Introduction
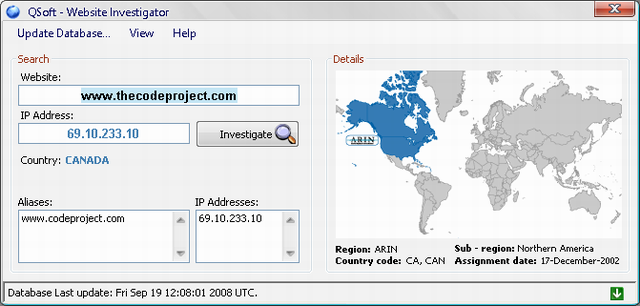
As you can see from the article's category, this is a desktop gadget application that searches for a given website registration information.
IPv4 uses 32-bit (four-byte) addresses, which limits the address space to 4,294,967,296 (232) possible unique addresses. However, some are reserved for special purposes such as private networks (~18 million addresses) or multicast addresses (~16 million addresses). This reduces the number of addresses that can be allocated as public Internet addresses. As the number of addresses available are consumed, an IPv4 address shortage appears to be inevitable, however Network Address Translation (NAT) has significantly delayed this inevitability.
This limitation has helped stimulate the push towards IPv6, which is currently in the early stages of deployment and is currently the only contender to replace IPv4.
Background
As we all know, each website is assigned a unique IP Address (Internet Protocol Address) that differentiates it from other websites. Once the website is hosted at some local or remote server, a given set of information is registered for later enquirers, these are the IP Address and its assignment time.
The Website IP Address
The website IP address determines a lot of things for the website, such as, the range of the IP address which can tell you what country it is registered to and hence, where the host is located.
Usually, the IP address is not stored in the ordinary four segment dot-decimal notation format, but in a decimal format that represents the four octets of an IP address.
There are other notations based on the values of 200.100 in the dot-decimal notation which comprises four octets in decimal separated by periods. This is the base format used in the conversion in the following table:
| Notation | Value | Conversion from dot-decimal |
| Dot-decimal notation | 192.0.2.235 | N/A |
| Dotted Hexadecimal | 0xC0.0x00.0x02.0xEB | Each octet is individually converted to hex |
| Dotted Octal | 0300.0000.0002.0353 | Each octet is individually converted into octal |
| Hexadecimal | 0xC00002EB | Concatenation of the octets from the dotted hexadecimal |
| Decimal | 3221226219 | The hexadecimal form converted to decimal |
| Octal | 030000001353 | The hexadecimal form converted to octal |
Take the CP's IP address as an example:
| Data Type | Value |
| Dot-decimal | 69.10.233.10 |
| Binary | 01000101 . 00001010 . 11101001 . 00001010 |
| Decimal | 1158342922 |
Determining the location of the host "the country" from a specific IP range will result in recognizing what region and sub region that country is in, but first, we need to know what is the location of this decimally converted IP address within the global IP register.
Decimal IP Conversion
To calculate the decimal address from a Dot-decimal, use the following formula:
| Decimal IP | (1st octet * 2563) + (2nd octet * 2562) + (3rd octet * 2561) + (4th octet * 2560) |
=
| (1st octet * 16777216) + (2nd octet * 65536) + (3rd octet * 256) + (4th octet * 1) |
=
| (69 * 16777216) + (10 * 65536) + (233 * 256) + (10) |
=
| 1158342922 |
The Website Assignment Date and Time
There are two layers of encoding that make up Unix time, and they can be usefully separated. The first layer encodes a point in time as a scalar real number, and the second encodes that number as a sequence of bits or in some other manner.
Hence the website assignment date and time is stored in Unix epoch format. In this article, our main concern will be the Unix epoch time format.
Unix time, or POSIX time, is a system for describing points in time, defined as the number of seconds elapsed since midnight Coordinated Universal Time (UTC) of January 1, 1970, not counting leap seconds. It is widely used not only on Unix-like operating systems but also in many other computing systems. It is neither a linear representation of time nor a true representation of UTC (though it is frequently mistaken for both) as the times it represents are UTC but it has no way of representing UTC leap seconds (e.g. 1998-12-31 23:59:60).
The Unix epoch is the time 00:00:00 UTC on January 1, 1970. There is a problem with this definition, in that UTC did not exist in its current form until 1972; this issue is discussed below. For brevity, the remainder of this section will use ISO 8601 date format, in which the Unix epoch is 1970-01-01T00:00:00Z.
The Unix time number is zero at the Unix epoch, and increases by exactly 86 400 per day since the epoch. Thus 2004-09-16T00:00:00Z, 12 677 days after the epoch, is represented by the Unix time number 12 677 × 86 400 = 1 095 292 800. This can be extended backwards from the epoch too, using negative numbers; thus 1957-10-04T00:00:00Z, 4472 days before the epoch, is represented by the Unix time number -4472 × 86 400 = -386 380 800.
Within each day, the Unix time number is as calculated in the preceding paragraph at midnight UTC (00:00:00Z), and increases by exactly 1 per second since midnight. Thus 2004-09-16T17:55:43.54Z, 64 543.54 s since midnight on the day in the example above, is represented by the Unix time number 1 095 292 800 + 64 543.54 = 1 095 357 343.54. On dates before the epoch the number still increases, thus becoming less negative, as time moves forward.
Epoch Time Conversion
Since epoch time is nothing but the accumulated seconds since the 1st of January 1970, we will simply create a time span of the 1/1/1970 and add those seconds to it and of course, reformat to a human readable format:
private string Epoch_To_Date(string strEpoch)
{
DateTime _dateTime = new DateTime(1970, 1, 1, 0, 0, 0);
_dateTime = dateTime.AddSeconds(Convert.ToDouble(strEpoch));
return _dt.ToString("dd-MMMM-yyyy");
}
We simply call the function and assign the value it would return in a string variable:
string strDate = Epoch_To_Date(strEpochValue);
Using the Code
First we create the data table that will hold our data and assign 7 columns to it:
DataTable dt = new DataTable("IP_TO_COUNTRY");
dt.Columns.Add("IP_From", typeof(string));
dt.Columns.Add("IP_To", typeof(string));
dt.Columns.Add("Region", typeof(string));
dt.Columns.Add("Assignment_Date", typeof(string));
dt.Columns.Add("Two_Letter_Code", typeof(string));
dt.Columns.Add("Three_Letter_Code", typeof(string));
dt.Columns.Add("Country_Name", typeof(string));
Create a stream reader and read our CSV file "Comma Separated Values".
StreamReader sr = new StreamReader(strDatabasePath);
Then we load to the DataTable we just created:
while (!sr.EndOfStream)
{
try
{
tokens = sr.ReadLine().Split(',');
#region Update last update lable
if (tokens.Length > 0)
if (tokens[0].ToString().StartsWith
(@"# File Time Stamp : "))
lblLastUpdate.Text = "Database Last update: "
+tokens[0].Replace(@"# File Time Stamp : ", "");
#endregion
if (tokens.Length == 7)
dt.Rows.Add(tokens);
}
catch (Exception ex) { MessageBox.Show(ex.Message); }
}
sr.Close();
Now let's take a look at the Load_info function:
private void load_info(double _ip)
private void load_info(double _ip)
{
try
{
double d_IP_From, d_IP_To;
foreach (DataRow dr in dt.Rows)
{
d_IP_From = Convert.ToDouble(dr["IP_From"].ToString().Trim().Replace
("#", "").Replace(@"""", ""));
d_IP_To = Convert.ToDouble(dr["IP_To"].ToString().Trim().Replace
("#", "").Replace(@"""", ""));
if ((Convert_IP(txtIP.Text) > d_IP_From) &&
(Convert_IP(txtIP.Text) < d_IP_To))
{
lbl_CountryName.Text = dr["Country_Name"].ToString().Trim().Replace
("#", "").Replace("\"", "");
lblRegion.Text = dr["Region"].ToString().Trim().Replace("#", "").Replace
("\"", "");
lblCountryCode.Text = dr["Two_Letter_Code"].ToString().Trim().Replace
("#", "").Replace("\"", "") + ", " +
dr["Three_Letter_Code"].ToString().Trim().Replace
("#", "").Replace("\"", "");
lblAssignmentDate.Text = Epoch_To_Date
(dr["Assignment_Date"].ToString().Trim
().Replace("#", "").Replace("\"", ""));
lblSubRegion.Text = GetSubRegion(lbl_CountryName.Text);
}
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message,"Error",
MessageBoxButtons.OK,MessageBoxIcon.Error);
}
}
Points of Interest
Reading data from CSV files can be rather tricky, hence, you should be careful in what you feed your DataTable object. In this article, we had to check for the number of columns while reading each line of the CSV file.
History
- Website investigator ver 1.0 10th September, 2008
- Website investigator ver 1.1 15th September, 2008
- Website investigator ver 2.0 19th September, 2008
- Updated source 5th August, 2009

