Introduction
One of the challenges in cryptography is generating seemingly random number sequences for use as encryption keys.
As you may know, any “random” number generated by a computer is not really random, it is what is called “pseudo-random” – the numbers come
from recursively solving a mathematical equation from a given ‘seed’ number. The sequence will be different with each given seed value, and if you have a
set of numbers and access to the algorithm that created them, it wouldn’t take a computer very long to determine the seed value used.
Modern symmetrical encryption systems use a starting “key” that is up to 256 bits long (for us civilians anyway) and combine this with an
initialization-vector (also up to 256 bits long). By applying the vector to the key through some scary mathematics, millions of unique permutations can be
created, and these are combined with the data to obscure it. This process can then be run in reverse to retrieve the original information (hence the term “symmetrical”).
A problem with these mathematical encryption systems is that the process is mathematically derived, and the algorithms published. For every
encryption algorithm that gets created, eventually someone works out a mathematical way of solving it. Even the latest and greatest AES algorithms have now been theoretically cracked.
The idea that chaos theory could be used to generate encryption keys is not necessarily a new one, but as yet I have not seen any examples.
Background
Chaos theory teaches us that even very simple rules can lead to extremely complex and unpredictable behaviour. The scatter of water droplets
from a dripping tap is never the same twice, even though each drip is an almost exact duplicate of the last. Microscopic changes in the environment have
dramatic effect on the path of individual particles within the water.
However, if you were able to duplicate the circumstances of a drip down to the quantum level, the path of the spray of droplets would be the same.
There are in fact, entire volumes of work done on the chaos of a dripping tap.
In 1970, John Conway, interested in simplifying von Neumann’s Finite-State-Automata (a hypothetical self-replicating machine that ‘lives’
on a 2D Cartesian grid), came up with a simple set of rules to what would become the “Game of Life”.
The game of life is played on a grid, divided into cells. Each cell can be “alive” or “dead” and a set of four rules determine whether any
given cell will live, die, or be born in each iteration.

The game’s simple set of rules brought rise to surprisingly complex and compelling behaviour, and around it sprang a new field of research called “Cellular Automata”.
Entire worlds, even von-Neumann’s self-replicating structures can be built within the boundaries of the game of life, and the
parallel between our own universe’s simple set of rules and that of the game of life has been a subject of much scientific, philosophical, and even religious debate.
One interesting point that can be drawn from this field is that any cellular-automata simulation, no matter how complex, is completely
determined from the starting state of cells on the grid. If you arrange the initial cells the same way, the results will always be the same after a set number of generations.
This has drawn out an interesting debate on the nature of free will – if our universe was reset to the exact same quantum starting
arrangement, would it turn out the same? What does that say about our choices?
Philosophy aside, there are some useful aspects to this: from a single configuration of cells within a grid, an enormous volume of unpredictable, complex information
can be constructed. After a thousand generations, who could predict which cells would be active without actually knowing the initial state and running the entire simulation?
If one single cell was different in the starting configuration, after sufficient generations, the state of every cell would eventually be different.
Applications in Cryptography
Could Cellular Automata be useful in the field of cryptography? While deterministic, the information represented by the cells of a cellular-automata simulation
is not generated through reversible, logical mathematical algorithms; it is generated through a process not unlike real life. This might actually be the closest
we can get to generating truly random data from a computer, and yet be able to reproduce it exactly should we know the initial configuration.
By choosing an arrangement of cells on a grid, a set of rules, and an agreed number of generations, it should be possible to generate
almost limitless, non-repeating sequences of apparently random numbers that might be used to securely encrypt sensitive data.
The initial arrangement of cells and the number of generations would become the “key” for the encryption.
Unraveling the grid, by rows or by columns, and choosing “alive” for true, and “dead” for false, allows a grid of cells to become a sequence of binary digits.
Because the pattern of data does not repeat, nor follow logical mathematical progressions, even the normally cryptographically weak
process of obscuring data with an exclusive OR (XOR) operation becomes significantly stronger.
I intend to explore this by developing a secure cryptographic system using cellular automata to generate the key data, and
using simple XOR to encrypt each bit.
Designing the Software
The first step was obviously to create a cellular automata simulation. This is a pretty typical programming problem, and is often set as a
programming task for students. I have written my own for fun in the past; however this one needs to be slightly different.
Instead of the typical solution to the problem (a pair of two dimensional Boolean arrays, one to hold the current generation, and another to
hold the results of the next generation), I wanted to use OO design philosophy to quickly implement the solution, and the data to be easily accessible in a
linear fashion - not constrained by the dimensions of an array.
I settled for holding the data in a list of cells. Each cell object would remember its grid position, current and to-be state, and be linked to its neighbours.
It’s not a particularly fast solution, but it offers flexibility and was quick and easy to program. Much smarter people than me have
spent lots of time coming up with some very fast implementations of CA algorithms; I’m not going to attempt that feat.
I gained some optimizations by using public fields instead of properties, and keeping the ‘cell’ class as small as possible. Also,
generating the cells by rows and columns in a specific order means the index of each grid coordinate can be easily calculated, allowing access to the cells by index and by x/y coordinates.
protected int getIndex(int x, int y)
{
return (x * _height) + y;
}
Once I had created my basic cell grid, I added two sets of rules. Conway’s original set of four rules, and the much simpler Fredkin rule
(which is based on whether the number of living neighbour cells is odd or even).
The issue I have found with Conway’s rules for this particular application is that unless you have setup a very specific initial pattern, it
tends to burn itself out in a few generations. Most cells having died, and a couple oscillating back and forth in the same fixed pattern.
By contrast, the simple Fredkin rule means about half the cells are going to be alive in any given iteration, which lends itself to a
good statistical spread of data, and doesn’t peter out or stabilize after a limited number of generations.
Fredkin's Rule
public void RunFredkinRule()
{
foreach (var cell in _cells)
{
if (cell.LivingNeighbours % 2 == 0)
cell.NextState = false;
else
cell.NextState = true;
}
Commit();
}
Conway's Rules
public void RunConwaysRule()
{
foreach (var cell in _cells)
{
int neighbours = cell.LivingNeighbours;
if (cell.State && neighbours < 2)
cell.NextState = false;
if (cell.State && (neighbours == 2 || neighbours == 3))
cell.NextState = true;
if (cell.State && neighbours > 3)
cell.NextState = false;
if (!cell.State && neighbours == 3)
cell.NextState = true;
}
Commit();
}
Initializing the Grid
The next step was to decide how the grid might be initialized. In the end I came up with three solutions.
The first was to use an existing bitmap image. The grid width and height are set to the same dimensions as the original image, and the
state of each cell is set from the brightness of the corresponding source pixel, through a process called error-diffusion (where the darker the pixel,
the more likely the cell would become active, with a black pixel having a 100% chance, and a while pixel 0% chance).
Below: An original bitmap and a visual representation of the corresponding CA grid initialized using error-diffusion.
This solution still bothered me, as I wanted to be able to enter a simple seed or “passcode” to generate the initial state of the grid.
I settled on dynamically creating a bitmap, by writing the “passcode” onto the bitmap, then initializing the grid using the existing
error-diffusion based code. I added a gradient to the background to increase the complexity.
This way, the bitmap would be unique to the pass-code, and I got to reuse my initial method:
The third initialization method I came up with was to use the .NET built-in pseudo-random number generator to randomly set each cell to be ‘alive’ or ‘dead’, using a seed value as the “key”.
While the random number generator by itself is an awfully insecure method of generating a key, I figured the nature of the process should
overcome this, as none of the original sequence would be left after even one generation.
public void BuildFromPseudoRandomNumbers(int seed, int width, int height)
{
BuildGrid(width, height);
Random rnd = new Random(seed);
foreach (var cell in _cells)
{
if (rnd.NextDouble() > 0.5)
cell.State = true;
}
}
To retrieve binary data from the grid, the cells are simply enumerated and a Boolean array populated using the “state” of each cell:
public bool[] GetBinaryCellData(int len)
{
bool[] data = new bool[len];
for (int i = 0; i < data.Length; i++)
{
data[i] = _cells[i].State;
}
return data;
}
This is converted to a byte-array using the .NET BitArray class:
public byte[] GetBytes(int bytes)
{
BitArray ba = new BitArray(GetBinaryCellData(bytes * 8));
byte[] buffer = new byte[bytes];
ba.CopyTo(buffer, 0);
return buffer;
}
Using Cell Data for Encryption
I struggled with this for a while. I’m not a cryptographer, nor a mathematician. I figured the way to do it was to compare each bit of the
information I wanted to encrypt, against each bit of the generated cell data, using the relationship between the two bits to come up with a third.
This had to work backwards also, in order to retrieve the information.
The logical operation XOR seems to be perfect for this, however I had some doubts - XOR encryption is notoriously easy to crack.
So I did a little research, and it seems that the problem with XOR encryption is that if you can guess a sufficient amount of the source
data (like common file headers, for example) or if the source data has a long run of zero’s, parts of the key can be revealed.
This assumes though, that revealing part of the key would assist in calculating the rest of the key. For key-data generated by
traditional, algorithmic pseudo-random number generators, this is definitely true: get enough of the sequence and you can back-track the seed.
However, for the purposes of evaluating the strength of cellular-automata-derived keys, which don’t repeat, XOR is actually perfect: if the resulting encryption
cannot be broken, given such a simple encoding method, then this is a good indication that the application of chaos theory to the generation of encryption keys is valid.
Generating Large Blocks of Key Data
The amount of data retrieved from a grid is dependent on the size of the grid. The bigger the grid, the more processing is required to calculate it.
Also, the index field for the .NET list object is only 24 bits long. This limits the contents to 16.7 million items.
With only 1 bit per item, the maximum amount of data generated by a single block is 2 MB, which is a bit constrictive.
However, if the contents of a grid are read, and the CA rules are processed again, a whole new block of data can be read from the grid.
So, by initializing a small size block that generates say, 1KB of data, and re-iterating the CA rules repeatedly, an unlimited set of data can be generated.
I worried whether this would produce truly unique data each time, so I generated 10MB of data using this process (which took some time),
and ran it through the Die-Hard set of statistical tests. The results of the tests indicate that the data is still random, with no significantly repeated sets of numbers.
Disadvantages
The main disadvantage seems to be the amount of processing required to generate the key data. Compared to other encryption techniques,
this method would not be effective at encrypting large amounts of data.
Using more efficient algorithms to run the CA grid could gain some ground, but not to the extent that say, the Rijndael algorithm can perform.
Using the Code
There are two main components to the system:
- The
CAGrid class is a simple implementation of the Cellular Automata simulation. It contains a list of Cell objects, methods to build the
grid and hook each cell to its neighbours, methods to run the rules and increment each generation, and methods to retrieve the data as an array of bytes or Booleans. - The
CAEncryption class utilizes the CAGrid in order to provide cryptographic functions.
Static methods of the CAEncryption class are provided for generating large blocks of key data. These use the progressive method of extracting
the data from a grid, then re-running the simulation to provide more data. Additional static methods are provided for symmetrically encrypting streams and files.
A class that can be serialized to disk is provided for saving an encrypted file. This contains the original file name as a property to
ease the process of decrypting the data. The encrypted file is stored as a byte array within said class.
All the static encryption methods use the Random class to initialize the grid using a seed value.
By instancing the CAEncryption class, the methods to generate encryption key data from a bitmap are implemented.
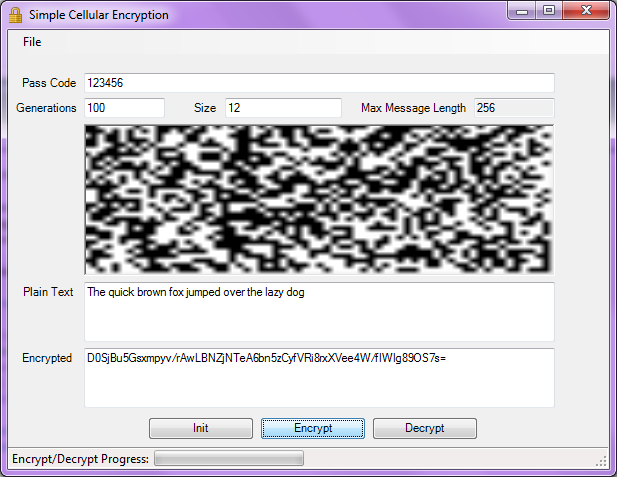
All these are tied together using the main form for the system: FrmCellularEncryption.
Proving the Concept
I posted this article with some trepidation, I anticipate many will automatically claim that the entire concept is inherently insecure and could be defeated with ease.
So, I am throwing down the gauntlet, and giving neigh-sayers the opportunity to put their money where their mouth is.
I challenge any reader to recover the original text of this encrypted string:
W/frtrsDSreqBwK2N7bS14jUsUX88NgjHJEndWDd16YuHYjBoxy6goa6hS53
jWI1zQCl1lE3DP5h8rEVeLvKHVJ0t5D/+Pz0lWQsS992KgBsVWEaMPZJBuIfUBMrqBKLOx5
kXClqEJ5lpflfy9+NO31okIB4w6thbD77bwrSf0nxFW/tsRDxXv4uvAzdbqny009+CUVSaO
ZAtsQc1NoLaymcsPGamzcH6NhdMuqnTfR1KqlJfIrYyyfjT/lXAOGOi2jdvW69wjbb8EdWBP+
nm1tS6q7sC56RwKx+jQBGDRPJaUXGkj0OKt/o6DP28HVWL35oY9XPVn9QrksF0C3Huu6uw5k3
b8FWeGfv6CLaCWYMg6GSgtADNOm+e8zKTOK6xOpmK8zwUV+P5DiAu0nylHn43BawqA2DhB/b
hedkSNxfmUBXObJMl2AWXv3jagbmRA2qqLV7gDWlOE90SfoObHpPTk+irSTpW6ulOA==
You have full access to the source code that performed the encryption (thus much more information than you would get in real life);
if you succeed and post the original text, you win my respect and the right to whine all you want. Moreover, in the process, we can prove or disprove the viability
of using cellular automata to encrypt sensitive data.

