Introduction
In computer vision, you very often have to perform an image convolution operation with some filter. Examples are image enhancements, edge detection, Gaussian smoothing, or object detection using projection of the image into a low dimensional space represented with PCA, LDA, ICA, MP, or any other set of vectors. Having a bigger sized image makes the operation more time consuming. Recently, I found a great article, Face Detection - Efficient and Rank Deficient, where the authors apply a method to the rank deficient approximation of the support vector machine (SVM) classifier. With rank deficient approximation, the ordinary convolution taking O(w*h) filtering operations can perform as fast as O(w+h) operations only, where w and h are sizes of the image. So, I decided to code the method for my own computer vision proceedings and see the performance.
Background
In this article, the vec2D class is extended from my 2D Vector Class Wrapper SSE Optimized for Math Operations article. If you are not familiar with convolution operations, have a look at the Wiki.
Algorithm
Having some linear filter H and applying it to an image I results in a 2D convolution operation:
J = I * H;
So, J is the same size as I.
If H has size h x w, the convolution requires O(h*w) operations for each output pixel. However, in special cases, where H can be decomposed into two column vectors a and b, such that:
H = ab';
the convolution becomes:
J = [I * a] * b';
Since the convolution is associative, and in this case, ab' = a * b'. This splits the original convolution operation into two operations with vectors of size h x 1 and 1 x w, respectively. As a result, if a linear filter is separable (H = ab'), the computational complexity of the filtering operation drops from O(h*w) to O(h + w) per pixel.
The singular value decomposition, SVD, is used to decompose the H filter to a and b vectors.
H = USV';
U and V are orthogonal matrices of size h x h and w x w. S is a diagonal (the diagonal entries are the singular values) and has size h x w. Let r = rank(H). Due to rank(S) = rank(H), we may write H as a sum of r rank one matrices.
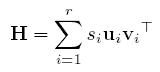 (1)
(1)
Where s denotes the ith singular value of H, and u, v are the ith columns of U and V (i.e., the ith singular vectors of the matrix H), respectively. As a result, the corresponding linear filter can be evaluated as the weighted sum of r separable convolutions:
 (2)
(2)
And the computational complexity drops from O(h * w) to O(r * (h + w)) per output pixel. The speed benefit depends on r, which can be seen to measure the structural complexity of H.
You can choose r until the reconstruction error for the H filter in (1) decreases below some threshold. Apparently, the more complex the filter (i.e., the more high frequency components it contains), a bigger r is needed, but simple filters as Gaussian can be approximated with great precision, for r = 1.
Below some Eigen face is presented:
And its reconstruction after 1, 2, and 3 iterations (i.e., r = 1, 2, and 3):
As can be seen, the MSE decreases as r increases.
Using the code
Below, an ordinary convolution and a rank deficient one are presented:
void vec2D::conv2(const vec2D& a, const vec2D& filter,
enum CONV type) {
int l = filter.height() / 2;
int m = filter.width() / 2;
vec2D& c = *this;
if (type == SAME) { for (int i = 0; i < (int)c.height(); i++) {
for (int j = 0; j < (int)c.width(); j++) {
float tmp = 0;
for (int u = i - l; u <= i + l; u++)
for (int v = j - m; v <= j + m; v++)
tmp += filter((i-u)+l, (j-v)+m) * a.get(u, v);
c(i, j) = tmp;
}
}
}
else if (type == VALID) { for (int i = l; i < (int)a.height() - l; i++) {
for (int j = m; j < (int)a.width() - m; j++) {
float tmp = 0;
for (int u = i - l; u <= i + l; u++)
for (int v = j - m; v <= j + m; v++)
tmp += filter((i-u)+l, (j-v)+m) * a(u, v);
c(i - l, j - m) = tmp;
}
}
}
}
With enum vec2D::CONV, you can choose a Matlab like style to perform the convolution when the output array equals the size of the convolved one, or convolve only the region of the image where the filter fits without zero-padding.
void vec2D::conv2(const vec2D& a, const std::vector<vec2D>& u, const std::vector<vec2D>& v, const vec2D& s, vec2D& tmp1, vec2D& tmp2, enum CONV type)
{
vec2D& c = *this;
c.set(0.0);
for (unsigned int i = 0; i < s.width(); i++) {
tmp1.conv2(a, u[i], type);
tmp2.conv2(tmp1, v[i], type);
tmp2.mul(s(0, i));
c.add(c, tmp2);
}
}
With the rank deficient function, you need to provide u and v vectors in std::vector arrays, s is the row vector of singular values, and tmp1, tmp2 are temporary buffers. I commented out their sizes for VALID convolution.
If you're going to perform your image projection onto some PCA, LDA, ICA, or the like basis, remember to rotate your filter before SVD, or rotate u, v vectors before calculating the convolution.
void vec2D::fliplr()
{
vec2D& c = *this;
float tmp;
for (unsigned int i = 0; i < width() / 2; i++) {
for (int y = yfirst(); y <= ylast(); y++) {
tmp = c(y, xfirst() + i);
c(y, xfirst() + i) = c(y, xlast() - i);
c(y, xlast() - i) = tmp;
}
}
}
void vec2D::flipud()
{
vec2D& c = *this;
float tmp;
for (unsigned int i = 0; i < height() / 2; i++) {
for (int x = xfirst(); x <= xlast(); x++) {
tmp = c(yfirst() + i, x);
c(yfirst() + i, x) = c(ylast() - i, x);
c(ylast() - i, x) = tmp;
}
}
}
void vec2D::rotate180()
{
vec2D& c = *this;
c.fliplr();
c.flipud();
}
Results
The convolution results for a 192x256 array with a 19x19 filter are presented bellow. First is the original image to convolve with Eigen face:
The rank deficient convolution for r = 1, 2, 3 and the ordinary convolution of that image are presented below:
As can be seen, as r increases, the MSE between ordinary convolution results and the rank deficient one decreases.
And, the timing of the convolutions follows:
SAME
J = I * H processing time: 142.258583 ms
J = sum (s[i] [I * u[i]] * v[i]'); i < 1 processing time: 20.521044 ms
J = sum (s[i] [I * u[i]] * v[i]'); i < 2 processing time: 42.043612 ms
J = sum (s[i] [I * u[i]] * v[i]'); i < 3 processing time: 63.772351 ms
VALID
J = I * H processing time: 88.931973 ms
J = sum (s[i] [I * u[i]] * v[i]'); i < 1 processing time: 14.583697 ms
J = sum (s[i] [I * u[i]] * v[i]'); i < 2 processing time: 28.884118 ms
J = sum (s[i] [I * u[i]] * v[i]'); i < 3 processing time: 42.637542 ms
For the linear rank deficient filters convolution, the results are presented for 1, 2, and 3 iterations.
The SAME mode gives you the resultant J array of the same size as I, applicable for image filtering (e.g., Gaussian smoothing, edge detection, image enhancements). The VALID is the convolution where the filter is entirely fit into the J array without zero-padding, so the resultant J array is smaller to the original I. The latter is applicable for image projection onto some basis (e.g., PCA, LDA, ICA, MP, Gabor filters etc...) when you need to analyze the regions in the image where the filter is fitted without zero-padding (e.g., face, car, or any other object detection in computer vision tasks).

