This article discusses UDT from the technical perspective, by taking you step by step in creating one. Along the way, you will discover quirks, inconsistencies, obscure settings, and workarounds.
Contents
Have you tried searching for anything about SQL Server User Defined Type (UDT) in your favorite developer portal? More often than not, you’ve ended up finding something that ultimately culminates to debates about the author’s choice of model or whether UDT does have a place in software development at all. Argumentations like these are healthy for experienced developers, but for a beginner, they can be frustrating. I’ve been in those shoes before, and being an open-minded person, I did not care about what other people said, because they would just distract me from my focus on learning something that has the greatest potential of changing the way we develop database applications.
This article provides exactly those things I craved for when I was still writing my first UDT. It discusses UDT from the technical perspective, by taking you step by step in creating one. Along the way, you will discover quirks, inconsistencies, obscure settings, and workarounds. Different ways of implementing your UDT in terms of settings and .NET types are also discussed and pitted against each other, just to find out if common conceptions about them indeed translate to real-world behaviors.
A less conventional approach is employed for this article, by focusing primarily on the concepts that influence the structure and behaviors of UDT rather than the codes that implement them. This makes the text more verbose than your typical technical article, so people with short attention deficit, you’ve been warned. As for those who are happy to know the causes of things, read on!
A User Defined Type (UDT) is a SQL Server data type created using your favorite .NET language. It is one of the artifacts you can create with SQL Server CLR Integration (SQL-CLR for short). Let’s just say it’s the closest thing SQL Server can get to object-based programming.
In a blatant gesture that would probably earn ire to the purists, we’re going to model an entity which is, of course, not a scalar – the vector. A vector is a quantity composed of a magnitude and a direction. We confine our discussion to the two dimensional vector which can be represented in the Cartesian coordinate system using two points, with one being understood as the origin (0,0). Our vector is then isomorphic to the polar coordinate and thus, can also be used to represent the said entity. The unit for direction is radian, for easy manipulation in .NET and T-SQL. Examples of vectors are velocity, acceleration, force, and magnetic fields. I won’t elaborate much about vector anymore, because the Internet has lots of good materials about it. For those who need some refresher on the model and other concepts applied here, these are some good resources:
Our vector is a simplified model of its real world counterpart. It is small, and the implementations of the members are naïve. It’s not industrial strength; having only enough members to illustrate the different capabilities of a UDT. We opted for a simplified model so we can concentrate on the main objective of the article, which is just to show you how to create a UDT, and not how to choose the right entity to model, let alone perfect it.
A UDT can be implemented using a struct (structure in VB.NET) or a class. The struct is recommended because it is stored in the stack, and is generally faster. Being a set-based language, SQL can rip this benefit in transactions involving very high numbers of rows. It also requires less coding than the class counterpart. We’ll know later with our informal tests if there is really truth about all these theoretical claims.
The code in this article uses .NET 2.0, and runs against SQL Server 2005 and 2008. I refrained from using features of the later versions of the .NET Framework as much as possible to maintain backwards compatibility. The changes made for UDT in SQL Server 2008 is so subtle and there's a dedicated small section on that at the latter part of the article.
A UDT, like any other artifact in SQL-CLR, is integrated to SQL Server via a .NET assembly. To do this, you should create a class library project. The only relevant assemblies for the project are System, System.Data, and System.Xml, so you can delete the rest that Visual Studio imports by default. The initial implementation of our model is shown below:
Imports System
Namespace MathSqlObj
Public Structure Vector
Private _magnitude As Double
Private _direction As Double
Public Property Magnitude() As Double
Get
Return _magnitude
End Get
Set(ByVal value As Double)
_magnitude = value
End Set
End Property
Public Property Direction() As Single
Get
Return _direction
End Get
Set(ByVal value As Single)
_direction = value
End Set
End Property
End Structure
End Namespace
using System;
namespace MathSqlObj
{
public struct Vector
{
double _magnitude;
float _direction;
public double Magnitude
{
get { return _magnitude; }
set { _magnitude = value; }
}
public float Direction
{
set { _direction = value; }
get { return _direction; }
}
}
}
Fig. 1 - Basic vector struct
To turn our struct into a UDT, we need to adorn it with the SqlUserDefinedTypeAttribute found in the Microsoft.SqlServer.Server namespace. This tells the compiler that our type can be integrated to SQL Server as a UDT. It has one required parameter which specifies the kind of serialization format the UDT is using. Specify Format.Native for now. We’ll elaborate on this later.
Imports System
Imports Microsoft.SqlServer.Server
Namespace MathSqlObj
<SqlUserDefinedType(Format.Native)>
Public Class Vector
using System;
using Microsoft.SqlServer.Server;
namespace MathSqlObj
{
[SqlUserDefinedType(Format.Native)]
public struct Vector : INullable
{
Fig. 2 - Vector in native format
We got our first taste of attributes in UDT programming, and just a heads-up; brace yourself for the coming attributes galore! UDT involves ample dosage of declarative programming to define some of its behaviors in SQL Server.
Accompanying the first ever adornment are four members that our struct should implement in order to qualify as a full-fledged UDT. We are going to add them one by one, as we explore the concepts of database and SQL that necessitate them.
Before you can use your UDT, you must initialize it by assigning values to its fields. This is not as straightforward as a native SQL type, because SQL does not have the concepts of constructor and property initializer which let you separate the values for each field. The only way to achieve value assignment in UDT while sticking to the standard SQL syntax is by putting all the values in one big chunk of string, like this:
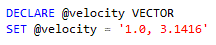
Fig. 3 – UDT SQL initialization
What’s happening behind the scenes is SQL Server calling a factory function Parse which accepts a string argument representing the input in SQL. This is responsible for splitting the string input, converting them to the desired types, and ultimately, assigning them to the fields. Of course, you’re the one who should provide the logic for that. You must also provide a delimiting character to facilitate easy splitting. The bulk of the code deals with format validations, and the more fields you have, the more tedious your work would be. If you want to showcase your RegEx prowess, this is the right place!
If you’ve read so many things about validation being one of the most important benefits of UDT, I’m sorry this article disappoints you. For me, it’s enough that you know where to put these validations. The logic is entirely up to you. So, for our UDT, let’s just assume that every input is correct.
Public Shared Function Parse(ByVal input As SqlString) As Vector
Dim inputParts As String() = input.Value.Split(","c)
Dim v As New Vector()
v.Magnitude = Double.Parse(inputParts(0))
v.Direction = Single.Parse(inputParts(1))
Return v
End Function
static public Vector Parse(SqlString input)
{
string[] inputParts = input.Value.Split(',');
Vector v = new Vector();
v.Magnitude = double.Parse(inputParts[0]);
v.Direction = float.Parse(inputParts[1]);
return v;
}
Fig. 4 - Initial implementation of Parse
The SqlString type of the parameter is mandatory. It allows the use of the SQL keyword NULL, which is actually not a string, but a state that your UDT can assume.

Fig. 5 - Assigning null
SqlString is just one of the many wrappers for .NET types located in the System.Data.SqlTypes namespace. Its main purpose is to provide the NULL state for the .NET data types; making them isomorphic to their SQL Server counterparts. For example, SqlDouble is isomorphic with the SQL Server double data type. These wrapper types can also be used in UDT, but we opted for the native types for our fields because the model requires it.
The null state we’re talking here is relevant only to SQL, and is different from the null in .NET. We’ll talk more about this when we tackle the other required members.
The UDT should be able to display itself as a distinct entity, in a certain format, using all the values of its fields. You can specify this format in the ToString function. (Yes, this is the ubiquitous member of System.Object that every type should override.) Its implementation is a no brainer. Just make sure that you adhere to good UDT design by ensuring that its return value is readily consumable by Parse, just like this:
Fig. 6 - Using ToString for initialization
This is what our vector achieves with its naïve implementation of ToString:
Public Overrides Function ToString() As String
Return String.Format("{0},{1}", Magnitude, Direction)
End Function
public override string ToString()
{
return string.Format("{0},{1}", Magnitude, Direction);
}
Fig. 7 - ToString implementation
In the initialization section, I mentioned that our UDT should be capable of assuming an unknown state called null. This is different from our common notion of null in conventional programming, which is a reference to an empty memory. The null state and its logic are implemented by the properties Null and IsNull, respectively. If not properly implemented, it’s possible that SQL Server interprets your UDT as null when, in fact, it’s not. This is because null is actually an instance of your UDT which is understood by SQL Server as unknown. SQL Server uses the static read-only property Null to get this instance. (From this point on, I will refer to the UDT null as SQL-null, while the invalid-memory reference in conventional programming as simply null.)
If both Null and Parse return a valid instance of our UDT, how would SQL Server know which is SQL-null? It simply checks the read-only property IsNull. This member is an implicit implementation of the System.Data.SqlTypes.INullable interface. This interface implementation gives our UDT the SQL-null state, just like the SqlString parameter of Parse.
There are two approaches to implementing the SQL-nullability logic of a UDT. The first approach evaluates the values of your fields, while the second uses a simple flag field. If SQL-null is desired for the first approach, the values of the fields should be something that are not acceptable in the context of the model. Let’s say you have a UDT that has a field mass. It’s universally accepted that mass is never negative. In the UDT, a negative value for this field can convey a SQL-null:
Private _mass As Double
Public Shared ReadOnly Property Null() As SimpleUdt
Get
Dim u As New SimpleUdt()
u._mass = -1
Return u
End Get
End Property
Public ReadOnly Property IsNull() As Boolean Implements INullable.IsNull
Get
Return (_mass < 0)
End Get
End Property
double _mass;
static public SimpleUdt Null
{
get
{
SimpleUdt u = new SimpleUdt();
u._mass = -1.0
return v;
}
}
public bool IsNull
{
get
{
return (_mass < 0.0;)
}
}
Fig. 8 - SQL-nullability using member values
Personally, I prefer the second approach because it’s succinct and promotes self-documenting codes. These could also be the reasons why it is the default implementation in Visual Studio. In our UDT, that is a simple flag before we return the value in the Null property. Below are the SQL-nullability and null implementations of our UDT.
Private _isNull As Boolean
Public Shared ReadOnly Property Null() As Vector
Get
Dim v As New Vector()
v._isNull = True
Return v
End Get
End Property
Public ReadOnly Property IsNull() As Boolean Implements INullable.IsNull
Get
Return _isNull
End Get
End Property
bool _isNull;
static public Vector Null
{
get
{
Vector v = new Vector();
v._isNull = true;
return v;
}
}
public bool IsNull
{
get { return _isNull; }
}
The UDT object is different from your usual .NET object because it is saved and retrieved directly in the disk. You don’t have any other layers sitting between your UDT and the disk which do the saving and retrieval for you. These processes of saving and retrieving objects are called binary serialization and binary deserialization, respectively. The rest of the text may refer to both as simply serialization.
Implementation of serialization in UDT is implicit if the types of your fields are readily serializable. Such types are said to be blittable in programming parlance. They don’t require special handling in .NET because their representation is the same as that in unmanaged code. No additional code is required, and all we have to do is tell SQL Server that it can handle the serialization. We already did this in Figure 2. Our UDT satisfies all the conditions for native serialization, and hence it’s now usable. It should have the following members by now:
Fig. 10 – Vector UDT basic members
If there is at least one field that is not blittable, then we must specify Format.UserDefined as the serialization format and implement the serialization manually. We do the latter by providing the implementation of the Microsoft.SqlServer.Server.IBinarySerialize interface. This interface has two members, aptly named Read and Write. You use the BinaryWriter argument to persist the values of your fields, while the BinaryReader to retrieve and assign them back. The order of your writing should be the same as your reading. The implementation ranges from the most trivial read/write to the uber-complex byte manipulations. The latter is beyond the scope of this article.
Suppose we decided to have the highest accuracy for our magnitude. This is the right job for System.Decimal, a type that SQL Server doesn’t know how to serialize. The manual binary serialization is still straightforward:
Private _magnitude As Decimal
Private _direction As Single
Private _isNull As Boolean
Public Sub Write(ByVal w As System.IO.BinaryWriter) _
Implements IBinarySerialize.Write
w.Write(IsNull)
If Not IsNull Then
w.Write(Magnitude)
w.Write(Direction)
End If
End Sub
Public Sub Read(ByVal r As System.IO.BinaryReader) _
Implements IBinarySerialize.Read
_isNull = r.ReadBoolean()
If Not IsNull Then
Magnitude = r.ReadDecimal()
Direction = r.ReadSingle()
End If
End Sub
decimal _magnitude;
float _direction;
bool _isNull;
void IBinarySerialize.Write(System.IO.BinaryWriter w)
{
w.Write(IsNull);
if (!IsNull)
{
w.Write(Magnitude);
w.Write(Direction);
}
}
void IBinarySerialize.Read(System.IO.BinaryReader r)
{
_isNull = r.ReadBoolean();
if (!IsNull)
{
Magnitude = r.ReadDecimal();
Direction = r.ReadSingle();
}
}
Fig. 11 - Simple IBinarySerialize implementation
Our vector is now officially a UDT. We are going to copy the assembly to SQL Server and extract the UDT from it. This process of creating objects in SQL Server is known as cataloguing, because incidentally, you are making your objects visible in the catalogue views of SQL Server. You should build the class library, and copy the assembly to a desired location. If you haven’t enabled SQL-CLR Integration, you may execute these statements:
Fig. 12 - Enabling SQL-CLR
The first step in cataloguing your UDT is to copy the assembly to the database using the CREATE ASSEMBLY command. You specify the path of your assembly and the name that should appear in the database. Your database and the location of your assembly may differ from mine, so change them accordingly. In the commands below, we just use the assembly name as its logical name inside the database:
Fig. 13 - Cataloguing the assembly
Cataloguing our UDT is achieved by the CREATE TYPE command. The fully qualified name of your type, this time, has the format <name of assembly in the database>.[<namespace in the original assembly>.<type name in the original assembly>]. We enclose the namespace and the type with “[]” because currently, SQL-CLR does not support namespaces.
Fig. 14 - Cataloguing the UDT
You may verify our assembly and UDT by querying their corresponding catalogue views:
Fig. 15 - Verifying assembly and UDT
The ALTER ASSEMBLY command is handy when you make modifications in the functions and some parameters in the attributes of the UDT. This saves you one step because you’re not required to re-catalogue your UDT anymore. The syntax is very similar to its CREATE counterpart.
Fig. 16 - The ALTER ASSEMBLY command
You may not use the ALTER ASSEMBLY command if you renamed, added, removed members, or made changes that affect the serialization of the UDT. You must re-catalogue everything. This means dropping all the objects in the assembly dependency tree and then repeating the previous steps. You will be using the commands below for most of the subsequent modifications to our UDT:
Fig. 17 - Re-cataloguing commands
The commands I just presented are the most compact variants that handle our needs. Consult the Microsoft documentation for comprehensive discussions of them.
It’s time to see our UDT in action. We will examine what’s going on inside it as we execute some of the most common SQL statements. We might discover new things and learn more about creating UDT as we go along. Bear in mind though that this is a happy test; we must provide the correct input at all times, otherwise exceptions would be thrown.
Let’s kick-start by declaring a variable of our UDT and then displaying it. As expected, the following statements prints “NULL” because we haven’t initialized it.
Fig. 18 - Simple UDT usage
If we initialize it before selecting it, we get something gibberish:
Fig. 19 - Hexadecimal display of initialized UDT
This weird series of characters is actually the hexadecimal representation of a vector. Somewhere in that hexadecimal is your magnitude and direction. In order to get a meaningful display, we need to call the ToString function:
Fig. 20 - ToString display of initialized UDT
In my opinion, the integration to T-SQL would have been much more seamless if SQL Server calls ToString underneath if we omit ToString. This behavior would have been consistent with the implementation of the initialization with Parse.
Before we proceed, be aware that the members of your UDT are case sensitive, and the following statements illustrate that:
Fig. 21 - UDT member case-sensitivity
Displaying properties does not require a call to ToString unless the type is a UDT. Non-UDT properties can be mapped directly to some SQL native types so SQL Server has no problem displaying them.
Fig. 22 - Direct call to scalar property
To prove that our UDT adheres to good design, Parse should be able to consume ToString without a problem:
Fig. 23 - Parsing with ToString
And we can now create a table with a Vector column, and insert or update rows:
Fig. 24 - Using UDT in a column
The ubiquitous equals "=" operator in SQL is not compatible with UDT, by default, and using it results in an error.
Fig. 25 - Equality operator call error
Being a .NET developer, the first thing that would come to your mind is operator overloading. Unfortunately, operator overloading is not yet supported in SQL-CLR. The good news is turning on this equality operator support in UDT is very simple. We’ll just tell SQL Server to use the persisted binaries of the fields when comparing. We do this by setting the IsByteOrdered property of the SqlUserDefinedTypeAttribute to true. Be aware that if your UDT is a class, there will be additional work involved. We’ll discuss this later.
The IsByteOrdered setting means SQL Server comparing the magnitude followed by the direction and then nullability. This suits our needs since it already conforms to the semantics of vector equality.
<SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native, _
IsByteOrdered:=True)> _
Public Structure Vector
Implements INullable
Private _magnitude As Double
Private _direction As Single
Private _isNull As Boolean
[SqlUserDefinedType(Format.Native, IsByteOrdered=true)]
public struct Vector : INullable
{
double _magnitude;
float _direction;
bool _isNull;
Fig. 26 - IsByteOrdered adornment
The new adornment is a significant change in the UDT, so a simple alteration is not allowed. You must re-catalogue everything. After the re-catalogue, executing the last command should work just fine.
Fig. 27 - IsByteOrdered at work
The negated equal operator "!=" is also implemented as a logical consequence:
Fig. 28 - Negation operator
And even the rest of the equality operators, even though they don’t make any sense in the context of Vector:
Fig. 29 - Other equality operators
If SQL Server can compare our vectors, definitely it can sort them too. Once again, sorting the Vector does not make sense, but here it is:
Fig. 30 - Sorting vectors
Everything is set for the other roles the UDT can assume at this point, like primary key, foreign key, and indexed key. You can indeed create these constraints with UDT, but it doesn’t mean you should. Besides being a blatant violation of fundamental relational principles, UDT was not built for this purpose, and the performance penalty for such an implementation can be very severe. Here’s a table with a UDT as a primary key:
Fig. 31 - UDT as PK
Do you notice something odd about our implementation of Parse in Figure 4? The code always returns non-SQL-null, but if we assign null to our UDT, it behaves accordingly.
Fig. 32 - Using the NULL keyword bypasses Parse
We can infer that maybe SQL Server is bypassing Parse when NULL is assigned as the value. It could be because calling Parse explicitly is another story (calling static functions of UDT in T-SQL uses the :: scope qualifier).
Fig. 33 - Explicit call to Parse
The only logical conclusion we can arrive at is that SQL Server somehow has its own way of tagging the memory occupied by our UDT as SQL-null whenever we use the keyword NULL instead of calling Parse. It’s talking direct binaries this time instead of string. The error message tells us that we cannot use the value of the argument because it is SQL-null. The exception is thrown the moment we attempt to split the input.
Explicit call to Parse is not the recommended way of assigning values to a UDT. I just showed you that in order to make a point. If you still want to play safe, you can avoid this exception by making sure that you are not splitting a SQL-null argument, as what the next block of code shows:
Public Shared Function Parse(ByVal input As SqlString) As Vector
If input.IsNull Then
Return Null
End If
Dim inputParts As String() = input.Value.Split(","c)
Dim v As New Vector()
v.Magnitude = Double.Parse(inputParts(0))
v.Direction = Single.Parse(inputParts(1))
Return v
End Function
static public Vector Parse(SqlString input)
{
if (input.IsNull)
return Null;
string[] inputParts = input.Value.Split(',');
Vector v = new Vector();
v.Magnitude = double.Parse(inputParts[0]);
v.Direction = float.Parse(inputParts[1]);
return v;
}
Fig. 34 - Explicit returning of Null in Parse
We see that the last statements work just fine this time:
Fig. 35 - Explicit call on a Parse with explicit null return
This unusual overloading is required to boost performance. Bypassing Parse means SQL Server can implement the native way of handling SQL-nulls just like how it does on non-UDT types. This also means that we can actually assign non-string literals to initialize a UDT:
Fig. 36 - Direct binary assignment
This can be scary. We now have something similar to the dreaded “SQL-injection” attack. In this case, it’s a direct binary deserialization attack. Garbage can be entered as long as its binary is converted to the UDT type. You’re lucky if an error results, or if it results to SQL-null; otherwise, it can wreck havoc to your program. The next set of statements show that inserting 12-bytes (8 bytes for the magnitude, 4 bytes for the direction) binary avoids SQL-null and NAN (Not A Number) while still ensures garbage results. Note that the length of the binary is the total length of our fields: double=8 + float=4 + Boolean=1 = 13.
Fig. 37 - Assignment using arbitrary string literal
SQL Server provides a safeguard from this circumvention through a function which is called whenever an external binary deserialization is performed. You specify this in the ValidationMethodName property of the SqlUserDefinedTypeAttribute. This function should be parameter-less, and return a Boolean indicating if the input is valid or not. So, for the sake of illustration, we simplify the model by accepting only a positive magnitude and a direction between 0 and 2PI. Our validation function becomes:
<SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native _
, IsByteOrdered:=True, ValidationMethodName:="ValidateInput")> _
Public Structure Vector
Implements INullable
Private Function ValidateInput() As Boolean
Dim minDirection As Single = 0.0F
Dim maxDirection As Single = CSng((2 * Math.PI))
Return (Magnitude >= 0) AndAlso _
(Direction >= minDirection AndAlso Direction <= maxDirection)
End Function
[SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native
,IsByteOrdered=true, ValidationMethodName="ValidateInput")]
public struct Vector : INullable
{
private bool ValidateInput()
{
float minDirection = 0f;
float maxDirection = (float)(2D * Math.PI);
return (Magnitude >= 0D) &&
(Direction >= minDirection && Direction <= maxDirection);
}
Fig. 38 - Validation function
The real vector does not have these restrictions. A negative magnitude means that the vector is actually pointing to the opposite direction. Our model forces the user to reverse the direction instead of supplying a negative magnitude. A direction less than 0 or greater than 2PI is also allowed, but can be converted to the equivalent value between 0 and 2PI. We’ll provide the appropriate helper function for this later. With the validation function in place, those unreasonable values derived from arbitrary string literals are caught this time:
Fig. 39 – Validation function firing
The validation can also be applied in Parse, but we need to transfer the logic to another static function. The validation function for binary deserialization merely delegates the task to the new static function as shown:
<SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native _
, IsByteOrdered:=True, ValidationMethodName:="ValidateInput")> _
Public Structure Vector
Implements INullable
Private Function ValidateInput() As Boolean
Return Vector.Validate(Me)
End Function
Private Shared Function Validate(ByVal v As Vector) As Boolean
Dim minDirection As Single = 0.0F
Dim maxDirection As Single = CSng((2 * Math.PI))
Return (v.Magnitude >= 0) AndAlso _
(v.Direction >= minDirection AndAlso v.Direction <= maxDirection)
End Function
Public Shared Function Parse(ByVal input As SqlString) As Vector
If input.IsNull Then Return Null
Dim inputParts As String() = input.Value.Split(","c)
Dim v As New Vector()
v.Magnitude = Double.Parse(inputParts(0))
v.Direction = Single.Parse(inputParts(1))
If Not Validate(v) Then
Throw New ArgumentException("Magnitude must be positive " & _
"and direction must be between 0 and 2PI.")
Return v
End Function
[SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native
, IsByteOrdered = true, ValidationMethodName = "ValidateInput")]
public struct Vector : INullable
{
private bool ValidateInput()
{
return Vector.Validate(this);
}
private static bool Validate(Vector v)
{
float minDirection = 0f;
float maxDirection = (float)(2D * Math.PI);
return (v.Magnitude >= 0D) &&
(v.Direction >= minDirection && v.Direction <= maxDirection);
}
static public Vector Parse(SqlString input)
{
if (input.IsNull)
return Null;
string[] inputParts = input.Value.Split(',');
Vector v = new Vector();
v.Magnitude = double.Parse(inputParts[0]);
v.Direction = float.Parse(inputParts[1]);
if (!Validate(v))
throw new ArgumentException("Magnitude must be positive " +
" and direction must be between 0 and 2PI.");
return v;
}
Fig. 40 - Applying validation in Parse
With that code, valid literals are also taken care of:
Fig. 41 - Business-invalid literals
In production, malicious binary deserialization from arbitrary literals is virtually impossible unless your system is already vulnerable to other conventional means of attack, like SQL-injection. Preventing attacks like this is the primary responsibility of the front-end applications and the security infrastructure. But, in deference to Murphy's Law, just make sure you have the validation function in your UDT.
We have seen our UDT in an Update statement when we discussed about UDT initialization and value assignment. It was more of “replacing” since we simply create another instance of our UDT and assign it to the column. It needlessly updates all the fields, and this is not what we always want. Sometimes, we want to update just one property. The type of the properties Magnitude and Direction map to SQL types double and float respectively. This makes them readily updateable in SQL. (See the Microsoft documentation for a full list of CLR to SQL type mappings.)
Fig. 42 - Direct update on a property
And for some unknown purposes, string literals of valid inputs is also possible. Look!
Fig. 43 - String literals as property input
Although, it produces errors with invalid literals like ‘Hello there’, I still find this very unnecessary. In the previous version of this article, I express my hope that this feature be removed from SQL Server 2008. Unfortunately, it's still there.
SQL Server does not allow updating of two columns in one UPDATE statement. Attempting so returns an error:
Fig. 44 - No update for two columns
This must be due to the internal mechanics of the database engine, or some other relational principles, but I could care less. If there is a need to change two or more fields at the same time, it could be an indicator for the presence of a function. This function leverages on encapsulation by hiding the intricacies of updating the fields while making our UDT self-documenting. We can apply this to represent some common operations of a vector. Let’s augment our vector with these functions, starting with scalar multiplication. Scalar multiplication is nothing more than increasing and decreasing the magnitude by a certain factor. We can represent this with a less academic name Scale. If the factor is negative, that means the direction is shifted by 180 degrees or 2PI.
<SqlUserDefinedType(Format.Native, ValidationMethodName:="ValidateInput" _
,IsByteOrdered:="True"> _
Public Structure Vector
Implements INullable
Public Sub Scale(ByVal factor As Double)
If factor < 0 Then
Dim dir As Double = Direction
If dir > Math.PI Then
dir -= Math.PI
Else
dir += Math.PI
End If
Direction = CSng(dir)
factor *= -1
End If
Magnitude *= factor
End Sub
[SqlUserDefinedType(Format.Native, ValidationMethodName = "ValidateInput"
,IsByteOrdered = true)]
public struct Vector : INullable
{
[SqlMethod(IsMutator=true)]
public void Scale(double factor)
{
if (factor < 0)
{
double direction = Direction;
if (direction > Math.PI)
direction -= Math.PI;
else
direction += Math.PI;
Direction = (float)direction;
factor *= -1;
}
Magnitude *= factor;
}
Fig. 45 - Scale function
If you execute this however, you would get an error:
Fig. 46 - Error from updating a non-mutator function
What happened was that SQL Server could not recognize the member as a mutator. In programming parlance, a mutator is a function that alters the state of your object. Alter in the sense that the value of at least one of your fields is changed. In a language that does not have a construct for property, mutator is synonymous to a setter function. Therefore, it makes perfect sense that SQL Server considers a property as mutator, by default. You can change this setting through the IsMutator property of SqlMethodAttribute. SQL-CLR goes even beyond the default because IsMutator seems to have no effect on the property. You should try the code below and see for yourself.
Public Property Magnitude() As Double
Get
Return _magnitude
End Get
<SqlMethod(IsMutator:=False)> _
Set(ByVal value As Double)
_magnitude = value
End Set
End Property
public double Magnitude
{
get { return _magnitude; }
[SqlMethod(IsMutator=false)]
set
{
_magnitude = value;
}
}
Fig. 47 - IsMutator setting for property has no effect
Our Scale operator, being a function, does not enjoy the privilege that Magnitude does. We need to explicitly set the flag in the attribute:
<SqlMethod(IsMustator:=True)>
Public Sub Scale(ByVal factor As Double)
[SqlMethod(IsMutator=true)]
public double Scale(double factor)
{
Fig. 48 - Scale function as mutator
In a good OOP design, a mutator is usually a public instance function that returns void. Even your property set function is converted to such a function. SQL Server makes sure you adhere to this by restricting mutator calls to UPDATE and SET statements only. If you don’t tag a void function as mutator, you are authorizing SQL Server to call that function in SELECT or PRINT statements. Error results because SELECT and PRINT expect argument values which should have been returned by the UDT function.
In the other hand, a non-mutator or accessor returns a value to the caller. SQL Server restricts accessor calls to SELECT and PRINT statements. It’s perfectly legal to mark an accessor as mutator, but in so doing, you render it useless. SQL Server cannot use the return value because the attribute precludes SELECT and PRINT. You can use UPDATE and SET, but they’re worthless because they do nothing to the return value of the function. The following table summarizes the SQL statement's dependency to the IsMutator property:
Fig. 49 - SQL statement dependency to IsMutator
We add an accessor to return the vector which points to the opposite direction. You may omit the adornment because the default is already false.
<SqlMethod(IsMutator:=False)> _
Public Function GetReversed() As Vector
Dim reversed As Vector = Me
reversed.Scale(-1)
Return reversed
End Function
[SqlMethod(IsMutator=false)]
public Vector GetReversed()
{
Vector reversed = this;
reversed.Scale(-1);
return reversed;
}
Fig. 50 - GetReversed accessor function
After flagging our Scale function as a mutator, the last SQL statements using it run just fine:
Fig. 51 - Scale function at work
And so does the new accessor:
Fig. 52 - GetReversed function at work
We add the other vector operations of our model as static functions. This gives us the ability to use them in both displaying and updating our UDT. If we opted for an instance implementation instead, it would require us to create an equivalent static function if we only want to display the result. And because SQL-CLR does not support function overloading, we would end up with a function with a different name - not elegant at all! We added a helper class that converts all directions less than 0 or greater than 2PI, because it’s possible that intermediate operators can yield values beyond that range.
Public Shared Function Add(ByVal lhs As Vector, ByVal rhs As Vector) As Vector
Dim xOfMagnitude As Double = (Math.Cos(CDbl(lhs.Direction)) * lhs.Magnitude) _
+ (Math.Cos(CDbl(rhs.Direction)) * rhs.Magnitude)
Dim yOfMagnitude As Double = (Math.Sin(CDbl(lhs.Direction)) * lhs.Magnitude) _
+ (Math.Sin(CDbl(rhs.Direction)) * rhs.Magnitude)
Dim resultant As New Vector()
resultant.Magnitude = Math.Sqrt((xOfMagnitude * xOfMagnitude) _
+ (yOfMagnitude * yOfMagnitude))
resultant.Direction = ToFirstRevPositive( _
CSng(Math.Atan2(yOfMagnitude, xOfMagnitude)))
Return resultant
End Function
Public Shared Function Subtract(ByVal lhs As Vector, ByVal rhs As Vector) As Vector
rhs.Scale(-1)
Return Add(lhs, rhs)
End Function
Private Shared Function ToFirstRevPositive(ByVal angleInRadian As Single) As Single
Dim negative As Boolean = angleInRadian < 0.0F
Dim oneRev As Single = CSng((2 * Math.PI))
If negative Then angleInRadian *= (-1.0F)
Dim angleFirstRev As Single = angleInRadian Mod oneRev
Dim angleFirstRevPositive As Single = If(negative, _
oneRev - angleFirstRev, angleFirstRev)
Return angleFirstRevPositive
End Function
public static Vector Add(Vector lhs, Vector rhs)
{
double xOfMagnitude = (Math.Cos((double)lhs.Direction) * lhs.Magnitude)
+ (Math.Cos((double)rhs.Direction) * rhs.Magnitude);
double yOfMagnitude = (Math.Sin((double)lhs.Direction) * lhs.Magnitude)
+ (Math.Sin((double)rhs.Direction) * rhs.Magnitude);
Vector resultant = new Vector();
resultant.Magnitude = Math.Sqrt((xOfMagnitude * xOfMagnitude)
+ (yOfMagnitude * yOfMagnitude));
resultant.Direction = ToFirstRevPositive(
(float)Math.Atan2(yOfMagnitude, xOfMagnitude));
return resultant;
}
public static Vector Subtract(Vector lhs, Vector rhs)
{
rhs.Scale(-1.0D);
return Add(lhs, rhs);
}
static float ToFirstRevPositive(float angleInRadian)
{
bool negative = angleInRadian < 0f;
float oneRev = (float)(2.0 * Math.PI);
if (negative)
angleInRadian *= (-1f);
float angleFirstRev = angleInRadian % oneRev;
float angleFirstRevPositive = negative ?
oneRev - angleFirstRev : angleFirstRev;
return angleFirstRevPositive;
}
Fig. 53 - Common vector operations with a helper function
We test these operators on two vectors of equal magnitudes: one is 45 degrees while the other is 135. The scope qualifier for the static function is :: which is first shown in Figure 34. Note again that our vector UDT accepts only angles expressed in radians, and that the precision of our answers is dependent on the precision of our inputs.
Fig. 54 - Common vector operations at work
Function overloading and operator overloading are still not part of SQL Server 2008 but they would be a nice addition someday. Operator overloading is a must for mathematical entities like vectors where the overridable CLR operators already have fixed and well-defined semantics. With the current shortcomings of UDT, it’s still impossible to write a 100% SQL-agnostic .NET struct or class. More often than not, UDTs are not mere ports from an existing library. It’s primarily created with SQL Server in mind.
Before we end this section, let me just also point out that SQL Server does not support out and ref parameters. Your codes compile but calling the function in SQL returns this vague message:
Fig. 55 - Error message for out and ref parameters
Our assignment statements for the last test are not efficient. We initialize the direction with 0, only to change it with another value later on. We did this because we wanted to use the PI() variable, but since the default UDT initialization accepts only string literals, we are forced to assign a dummy value for the direction. We can rectify this by another factory function, this time with the properly typed parameters. It’s just natural to initialize the fields using their own types rather than strings, which is very prone to error. From now on, we’ll be using this function a lot more often:
Public Shared Function CreateVector(ByVal magnitude As Double _
, ByVal direction As Single) As Vector
Dim v As New Vector()
v.Magnitude = magnitude
v.Direction = direction
Return v
End Function
static public Vector CreateVector(double magnitude, float direction)
{
Vector v = new Vector();
v.Magnitude = magnitude;
v.Direction = direction;
return v;
}
Fig. 56 - A factory much better than Parse
This new factory function even makes the previous SQL statements a tad shorter:
Fig. 57 - Using a factory to initialize vector
At this point, we’ve seen all the members of the UDT in action except IsNull. We already know that SQL Server uses this internally to determine if the instance is a SQL-null after deserialization. If this is the case, then using it should be straightforward in SQL, right? Wrong. Take a look at these statements:
Fig. 58 - Unexpected default behavior of IsNull
Examining the properties of our UDT explains why the delete did not happen as expected.
Fig. 59 - Calling properties of SQL-null UDT
This quirk is due to the SQL Server default behavior of bypassing calls to members of a SQL-null UDT. It is a performance-enhancing technique. SQL Server can save processing power since it does not have to deserialize the fields of the UDT anymore. It peeks into the memory just long enough to find out whether or not the UDT is tagged as SQL-null.
In a SQL-null UDT, it’s perfectly logical to get null from the other members except for IsNull. IsNull returning a SQL-null is misleading. An uninitiated SQL developer could use this property as a predicate in a WHERE clause, resulting in a subtle bug. To avoid this, you can tell SQL Server to call a member of a SQL-null UDT by setting the property InvokeIfReceiverIsNull of SqlMethodAttribute to true. This tells SQL Server that if the UDT is SQL-null, it still has to deserialize it so that a call to the member is possible.
Public ReadOnly Property IsNull() As Boolean Implements INullable.IsNull
<SqlMethod(InvokeIfReceiverIsNull:=True)> _
Get
Return _isNull
End Get
End Property
public bool IsNull
{
[SqlMethod(InvokeIfReceiverIsNull=true)]
get { return _isNull; }
}
Fig. 60 - InvokeIfReceiverIsNull property
This time you get what you wanted with your DELETE:
Fig. 61 - Expected behavior of IsNull
Be aware that this incurs unnecessary processing. Microsoft recommends you stick to the existing SQL way of testing nullability using the IS NULL predicate operator. This also gives you the correct result minus the deserialization of UDT fields, thus offering a significant performance boost.
I conducted an informal test on the performance between IsNull and the IS NULL construct on a 10M-row table with 33% SQL-nulls. The script and a sample output are shown below:
Fig. 62 - IsNull vs. IS NULL script and output
There were so many processes in my machine that could affect the execution of the script, so I made 10 iterations in order to arrive to a much conclusive result. Of course, the more iterations, the more conclusive the result would be, but I didn’t have the time and resources to set a clean testing environment. Now you know why I called them “informal” tests.
The ten iterations yielded consistent values of IS NULL being 6 times faster than its UDT counterpart, as shown in the following graphs:
Fig. 63 - IS NULL vs. IsNull results
The adverse effect of IsNull is probably negligible on a small number of rows, but it’s always safe to shy away from it on set-based operations because you never know when and how fast your table grows. For non-set-based operations like a condition in your IF statement, you’re pretty much safe with it.
While SQL-null is still fresh in our minds, let’s tackle another behavior that has something to do with it. This time it’s not the UDT that is SQL-null, but the argument passed to its function. Like the case of IsNull, SQL Server treatment of SQL-null arguments takes both performance and semantics into consideration. This behavior is controlled by the OnNullCall property of the SqlMethodAttribute. Of course, the purpose of this property is fully realized only if the parameters are SQL-nullable.
Leaving OnCallNull to its default value of true tells SQL Server to call the function even if at least one of the arguments is null. This may seem absurd because it implies that performance is not the primary motivation for this property. We’ll find out the rationale behind this before we end this section.
Let’s start our exploration of this new property by adding a mutator function AddVector with OnNullCall set to false:
<SqlMethod(IsMutator:=True _
, OnNullCall:=False)> _
Public Sub AddVector(ByVal v As Vector)
Dim resultant As Vector = Me
resultant = Vector.Add(Me, v)
Magnitude = resultant.Magnitude
Direction = resultant.Direction
End Sub
[SqlMethod(IsMutator=true
,OnNullCall=false)]
public void AddVector(Vector v)
{
this = Vector.Add(this, v);
}
Fig. 64 - OnNullCall adornment
If we pass a null argument to this function, we get a vague error message:
Fig. 65 - Error from a mutator supplied with a SQL-null argument
We know that, generally, SQL operations involving a SQL-null return SQL-null. SQL Server assumes that by tagging your function as a mutator, you’re going to use the SQL-null argument to an operation involving your fields. In theory, this in turn can render your UDT SQL-null or your fields in an inconsistent state. This is what the previous message is all about.
SQL Server prevents the unintentional rendering of your UDT to SQL-null by restricting OnNullCall only to true in the case of mutators. Because the values in your fields are vital, SQL Server wants you to take the appropriate actions instead of just rendering your UDT SQL-null right away. You have the options of exiting the function or throwing an exception. If ever you want to render your UDT SQL-null, you may do so by setting the nullability flag field to true. SQL Server imposes a rule that setting a data to null should be done through explicit null assignment, as shown in Figure 5, and not as a mere effect of an operation to which the UDT is an operand. We fix our codes by setting OnNullCall to true, and exit the function if the argument is SQL-null:
<SqlMethod(IsMutator:=True, OnNullCall:=True)> _
Public Sub AddVector(ByVal v As Vector)
If v.IsNull Then
Return
End If
Dim resultant As Vector = Me
resultant = Vector.Add(Me, v)
Magnitude = resultant.Magnitude
Direction = resultant.Direction
End Sub
[SqlMethod(IsMutator = true, OnNullCall = true)]
public void AddVector(Vector v)
{
if (v.IsNull)
return;
this = Vector.Add(this, v);
}
Fig. 66 - Handling SQL-null arguments
The previous statements should succeed by now:
Fig. 67 - Accessor returning an instance when a SQL-null argument is supplied
The values of the fields might be valid for a particular operation even if SQL-nullability is ignored. This is the case of our vector UDT where the SQL-null values of zero magnitude is a special kind of vector – the zero vector. The zero vector is also an additive identity which means that adding that to a non-zero vector simply yields the same non-zero vector. The addition did happen, but we are given the impression otherwise, because the result is the same as the non-zero vector operand. You can confirm this by running the same statement, but this time on a function that does not return if the argument is SQL-null. We can go even further by changing the values of the fields in the Null property’s get function.
<SqlMethod(IsMutator:=True _
, OnNullCall:=True)> _
Public Sub AddVector(ByVal v As Vector)
Dim resultant As Vector = Me
resultant = Vector.Add(Me, v)
Magnitude = resultant.Magnitude
Direction = resultant.Direction
End Sub
Public Shared ReadOnly Property Null() As Vector
Get
Dim v As New Vector()
v._isNull = True
v.Magnitude = 15
v.Direction = CSng(Math.PI)
Return v
End Get
End Property
[SqlMethod(IsMutator=true
, OnNullCall=true)]
public void AddVector(Vector v)
{
this = Vector.Add(this, v);
}
static public Vector Null
{
get
{
Vector v = new Vector();
v._isNull = true;
v.Magnitude = 15.0;
v.Direction = (float)Math.PI;
return v;
}
}
Fig. 68 - Changing the default values of fields
The previous statements this time will yield a different result, which clearly shows that the addition does happen:
Fig. 69- Default values affecting addition
During development, you must double check all your mutators to see if all the null arguments are explicitly handled. Ignoring them does not return an error, and this might lead you to believing that SQL Server does the job of returning the current instance for you. The operation is actually performed using the SQL-null arguments, and it succeeded because .NET has no concept of SQL-null; the SQL-null object is still a valid .NET object!
Accessor is a different story. SQL Server allows setting of OnNullCall to false on it because your UDT is in no way affected by the operation. And since almost all operations involving SQL-null yield SQL-null, SQL Server can safely return the SQL-null right away. If ever there are special cases, you are still allowed to set OnNullCall to true and handle the SQL-null argument accordingly.
I conducted another 10-iteration test to find out how much performance benefit you can get from setting OnNullCall to false. For this test, I made two variants of our vector UDT, each having an accessor GetScaled with a SQL-nullable parameter. The implementation of GetScaled for the variant that allows calling of this method is shown below:
<SqlMethod(OnNullCall:=True)> _
Public Function GetScaled(ByVal factor As SqlDouble) As Vector
If factor.IsNull Then _
Return Vector.Null
Dim v As New Vector()
v = Me
v.Scale(factor.Value)
Return v
End Function
[SqlMethod(OnNullCall = true)]
public Vector GetScaled(SqlDouble factor)
{
if (factor.IsNull)
return Vector.Null;
Vector v = new Vector();
v = this;
v.Scale(factor.Value);
return v;
}
Fig. 70 - An accessor version of Scaled which is called on SQL-null arguments
The test simulated insertion to two dummy tables with the SQL-null return values of GetScaled from the two variants. The following shows the script and a sample result:
Fig. 71 - Script for testing OnNullCall
There might be some processes in my machine that caused an unusual spike in one of the iterations, but it is still clear that there is indeed a performance benefit with bypassing the function call. My machine yielded a 21% performance advantage as shown here:
Fig. 72 - OnNullCall test results
The OnNullCall setting precedes other validation checks that SQL Server does to the argument of a function. If the parameter of your accessor is a non-SQL-nullable, SQL Server does not return an error even if you supply a null value to it, because the check is already suppressed by the OnNullCall setting. To illustrate this, let’s create another accessor variant of our Scale, but unlike Figure 70, we retain the non-SQL-nullable parameter which is central for this discussion.
Public Function ScaleAccessor(ByVal factor As Double) As Vector
Dim scaled As Vector = Me
scaled.Scale(factor)
Return scaled
End Function
public Vector ScaleAccessor(double factor)
{
Vector scaled = this;
scaled.Scale(factor);
return scaled;
}
Fig. 73 - OnNullCall set to true for function with non-SQL-nullable parameter
As I’ve said earlier, setting OnNullCall to true on this function does not make sense because you would never be allowed to supply a SQL-null. SQL-Server does not know how to convert the argument of the function to SQL-null, and you’ll get an error similar to this:
Fig. 74 - Error from calling an accessor with a non-SQL-nullable parameter
Don’t let the message fool you. Converting our parameter to out or ref doesn’t work either as shown in Figure 55. To avoid this error, you set OnNullCall to false. SQL Server never bothers to check if the parameter is SQL-nullable. There’s no point since it will not call the function anymore.
It’s clear at this point that OnNullCall is very much dependent on IsMutator. We’ll end this discussion by another table that summarizes this dependency. The table shows why SQL Server differs when it comes to the default OnNullCall setting, having performance as an important consideration notwithstanding. We can surmise that it’s just a natural consequence of SQL Server adherence to fundamental database concepts and its regard to the safety of your data.
Fig. 75 - OnNullCall dependency to IsMutator
Figure 26 shows how easy it is to make our UDT index-ready through a simple flag in the UDT attribute. It’s not even our intention then, but just a mere side-effect of telling SQL Server how to compare two UDTs. In production however, you will find yourself indexing functions (property-gets are also functions) much more often than UDT, because generally, they are scalar. But unlike scalar outside a UDT, a scalar function is not index-ready by default, as shown here:
Fig. 76 - Scalar function is not index-ready
The message says that SQL Server requires the function should be deterministic. A function is deterministic if there is only one possible output for a particular input. In other words, no two inputs produce the same output. For example, the equation x+1 is deterministic because it produces a unique value for every value of x. On the other hand, x^2 (x squared) is not deterministic because it can produce the same output from two numbers; e.g. +2 and -2. In mathematics, a deterministic equation is actually called a function. Do not confuse this with how we use the term in the context of programming.
SQL Server cannot determine whether or not a function is deterministic. It’s your job to tell it by using the property IsDeterministic of the SqlMethodAttribute. It’s obvious that our candidate property qualifies since it does nothing but expose our field.
Public Property Magnitude() As Double
<SqlMethod(IsDeterministic:=True)> _
Get
Return _double
End Get
public double Magnitude
{
[SqlMethod(IsDeterministic=true)]
get
{
return _double;
}
Fig. 77 - A deterministic property
SQL Server can now grant our request:
Fig. 78 - UDT column as index key
To see how our index works, we perform two queries, with the first one leveraging on the clustered index. The execution plan shows that we get a significant performance boost in the first query because SQL Server doesn’t have to perform the sort anymore.
Fig. 79 - Indexed property at work
Before we proceed, let’s take a brief look at the statements for creating an index. The statement says that creating an index from a UDT property entails saving the value for that property on a derived column. This is achieved by the keyword PERSISTED, which also implies that the column is intended to be indexed.
You can still enhance the performance of a property- or function- based index by telling SQL Server that there is no floating point operation involved in yielding the return value. You should assure SQL Server that the result is precise. Unfortunately, none of our properties guarantee exact precision. If magnitude were precise, we could have set the IsPrecise property of the SqlMethodAttribute attribute like this:
Public Property Magnitude() As Double
<SqlMethod(IsDeterministic:=True, IsPrecise:=True)> _
Get
Return _double
End Get
public double Magnitude
{
[SqlMethod(IsDeterministic=true, IsPrecise=true)]
get
{
return _double;
}
Fig. 80 - A property flagged as precise
When dealing with floating point values, one would later find out that the ubiquitous equals “=” operator may be rendered unreliable. This is because the chance of two values to be exactly the same is very slim. The number of significant figures can vary from one input to another, and a certain degree of imprecision is introduced in the intermediate computations. Our UDT is very susceptible to this anomaly because all of the fields used in comparison are floating point types. The next set of statements simulates an equality test anomaly between two vectors conceived to be equal but proven otherwise by the difference in input presentation. The second vector accepts an approximate value for the direction, which leads to a very minute yet significant difference.
Fig. 81 - Different input presentation causes equality anomaly
If we have reasonable number of significant figures, we can tolerate a certain difference between the two operands. We still consider them equal if the difference falls within this range. It is usually very small and insignificant to the model. We can call this range value our margin of tolerance. We augment our UDT with another member to cater for this:
Public Shared Function ApproxEquals(ByVal lhs As Vector, _
ByVal rhs As Vector, ByVal marginOfTolernace As Double) As Boolean
Dim diffMagnitude As Double = Math.Abs(lhs.Magnitude - rhs.Magnitude)
Dim diffDirection As Double = Math.Abs(CDbl((lhs.Direction - rhs.Direction)))
Return (diffDirection < marginOfTolernace) AndAlso _
(diffMagnitude < marginOfTolernace)
End Function
public static bool ApproxEquals(Vector lhs, Vector rhs, double marginOfTolerance)
{
double diffMagnitude = Math.Abs(lhs.Magnitude - rhs.Magnitude);
double diffDirection = Math.Abs((double)(lhs.Direction - rhs.Direction));
return (diffDirection < marginOfTolerance) &&
(diffMagnitude < marginOfTolerance);
}
Fig. 82 - Flexible and lenient equal operator
You can achieve similar results by rounding off the two operands to a certain decimal place. In this case, the parameter is the number of decimal places to which the values will be rounded to. I like the first approach because it centers on the culprit value. We can easily zero in to that value by displaying the difference of the direction between the two vectors.
Fig. 83 - Difference due to precision lost
It’s a very minute quantity indeed, and yet very capable of wrecking havoc to your query. This is rectified by the new operator we just added:
Fig. 84 - ApproxEquals at work
It is recommended that you have an approximate equality operator for a byte-ordered UDT. This gives you a flexible workaround for the putative equality anomalies when dealing with floating point values. Some developers choose to implement this in the Equals override to make the UDT a little compact. This approach has two disadvantages. First, it dilutes the true meaning of “equals”. It could be easily interpreted as the absolute equality operator because of its name. Second, it does not give you the flexibility of adjusting the margin of tolerance. It would require code modification just for changing the value of the margin.
At this point, our UDT is complete, and you should be able to take it for the ride. The illustration below shows a rundown of its members. You may verify its functionalities using some of the sites you can get from Googling "vector calculator". Remember that you won't get exactly the same answers because approximation might be involved in those calculators.
Fig. 85 - Struct UDT complete member list
Class implementation is a neglected aspect of UDT discussion. Most of the time, developers become dogmatic about the inherent benefits that value types, like struct, have when it comes to performance. We’ll find out if this is a reason enough to shy away from class implementation.
In this section, we also explore the implementation consideration entailed by a reference type such as a class. We’ll tackle them one by one as we create a class version of our struct UDT. To start, you need to copy and paste all the code from the struct UDT into a class named CVector.
One quirk worth mentioning before we go further is that in SQL-CLR, assigning an instance to a variable always creates a new instance regardless of if the UDT is implemented as a class or a struct. This is a departure from our usual understanding of the class implementation where assignment simply points the variable to the instance. It is still recommended that any implementation that is specific to the struct should be changed accordingly to maintain the intended behavior of the UDT outside SQL Server. This means changing our implementation of GetReversed such that it creates a new instance rather than point the new variable to the current instance. Our code does not compile yet because we haven’t defined our constructors.
<SqlMethod(IsMutator:=False)> _
Public Function GetReversed() As Vector
Dim reversed As New Vector(Magnitude, Direction)
reversed.Scale(-1)
Return reversed
End Function
[SqlMethod(IsMutator=false)]
public Vector GetReversed()
{
Vector reversed = new Vector(Magnitude, Direction);
reversed.Scale(-1.0);
return reversed;
}
Fig. 86 - GetReversed class implementation
The next set of modifications has something to do with the way we access our fields. If you look at Figure 9, we directly access our field even though it’s private. A class is strict with access modifiers, and this is no longer permitted. We’ll write constructors to cater for this need.
<SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native _
, IsByteOrdered:=True)> _
Public Class CVector
Implements INullable
Public Sub New()
Me.New(0, 0.0F, False)
End Sub
Public Sub New(ByVal magnitude As Double, ByVal direction As Single)
Me.New(magnitude, direction, False)
End Sub
Private Sub New(ByVal magnitude As Double, _
ByVal direction As Single, ByVal isNull As Boolean)
_direction = direction
_magnitude = magnitude
_isNull = isNull
End Sub
Public Shared Function Parse(ByVal input As SqlString) As CVector
Dim inputParts As String() = input.Value.Split(","c)
Dim magnitude As Double = Double.Parse(inputParts(0))
Dim direction As Single = Single.Parse(inputParts(1))
Dim v As New CVector(magnitude, direction)
Return v
End Function
Public Shared ReadOnly Property Null() As Vector
Get
Return New CVector(0, 0.0F, True)
End Get
End Property
[SqlUserDefinedType(Format.Native
, IsByteOrdered = true)]
public class CVector : INullable
{
public CVector() : this(0D, 0F, false) {}
public CVector(double magnitude, float direction)
: this(magnitude, direction, false) {}
private CVector(double magnitude, float direction, bool isNull)
{
_direction = direction;
_magnitude = magnitude;
_isNull = isNull;
}
public static CVector Parse(SqlString input)
{
string[] inputParts = input.Value.Split(',');
double magnitude = double.Parse(inputParts[0]);
double direction = float.Parse(inputParts[1]);
CVector v = new CVector(magnitude, direction);
return v;
}
public static CVector Null
{
get { return new CVector(0, 0.0F, true); }
}
Fig. 87 - Class UDT constructors
The private overload of these constructors is used just for setting the SQL-nullability field. It’s private in order to prevent setting of the SQL-nullability outside the SQL where it doesn’t have any meaning. The default overload is added to validate the lines that were originally calls to the constructor of the struct. The public and private operators are used by the Parse and Null functions respectively.
Our class UDT compiles without a glitch, but if you catalogue it, you would receive the following error:
Fig. 88 - Class UDT native serialization error
It’s obvious that this one is another case of a missing attribute. Don’t bother using the good ol’ Intellisense to rummage for the property in the existing attributes, because this one is arcane. If you’ve written considerable interop codes, then you must have encountered the StructLayoutAttribute in the System.Runtime.InteropServices namespace, which is what we need. It is relevant only to a class or struct type that is passed to unmanaged code. This is exactly what happens when SQL Server takes over the binary serialization of our class during persistence. The attribute has a Value property that is of type LayoutKind. This tells the unmanaged code how the members of the class are laid out in the memory. The LayoutKind.Sequential means the fields of our class UDT should be arranged in the memory in the same order we declare them. A struct type has an implicit LayoutKind.Sequential adornment, which is a good reason to prefer it over a class. Heeding the SQL Server request, our code becomes:
<SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native _
, IsByteOrdered:=True)> _
<StructLayout(LayoutKind.Sequential)> _
Public Class CVector
Implements INullable
Private _magnitude As Double
Private _direction As Single
Private _isNull As Boolean
[SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native
, IsByteOrdered = true)]
[StructLayout(LayoutKind.Sequential)]
public class CVector : INullable
{
double _magnitude;
float _direction;
bool _isNull;
Fig. 89 - StructLayout attribute
Cataloguing should succeed by now, and your class UDT is ready for action. There’s no other better way of doing this than a head to head match up against its struct counterpart, so I conducted another test. This time, I also included the user-defined-formatted class UDT. The test script simulates insertion and deletion of three tables, one for each serialization format of the UDT. The two transactions are contiguous, but I decided to show the results separately for clarity. Shown below is a fragment of the script intended for the table that uses the user-defined-formatted class UDT.
Fig. 90 - UDT insertion sample test script
The results for the insertion test were pretty much what we’ve expected. The difference between the struct and the struct-wannabe class was very insignificant, with the struct getting a meager 1.1% advantage. On the other hand, the manual binary serialization of the user-defined-formatted class led to its 32% lag from the struct-wannabe.
Fig. 91 - Insertion test result
If the insertion was pretty much expected, the deletion was a total surprise. The graph below doesn’t show any trend at all. I was fully aware that some other processes in my machine somehow affected the results, but what I couldn’t figure is how come the adjoining insertions seemed to be impervious. Another big surprise was the user-defined-formatted besting the native struct and class with advantage margins of 4.5% and 8.9%, respectively; not big, but still a point to ponder for an inquisitive mind. I’m not a SQL Server or CLR internal guy, so I can’t offer you a clear explanation for this.
Fig. 92 - Deletion test results
Based on the results, it looks like serialization is the performance clincher, and not the implementation type as probably most of us have assumed. We just saw how a class UDT achieved almost the same performance as that of a native struct by setting its serialization to native. Likewise, a user-defined-formatted struct performance should be no different from a user-defined-formatted class. But, if there’s one thing that should deter you from using a class, it has to be the fact that it involves more code than its struct counterpart.
If your UDT is user-defined, SQL Server has no idea how much space is needed to store it. You must specify the maximum possible byte size in the MaxByteSize property of the SqlUserDefinedTypeAttribute. The maximum amount for SQL Server 2005 is 8000, but this restriction is removed in SQL Server 2008. I'll elaborate on this momentarily.
We illustrate the usage of MaxByteSize by creating a user-defined-formatted version of our struct UDT. We add a property Unit of type string which accepts values “rad” for radian and “deg” for degree. You should also add the implementation of the IBinarySerialize similar to Figure 11, and the necessary modifications to the other members. The code fragments below show the adornment for the new UDT.
<SqlUserDefined(Format.UserDefined, IsByteOrdered:=True _
, ValidationMethodName:="ValidateInput", MaxByteSize:=17)> _
Public Structure Vector
Implements INullable
Implements IBinarySerialize
Private _unit As String
[SqlUserDefinedType(Format.UserDefined, IsByteOrdered=true
, ValidationMethodName="ValidateInput", MaxByteSize=17)]
public struct Vector : INullable, IBinarySerialize
{
string _unit;
Fig. 93 - MaxByteSize property
The maximum byte size of 17 was arrived by adding all the bytes needed for our fields. We already have 13 bytes, and the additional 4 is the maximum number of characters of the input: 3 bytes for the string plus the 1-byte overhead of string serialization. The size should be increased if you have plans for supporting non-US ASCII characters.
You may add validation routines to the property if you want this to become part of your UDT. Our current implementation simply accepts any literal of not more than 3 characters. Beyond this number, SQL Server would run out of memory for the serialization, as shown below:
Fig. 94 - Error from serialization buffer overflow
Another SqlUserDefinedAttribute property pertinent to user-defined-formatted UDT is IsFixedLength. This flag is a misnomer in my opinion, because it specifies whether or not you want SQL Server to allocate the maximum byte size for all the instances of your UDT. This is optional and defaults to true. If set otherwise, SQL server allocates only the exact bytes needed for the values of the fields for the instance. The decision involved here is usually influenced by the developer’s regard to performance and disk space. A UDT with fixed length is usually faster in queries, while one with variable length is space-efficient. Similar pros and cons apply to UDT as that for scalars, e.g., char vs. varchar, binary vs. varbinary, and others.
SQL-CLR allows you to control the characteristics of return values of your functions and properties thorough the SqlFacetAttribute. This attribute has properties corresponding to the different characteristic inherent to non-blittable types and the types found in the System.Data.SqlTypes namespace. You can find the list of supported data types and the properties they support in the Microsoft documentation. Our UDT does not contain any of the supported data types, but we can still illustrate this by changing the magnitude type to decimal. Be warned that this has an extensive effect in your existing codes. The snippet below shows an adornment of the attribute in a property.
<SqlUserDefinedType(Format.UserDefined, IsFixedLength:=False _
, MaxByteSize:=8000)> _
Public Structure Vector
Implements INullable
Implements IBinarySerialize
Private _magnitude As Decimal
<SqlFacet(Precision:=15, Scale:=8)> _
Public Property Magnitude() As Decimal
Get
Return _magnitude
End Get
[SqlUserDefinedType(Format.UserDefined, IsFixedLength=false
,MaxByteSize=8000)]
public struct Vector : INullable, IBinarySerialize
{
decimal _magnitude
[SqlFacet(Precision=15, Scale=8)]
public decimal Magnitude
{
get
{
return _magnitude;
}
Fig. 95 - Precision and Scale property of SqlMethodAttribute
In the code above, Precision is the total number of digits, while Scale is the number of digits to the right of the decimal point. We use the values in Figure 54 to illustrate the effects of the adornment. Note in the statements below, we call the property instead of ToString because SqlFacetAttribute has no effect inside the UDT. If you compare the results below with Figure 54, you can see that SQL Server indeed rounds off the magnitude as specified.
Fig. 96 - Precision and Scale at work
The placement of SqlFacetAttribute is misleading as far as a property is concerned. It suggests that the attribute encompasses both input and output. This can lead you to thinking that it has validation functionalities, when in fact, it only deals with presentation specification. We can confirm this by entering values that do not conform to the specifications of our adornment and see that it will still succeed:
Fig. 97 - SqlFacetAttribute has no validation specification
For me, the SqlFacetAttribute has limited role in UDT. I even avoid using the properties we just illustrated, because they can introduce precision loss if those adorned UDT properties are used in intermediate computations.
The remaining properties of SqlFacetAttribute are information that SQL Server can use when defining a database object based on the member being adorned. This is very rare in UDT, but common among other CLR artifacts like managed procedures, functions, and user defined aggregates. We will not explore them anymore.
With the rare use of UDT and the shipping of Microsoft's own UDT's in the form of spatial data types, it's no surprise that UDT received only one enhancement in SQL Server 2008. As I mentioned a while ago, UDT is no longer limited to 8000 bytes. This might just be an afterthought during the development of the spatial data types which are nothing more than UDT's themselves but it's still better than nothing. When I first apply this feature though, I was left scratching my head. The documentation is misleading. If you want a UDT bigger than the 8000 bytes, you are only allowed the value -1 in SqlUserDefinedAttribute.MaxSize property. Specifying anything greater than 8000 results to cataloguing error.
You’ve probably noticed that we haven’t delved deep into exceptions. Worse, we never even had any exception handling at all! I pointed out that Parse would be teeming with validation, and of course, exception handlers, but I completely left them out for brevity. Besides, a UDT is already in the core of an application, and the best thing you can do in an exception handler is re-throw the exception, accompanied by a friendly message. There might be situations specific to your domain where you should handle an exception in a different manner. As for the other unhandled exceptions, don’t fret; someone, somewhere has to catch them for you. The bottom line is that there are no other considerations when it comes to UDT exception handling. The best practices in .NET programming also apply here.
During the early days of my UDT tinkering, I thought that since enumeration is nothing more than a named numeric type, I would have no problem using it in a UDT. The tests I made then proved nothing could be farther from the truth. In a native format UDT, SQL Server insists that you should adorn the enumeration with LayoutKind.Sequential just like our native class UDT. This is not possible because StructLayoutAttribute cannot be applied to an enumeration. While in the user-defined format, your code will compile, but SQL Server cannot recognize the type. You will get a message similar to this:
Fig. 98 - Vague message from using an enumeration
The idea of having enumeration support for UDT was once attractive to me. Enumeration helps minimize errors through its type-safety feature while enhancing the readability of your SQL. I realized later that this is too much to ask for, considering that it’s actually tantamount to implementing an entirely new SQL-CLR object. If implemented, it could have rendered the lookup (name-value) table obsolete, and caused another barrage of debates; and we’ve had enough of that.
The User Defined Type (UDT) is probably the most significant among the SQL-CLR artifacts. No other artifact has effects on SQL Server as extensive and profound as UDT does. UDT became instrumental to the evolution of SQL Server beyond its relational foundation through the introduction of concepts like “object” and properties. Along with these are new T-SQL features required to interact with a UDT.
Unfortunately, UDT is also the most complex among the SQL-CLR objects. Its implementation is on one language, but its structure, characteristics, and behaviors are defined by another. This dual nature necessitates a slight departure from our conventional understanding of some common concepts in programming; something that can be attributed to the UDT's obscure nature. Adding to the complexity is the ample dosage of declarative programming involved to achieve the intended behaviors of the UDT.
UDT can be implemented using a class or a structure .NET construct. The common conception that value types like structures have performance advantage over reference types when it comes to high volume transactions is inapplicable in UDT. The performance determinant is not the type, but the serialization format used in the UDT. Native serialization is faster than user defined. If there is a good reason to shy away from a class, it's the fact that it's more verbose than a structure implementation.
Perhaps, the greatest benefit of UDT has yet to be realized. By allowing us to store data of virtually any structure, it can pave the way for an entirely new class of applications. Microsoft seems to be heading that way, and it’s just a matter of time before UDT would finally gain prominence.
- 23rd August, 2008 - Initial draft
- Included SQL Server 2008 changes

