anyone found a case where a C++/CLI wrapper really does give a solid performance boost? Is there another way to do this that I have overlooked? Please provide
any suggestions and I will update the article as necessary.

