Introduction
A performance engineering engagement has been conducted for one of the leading automobile insurance companies in Canada. As per the customer decision to reduce operational and maintenance expenditure, the data residing in different data stores like DB2 and Oracle were transferred to a consolidated repository maintained in SQL Server 2008. The existing Java client applications communicating with either DB2/Oracle 10g were remediated to communicate with SQL Server.
Though the modified environment could meet the functional expectations, there were some setbacks in the application behavior in terms of performance and scalability.
It was observed that most of the performance issues addressed as part of this exercise could be quite common across any data migration project to SQL Server. The basic idea of preparing this artifact is to address these reoccurring performance issues, thus saving the potential risks and execution effort.
Environmental details
| Existing Environment | Target Environment |
| Operating System | IBM AIX | Windows 2008 R2 (64 bit) |
| DB Version (DB2) | DB2 9.1 Fix Pack 7 | SQL Server 2008 (64 bit) |
| DB Version (Oracle) | Oracle 8i | SQL Server 2008 (64 bit) |
Tools used
| Name of Tool | Purpose | Specific requirements |
| Perfmon | System monitoring tool to record and gather performance statistics from counters defined on server. | N/A |
| SQL Profiler | SQL Server Profiler is a diagnosing tool that captures SQL events related to the server and can be utilized to analyze problematic queries. The events can also be recorded/saved on to a trace file for further analysis in offline mode. | Compatible with SQL Server 2005/2008 |
| i-SSMA | Infosys in-house tool to migrate DB2 database from legacy platforms like Mainframe to Microsoft SQL Server 2005/2008. | N/A |
| SSMA for Oracle | Tool provided by Microsoft to migrate data from Oracle to SQL Server 2005/2008. | N/A |
Performance sensitive areas in migration
Below mentioned are some of the major performance sensitive areas that needs to be monitored on data migration to SQL Server:
- If the client is Java related, communication between client and SQL Server
- Row level triggers in SQL Server
- Referential integrity through triggers in SQL Server
- Multiple after triggers and rollbacks
- Recursive and nested triggers in SQL Server
- Extended Stored Procedures
- Nested cursors
- Case-sensitivity and collation
Each of these topics would be further discussed in detail.
Communication between Java client and SQL Server
The end to end transaction from a Java client to SQL Server was taking more than 20 minutes to respond. Though the Java client had inline queries (dynamic SQL), the same transaction was taking around 5 sec in the existing application.
Below are the observations made:
- The SQL trace captured depicted that most of the queries' execution time was higher along with the high disk reads and writes.
- The queries execution time was higher even when they are fired from the backend.
- Table scans were occurring for most of the queries.
On remediating the necessary indexes manually on SQL Server, table scans and queries execution time triggered at back end were minimized. This could bring down the transaction time from 20 minutes to around 8 minutes, still way ahead of the SLA.
Apart from the missing indexes issue identified, the transaction was still taking more time to execute when triggered from the front-end. The below pattern has been noticed in the SQL trace when queries are fired using JDBC drivers for the time consuming transactions.
From this pattern, it is obvious that communication between the Java application and SQL Server was happening using Unicode (NVARCHAR in bold).
declare @p1 int
set @p1=1073786063
declare @p2 int
set @p2=180238477
declare @p7 int
set @p7=-1
exec sp_cursorprepexec @p1 output,@p2
output,N'@P0nvarchar(4000)',N'<<SEARCH/DML Queries>>',4112,8193,@p7
output,N'F7248180-273'
select @p1, @p2, @p7
There could be a performance problem with respect to communication between a Java client and the SQL Server using Java drivers. Most of the Java drivers pass string parameters to SQL Server as Unicode, by default. The problem here is, if the Unicode parameters reference the VARCHAR key columns in an index, the SQL Server engine will not use the appropriate index for query resolution, thereby increasing the unwanted table scans.
This can be corrected by resetting one of the default parameter in the Java driver. The parameter name and value to be set might vary from driver to driver, depending on the vendor.
| Vendor | Parameter |
| JSQLConnect | asciiStringParameters |
| JTDS | sendStringParametersAsUnicode |
| DataDirectConnect | sendStringParametersAsUnicode |
| Microsoft JDBC | sendStringParametersAsUnicode |
| WebLogic Type 4 JDBC | sendStringParametersAsUnicode |
The below statistics are captured by running one of the queries used by the transaction, with both "sendStringParametersAsUnicode" as true and false:
| sendStringParametersAsUnicode | CPU | Reads | Writes | Duration (ms) |
| True (default setting) | 6718 | 220916 | 0 | 1866 |
| False | 0 | 36 | 0 | 0 |
By making this change, the transaction which was taking around 8 minutes reduced drastically to 5 sec.
Row level triggers in SQL Server
One of the major differences between Oracle and SQL Server triggers is that the most common Oracle trigger is a row-level trigger (FOR EACH ROW) that initiates for each row of the source statement. SQL Server supports only statement-level triggers, which fire only once per statement, regardless of the total number of rows affected. The basic conversion rules used by SSMA for Oracle for triggers conversion are (as per SSMA for Oracle conversion guide):
- All
BEFORE triggers for a table are converted into one INSTEAD OF trigger. AFTER triggers remain AFTER triggers in SQL Server.INSTEAD OF triggers on Oracle views remain INSTEAD OF triggers.- Row-level triggers are outdone with a cursor loop.
Each trigger initiated would acquire a lock on the table and is released once the action is complete. Even with the least resource intensive cursor configuration (FAST FORWARD, READ ONLY), the performance of the trigger might be affected from the following:
- Number of rows iterated through the cursor
- SQL statements against other tables external to the inserted or deleted tables.
Locking issues or hanging of batch execution has been observed at many instances in the transaction flow, for row level triggers with cursors.
Microsoft also recommends minimizing the cursor usage wherever applicable, due to their high resource consumption nature. The best practice is to keep the trigger logic simple. If the business case is to loop across the modified rows inside the trigger, table variables (temp tables) or row set logic would be preferred over cursors.
Referential Integrity through triggers in SQL Server
Referential Integrity is the feature provided by RDBMSs to prevent the entry of inconsistent data. Referential Integrity can be imposed in SQL with two mechanisms:
- Data Referential Integrity (DRI) constraints imposed through foreign keys
- Triggers
Imposing DRI by means triggers might lead to prolonged actions in triggers and locking issues. The life of the transaction might be extended on any integrity violation which requires rollback. This is explained in the below Customer-Order relationship sample:
CREATE TABLE DBO.CUSTOMER_TABLE
(
CUSTOMER_ID INT IDENTITY (1,1) NOT NULL PRIMARY KEY,
CUSTOMER_NAME VARCHAR (50) NOT NULL,
CONTACT_NUMBER INT NOT NULL UNIQUE
)
CREATE TABLE DBO.ORDER_TABLE
(
ORDER_ID INT IDENTITY (1,1) NOT NULL PRIMARY KEY,
CUSTOMER_ID INT,
ORDER_QTY INT NOT NULL,
ORDER_DATE DATETIME NOT NULL
)
CREATE TRIGGER DBO.tr_CUSTOMER_TABLE_DELETE ON DBO.CUSTOMER_TABLE
FOR DELETE
AS
SET NOCOUNT ON
IF EXISTS (SELECT 1 FROM DBO.ORDER_TABLE OT JOIN DELETED D ON D.CUSTOMER_ID = OT.CUSTOMER_ID)
BEGIN
RAISERROR ('Customer has orders listed. Record will not be deleted.', 16,10)
WAITFOR DELAY '00:00:15'
ROLLBACK
END
GO
INSERT INTO DBO.CUSTOMER_TABLE (CUSTOMER_NAME,CONTACT_NUMBER) SELECT 'CUST 1',123456789
INSERT INTO DBO.ORDER_TABLE (CUSTOMER_ID,ORDER_DATE, ORDER_QTY) SELECT 1,'12/10/2010',20
INSERT INTO DBO.ORDER_TABLE (CUSTOMER_ID,ORDER_DATE, ORDER_QTY) SELECT 1,'12/12/2010',40
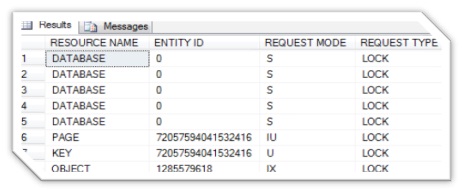
On deleting the customer record, locking issues would be detected as depicted below:
SELECT RESOURCE_TYPE AS [RESOURCE NAME],
RESOURCE_ASSOCIATED_ENTITY_ID AS [ENTITY ID],
REQUEST_MODE AS [REQUEST MODE],
REQUEST_TYPE AS [REQUEST TYPE]
FROM sys.dm_tran_locks
Recursive execution in nested triggers
There are two kinds of recursion in SQL Server:
Direct recursion: This type of recursion occurs when a trigger is fired that accomplishes some action that would cause the same trigger to initiate again.
In-direct recursion: This recursion occurs when a trigger is fired that accomplishes some action that would cause the same type (AFTER or INSTEAD OF) to fire. This second trigger executes an action that would cause the original trigger to activate again.

(Figure depicting one of the scenarios for direct and in-direct recursion)
An AFTER trigger does not call itself recursively unless the RECURSIVE_TRIGGERS database option is set. When the RECURSIVE_TRIGGERS database option is set to OFF, only direct recursion of AFTER triggers is prevented.
Multiple concurrent requests and triggers running under the scope of transactions might always lead to locking issues.
Indirect recursive execution for AFTER triggers can be prevented by:
- To disable “nested triggers”, the server option should be set to 0. By default, the option is set to 1. This can be checked by running the below query:
SELECT * FROM SYS.CONFIGURATONS WHERE CONFIGURATION_ID = 115
Using “IF UPDATE ()”: Returns a Boolean value indicating that an INSERT or UPDATE attempt was made on a stated column of a table or view. UPDATE () can be used anywhere inside the body of a Transact-SQL INSERT or UPDATE trigger to test whether the trigger should execute certain actions.
Extended Stored Procedures
User-defined functions in SQL Server cannot contain DML statements and cannot invoke Stored Procedures. Whereas Oracle functions can do basically the same what procedures in SQL Server can. The workaround used by SSMA for Oracle implements a function body as a Stored Procedure (<<function name>>$IMPL) and invokes it within the function by means of an extended procedure, wrapper for calling the $IMPL Stored Procedure.
The conversion sample is as follows (as per the Microsoft guidelines to migrate data from Oracle to SQL Server 2008, http://www.microsoft.com/sqlserver/2008/en/us/migration.aspx):
CREATE FUNCTION [schema.] <function_name>
(
<parameters list>
)
RETURNS <return_type>
AS
BEGIN
DECLARE @spid INT, @login_time DATETIME
SELECT @spid = sysdb.ssma_ora.get_active_spid(),@login_time = sysdb.ssma_ora.get_active_login_time()
DECLARE @return_value_variable <function_return_type>
EXEC master.dbo.xp_ora2ms_exec2_ex @@spid,
@login_time,
<database_name>, <schema_name>, <function_implementation_as_procedure_name>,
bind_to_transaction_flag, [parameter1, parameter2, ... ,] @return_value_variable OUTPUT
RETURN @return_value_variable
END
Extended Stored Procedures provide a way to dynamically load and execute a function within a dynamic-link library (DLL) in a manner similar to that of a Stored Procedure, seamlessly extending SQL Server functionality. Actions outside of SQL Server can be easily triggered and external information returned to SQL Server.
In cases where possible, SSMA will try to control the calling of these functions directly (making a direct call to the appropriate ...$IMPL SP instead), but some cases are not supported. These kinds of cases will result in a direct call to the generated wrapper function (which in-turn calls the extended Stored Procedure), which are quite slow and can lead to deadlocks.
One of the suggested ways is to call SQL Server code to use func_name$IMPL Stored Procedures directly (just using normal EXECs, and not calling wrapper functions).
Nested cursors
As discussed earlier in the “Row level triggers” section, Microsoft recommends minimizing the usage of cursors. Cursors force the database engine to recurrently procure rows, negotiate blocking, manage locks, and transmit results. Due to this, there might be more usage of locks than required, and there would be an impact on the tempdb database.
The impact varies according to the type of cursor used. The level of cursors used in the nested cursor would also impact the batch performance. The sample code for the nested Stored Procedure would be as follows:
DECLARE @ObjectId Varchar(16)
DECLARE @childId Varchar(16)
DECLARE @ParentId Varchar(16)
DECLARE @CurrentStatus Int
DECLARE MajorCursor CURSOR FOR
SELECT ObjectId, ParentId FROM MainTable
OPEN MajorCursor
FETCH NEXT FROM MajorCursor INTO @ObjectId, @ParentId
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE innerCursor CURSOR FOR
SELECT CHILD_ID FROM ChildTable WHERE ENTY_ID = @ParentId
OPEN innerCursor
FETCH NEXT FROM innerCursor INTO @childId
SET @CurrentStatus = @@FETCH_STATUS
WHILE @CurrentStatus = 0
BEGIN
FETCH NEXT FROM innerCursor INTO @childId
SET @CurrentStatus = @@FETCH_STATUS
END
CLOSE innerCursor
DEALLOCATE innerCursor
FETCH NEXT FROM MajorCursor INTO @ObjectId , @ParentId
END
CLOSE MajorCursor
DEALLOCATE MajorCursor
There were multiple instances in the code with nested cursors and even with the triggers having cursor implementation. Most of the locking issues in the package flow could be reduced by changing the cursor code to temporary variable code.
Case sensitivity and collation
The possible combinations of data types and collation types in SQL Server are depicted as below:
| Column Data types | Collation | Sorting rules applied by SQL Server engine | Impact on performance |
Non-Unicode (CHAR, VARCHAR, TEXT) | SQL | Non-Unicode | Faster, but unreliable for certain collations |
Non-Unicode (CHAR, VARCHAR, TEXT) | Windows | Unicode | Slightly slower than SQL collation, but reliable |
Unicode (NCHAR, NVARCHAR, NTEXT) | SQL/Windows | Unicode | Slow for both collations |
The Unicode sorting rules applied by the SQL Server engine are much more complex than the rules applied for a non-Unicode SQL sort order. When SQL Server associates Unicode data, the characters are consigned a weight that is dynamically modified depending on the collation's locale. Unicode sorting rules apply to all Unicode data types, defined by using either a SQL collation or a Windows collation.
- SQL Server uses non-Unicode sorting rules when non-Unicode data types are defined by using a SQL collation. Though sorts and scans using this collation are generally faster than Unicode rules, they are unreliable for certain collations.
- SQL Server performs string comparisons of non-Unicode data types defined with a Windows collation by means of Unicode sorting rules. Since these rules are of high complexity than non-Unicode sorting rules, they are more resource-intensive. So, even though Unicode sorting rules are frequently more expensive, there is generally a slight difference in terms of performance between Unicode data and non-Unicode data defined with a Windows collation.
- Unicode data sorting can be slower than non-Unicode because of double bytes storage and is also dependent on the amount of data to be sorted. In addition to this, sorting Asian DBCS (Double Byte Character Set) data in a specific code page is much slower than sorting Asian characters, because DBCS data is actually a mixture of single-byte and double-byte widths, while Unicode characters are fixed-width.
- There might be other performance issues primarily determined by the issue of converting the encrypting mechanism between the client instance of SQL Server. The decision on the type of data types to be used for collation might be determined by the amount of sorting, conversion, and possible data corruption that might happen during customer interaction with the data. Frequent sorting of lots of data with a Unicode storage mechanism might severely affect performance.
Windows collations provide consistent string comparisons for both non-Unicode and Unicode data types, and are also consistent with string comparisons in the Windows Operating System for non-Unicode text in SQL Server. Due to these factors, Windows collations would be most preferred unless there are issues related to backward compatibility or any precise performance issues that entail a SQL collation.
References
- Improving SQL Performance (http://msdn.microsoft.com/en-us/library/ff647793.aspx)
- Exploring SQL Triggers (http://msdn.microsoft.com/en-us/magazine/cc164047.aspx)
- Troubleshooting performance problems in SQL Server (http://technet.microsoft.com/en-us/library/cc966540.aspx)
- Comparing SQL collations to Windows collations (http://support.microsoft.com/kb/322112)

