Introduction
This article discusses Grouping Sets in T-SQL. Grouping Sets is a new feature in T-SQL in SQL Server 2008.
Background
People cannot help appreciating the GROUP BY clause whenever they have to get a DISTINCT from any result set. Additionally, whenever any aggregate function is required, the GROUP BY clause is the only solution. There has always been a requirement get these aggregate functions based on different sets of columns in the same result set. It is also safe to use this feature as this is an ISO standard.
Though the same result could be achieved earlier, we would have to write different queries and would have to combine them using a UNION operator. The result set returned by a GROUPING SET is the union of the aggregates based on the columns specified in each set in the Grouping Set.
Example
To understand it completely, first we create a table tbl_Employee.
CREATE TABLE tbl_Employee
(
Employee_Name varchar(25),
Region varchar(50),
Department varchar(40),
sal int
)
Now, we populate the table with some of the following rows:
INSERT into tbl_Employee(
Employee_Name,
Region,
Department,
sal
)
VALUES
('Shujaat', 'North America', 'Information Technology', 9999),
('Andrew', 'Asia Pacific', 'Information Technology', 5555),
('Maria', 'North America', 'Human Resources', 4444),
('Stephen', 'Middle East & Africa', 'Information Technology', 8888),
('Stephen', 'Middle East & Africa', 'Human Resources', 8888)
After populating with the rows, we select some rows using Grouping Sets.
SELECT Region, Department, avg(sal) Average_Salary
from tbl_Employee
Group BY
GROUPING SETS
(
(Region, Department),
(Region),
(Department) ,
()
)
The result of this statement is as follows:
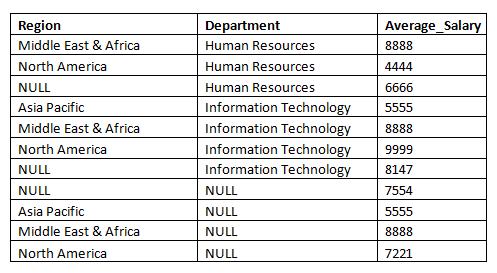
You can see that the result set contains rows grouped by each set in the specified Grouping Sets. You can see the average salary of employees for each region and department. You can also appreciate the average salary of employees for the organization (NULL for both Region and Department). This was the result of the empty Grouping Set, i.e., ().
Before 2008, if you had to get the same result set, the following query had to be written:
SELECT Region, Department, avg(sal) Average_Salary
from tbl_Employee
Group BY
Region, Department
UNION
SELECT Region, NULL, avg(sal) Average_Salary
from tbl_Employee
Group BY
Region
UNION
SELECT NULL, Department, avg(sal) Average_Salary
from tbl_Employee
Group BY
Department
UNION
SELECT NULL, NULL, avg(sal) Average_Salary
from tbl_Employee
By looking at the above query, you can appreciate the ease provided by Grouping Sets to developers.
CUBE subclause for grouping
This is used to return the power n to 2 for n elements.
SELECT Region, Department, avg(sal) Average_Salary
from tbl_Employee
Group BY
CUBE (Region, Department)
The above query is equivalent to the following query:
SELECT Region, Department, avg(sal) Average_Salary
from tbl_Employee
GROUPING SETS
(
(Region, Department),
(Region),
(Department) ,
()
)
ROLLUP subclause for grouping
This is used to return n+1 grouping sets for n elements in a hierarchy scenario.
SELECT Region, Department, avg(sal) Average_Salary
from tbl_Employee
Group BY
ROLLUP (Region, Department)
This is equivalent to the following query:
SELECT Region, Department, avg(sal) Average_Salary
from tbl_Employee
Group BY
Grouping Sets
(
(Region, Department),
(Region),
()
)

