Introduction
FastReplacer is good for executing many Replace operations on a large string when performance is important.
The main idea is to avoid modifying existing text or allocating new memory every time a string is replaced.
We have designed FastReplacer to help us on a project where we had to generate a large text with a large number of append and
replace operations. The first version of the application took 20 seconds to generate the text using StringBuilder. The second improved version
that used the String class took 10 seconds. Then we implemented FastReplacer and the duration dropped to 0.1 seconds.
Using the code
Use of FastReplacer should come intuitively to developers that have used StringBuilder before.
Add classes FastReplacer and FastReplacerSnippet to your C# console application and copy the following code in Program.cs:
using System;
using Rhetos.Utilities;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
FastReplacer fr = new FastReplacer("{", "}");
fr.Append("{OPTION} OR {ANOTHER}.");
fr.Replace("{ANOTHER}", "NOT {OPTION}");
fr.Replace("{OPTION}", "TO BE");
Console.WriteLine(fr.ToString());
}
}
}
Note that only properly formatted tokens can be replaced using FastReplacer. This constraint is set to ensure good performance
since tokens can be extracted from text in one pass.
Case-insensitive
For a case-insensitive replace operation, set the additional constructor parameter caseSensitive to false (default is true).
FastReplacer fr = new FastReplacer("{", "}", false);
fr.Append("{Token}, {token} and {TOKEN}.");
fr.Replace("{tOkEn}", "x");
Console.WriteLine(fr.ToString());
What is in the package
The algorithm is implemented in two C# classes on .NET Framework 4.0. To use them, simply copy them into your project:
FastReplacer – Class for generating strings with a fast Replace function. FastReplacerSnippet – Internal class that is used from FastReplacer. No need to use it directly.
The attached solution contains three projects for Visual Studio 2010:
Rhetos.Utilities – A class library with the FastReplacer class and the FastReplacerSnippet class.FastReplacerDemo – Demonstration console application. Contains samples and performance tests used in this article.FastReplacerTest – Unit tests for FastReplacer. All cool features can be seen in these tests.
Performance
Speed
Using String or StringBuilder to replace tokens in large text takes more time because every time a Replace function is called,
a new string is generated.
These tests were performed with FastReplacerDemo.exe (attached project) on a computer with Windows Experience Index: Processor 5.5, Memory 5.5.
| ReplaceCount | TextLength | FastReplacer | String | StringBuilder |
| 100 | 907 | 0.0008 sec | 0.0006 sec | 0.0014 sec |
| 300 | 2707 | 0.0023 sec | 0.0044 sec | 0.0192 sec |
| 1000 | 10008 | 0.0081 sec | 0.0536 sec | 1.2130 sec |
| 3000 | 30008 | 0.0246 sec | 0.4515 sec | 43.5499 sec |
| 10000 | 110009 | 0.0894 sec | 5.9623 sec | 1677.5883 sec |
| 30000 | 330009 | 0.3649 sec | 60.9739 sec | Skipped |
| 100000 | 1200010 | 1.5461 sec | 652.8718 sec | Skipped |
Memory usage
Memory usage while working with FastReplacer is usually 3 times the memory size of the resulting text. This includes:
- Original strings sent to
FastReplacer as an argument for Append, Replace, InsertBefore, and InsertAfter functions. - Temporary memory used while generating final text in the
FastReplacer.ToString function. - The final generated string.
The algorithm
Using the conventional string.Replace function or StringBuilder.Replace function to generate large text takes O(n*m)
time, where n is the number of replace operations that is executed and m is the text length, because a new string is generated every time the function is executed.
This chapter explains that FastReplacer will take O(n*log(n) + m) time for the same task.
Tokens
Tokens are recognized in text every time a new text is added (by the Append, Replace, InsertBefore, and InsertAfter functions).
Positions of tokens are kept in a Dictionary for fast retrieval. That way searching for a text to be replaced takes O(n*log(n) + m) time
instead of O(n*m). That is good, but the following part of the algorithm has more impact.
Snippets
When the Replace function is called to replace a token with a new string, FastReplacer does not modify existing text.
Instead, it keeps track of the position in the original text where the token should be cut out and the new string inserted. Next time the Replace function
is called, it will do the same on the original text and in the new strings that were previously inserted. That creates a directed
acyclic graph where every node (called FastReplacerSnippet) represents a string with information where it should be inserted
in its parent text, and with an array of child nodes that should be inserted in that string.
Every replace operation takes O(log n) time to find the matching token (covered in the previous chapter) and O(1) to insert a new node in the data structure.
Generating the final string takes O(m) time because there is only one pass through the data structure to recursively collect all the parts that need to be concatenated.
Sample 1
For example, in the string “My {pet} likes {food}.”, if token “{pet}” is replaced with “tortoise”,
the following data structure will be created:
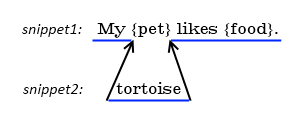
The final text will be composed by concatenating the text parts “My ”, “tortoise”, and “ likes {food}.”.
Sample 2
A more complex example is the text “{OPTION} OR {ANOTHER}”. If the token “{ANOTHER}” is replaced with “NOT {OPTION}”, then the token “{OPTION}”
replaced with “TO BE”, we will get the following structure:
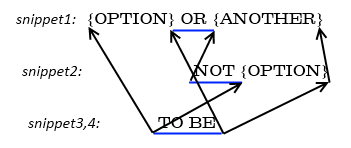
Constraints
When snippets of text are inserted, tokens are searched in every snippet separately. Tokens in every snippet must be properly formatted. A token cannot
start in one snippet then end in another.
For example, you cannot insert a text that contains only the beginning of a token (e.g., “Hello {”) then append a text with the end of the token (e.g., “USERNAME}.”).
Each of these function calls would fail because the token in each text is not properly formatted.
To ensure maximal consistency, FastReplacer will throw an exception if the inserted text contains an improperly formatted token.
History
- 2011-12-12 – Initial post.
- 2013-09-06 – Minor improvements in the attached source.

