Introduction
Linear Regression is an important algorithm of supervised learning. In this article, I am going to re-use the following notations that I have referred from [1] (in the References section):
- xi denotes the “input” variables, also called input features
- yi denotes the “output” or target variable that we are trying to predict
- A pair (xi, yi) is called a training example
- A list of m training examples {xi, yi; i = 1,…,m} is called a training set
- The superscript “i” in the notations (xi and yi) is an index into the training set
- X denotes the space of input values and Y denotes the space of output values. In this article, I am going to assume that X = Y = R
- A function h: X -> Y, where h(x) is a good predictor for the corresponding value of y, is called a hypothesis or a model
When the target variable that we are trying to predict is continuous, we call the learning problem a regression problem. When y takes on only a small number of discrete values, we call it a classification problem.
Background
In machine learning, if we are talking about regression, we often mean linear regression. Linear regression means you can add up the inputs multiplied by some constants to get output and we are going to represent h function as follows:
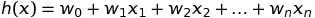
Where the wi’s are the parameters (also called weights) parameterizing the space of linear functions mapping from X to Y. To simplicity, we also assume that x0 = 1 and our h(x) can look like this:

If we view w and x both as vectors, we can re-write h(x):
Where x = (x0, x1, x2,…,xn) and w = (w0, w1,…,wn).
So far, a question is going to occur that is how can we get the weights w? To answer this question, we are going to define a cost function that is used to compute error as the difference between predicted h(x) and the actual y. The cost function looks like this:
We want to choose w so as to minimize costF(w). To do this, there are two approaches:
- First approach, we are going to use gradient descent algorithm to minimize
costF(w). In this approach, we repeatedly run through the training set, and each time we encounter a training example, we update the weights according to the gradient of the error with respect to that single training example only. - Second approach, we are going to minimize
costF by explicitly taking its derivatives with respect to w, and setting them to zero. We can set this to zero and solve for w to get the following equation:
You can discover more about these approaches in [1]. To use the code, in this article, I am going to use the TensorFlow library for the first approach and the NumPy library for the second approach.
Using the Code
Initializing a Linear Model
In this article, I assume that our model (or h function) is the following equation:
h(x) = w1*x + w0, where x0 = 1, x1 = x
Initializing a Training Set
We need to initialize data by creating the following Python script:
import numpy as np
import matplotlib.pyplot as plt
x_train = np.linspace(0, 10, 100)
y_train = x_train + np.random.normal(0,1,100)
plt.scatter(x_train, y_train)
plt.show()
If you run this script, the result can look like this:
Gradient Descent Algorithm Approach
In this approach, we repeatedly run through the training set, and each time we encounter a training example, we update the weights according to the gradient of the error with respect to that single training example only. The following code will allow you to create a best-fit line for the given data by using TensorFlow library:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
learning_rate = 0.01
training_epochs = 100
x_train = np.linspace(0, 10, 100)
y_train = x_train + np.random.normal(0,1,100)
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
def h(X, w1, w0):
return tf.add(tf.multiply(X, w1), w0)
w0 = tf.Variable(0.0, name="weights")
w1 = tf.Variable(0.0, name="weights")
y_predicted = h(X, w1, w0)
costF = 0.5*tf.square(Y-y_predicted)
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(costF)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for epoch in range(training_epochs):
for (x, y) in zip(x_train, y_train):
sess.run(train_op, feed_dict={X: x, Y: y})
w_val_0 = sess.run(w0)
w_val_1 = sess.run(w1)
sess.close()
plt.scatter(x_train, y_train)
y_learned = x_train*w_val_1 + w_val_0
plt.plot(x_train, y_learned, 'r')
plt.show()
If we run this script, the result can look like this:
Matrix Derivatives Approach
In this approach, we are going to minimize costF by explicitly taking its derivatives with respect to w, and setting them to zero. You can use Matrix methods from the TensorFlow library but here I am going to use the NumPy library for solving this problem. The following code will allow you to create a best-fit line for the given data by using the NumPy library:
from numpy import *
import numpy as np
import matplotlib.pyplot as plt
x_train = np.linspace(0, 10, 100)
y_train = x_train + np.random.normal(0,1,100)
xArr = []
yArr = []
for i in range(len(x_train)):
xArr.append([1.0,float(x_train[i])])
yArr.append(float(y_train[i]))
def linearRegres(xArr,yArr):
xMat = mat(xArr); yMat = mat(yArr).T
xTx = xMat.T*xMat
if linalg.det(xTx) == 0.0:
print("This matrix is singular, cannot do inverse")
return
ws = xTx.I * (xMat.T*yMat)
return ws
w_val = linearRegres(xArr,yArr)
plt.scatter(x_train, y_train)
y_learned = mat(xArr)*w_val
plt.plot(x_train, y_learned, 'r')
plt.show()
The result of running the script above can look like this:
Points of Interest
In this article, I introduced two approaches to solve a linear regression problem. One problem with linear regression is that it tends to underfit the data and one way to solve this problem is a technique known as locally weighted linear regression. You can discover more about this technique in [1].
References
- [1] CS229 Lecture notes by Andrew Ng
- [2] Machine Learning in Action by Peter Harrington
- [3] Machine Learning with TensorFlow by Nishant Shukla
- [4] TensorFlow Machine Learning Cookbook by Nick McClure
- [5] Data Science from Scratch by Joel Grus
- [6] Hands-on Machine Learning with Scikit-Learn & TensorFlow by Aurélien Géron
History
- 21st April, 2019: Initial version

