Introduction
This article introduces a topic that I have taken an interest in, namely the National Information Exchange Model (NIEM) and the Information Exchange Package Documentation (IEPD). NIEM itself is interesting because it attempts to define an extensible standard for information exchange between various government agencies. An IEPD is the specific definition of this exchange for an information domain. Everything in the world of NIEM is based on XML and XSDs, and the specific schemas defined in an IEPD can be quite complex.
One of the things that is interesting about NIEM, and in particular the various IEPDs, is that they define much of the metadata that typically describes a data model:
- entities (XSD complex types)
- entity fields (XSD simple types)
- entity relationships (defined in XSD association elements)
- lookup data (defined in XSD facets)
However, there tends to be a mismatch between the schema defined in an IEPD and a typical relational data model (RDM); in fact, the same mismatch that appears between object oriented programming and an RDM. An XSD, through the use of extension tags, can be used to create a hierarchical data model (HDM), which does not necessarily map very easily to an RDM.
It is this mismatch, between hierarchical and relational models (otherwise known by the poorly chosen phrase "impedance mismatch"), that makes it difficult (and frankly, a solution specific to that RDM) to translate an existing RDM into the schema defined in an IEPD. But, what if the problem were to be worked backwards instead? What if, given the schema in an IEPD (granted, an HDM), one were to generate the RDM? And taking this further, what if one were to use the IEPD's HDM as guidance for the creation of the user interface (UI) to manage the data in the RDM?
The reader may be wondering at this point, why translate the HDM into an RDM? This is a good question and, if we were to use an object-oriented database management system (ODBMS)3, we could live within the context of a hierarchical data model. However, the reality is that most people and companies live in an RDM world, using either Oracle, SQL Server, or one of the popular open source relational database management systems. Granted, it's a weak argument to say "since everyone is using an RDM, we're not even going to look at an ODBMS". However, there is a more compelling argument. The reality is, you probably don't actually have the luxury to create a new RDM, and in fact will have to create a mapping between an existing RDM and an IEPD's schema. If you are so lucky as to have the opportunity to create a new RDM, then you are probably still faced with the challenge of data exchange with legacy RDMs still in use by legacy products. In either case, it seems we are going to live in the world of the RDM for a while longer.
Because I am less interested in the issues of mapping from an existing RDM to an IEPD, I am going to look specifically at what I consider to be the more interesting (and lucky) path of using the IEPD for guidance in generating the RDM and UI. However, I think, this will still be of interest to people having to map an existing RDM to an IEPD. Why? Because the IEPD defines entities, entity fields, and entity relationships that may not be completely modeled in an existing RDM. Even more important, the cardinality of the relationship (one-to-one vs. one-to-many) may result in some interesting difficulties in mapping data from an existing RDM to an IEPD, and vice-versa. For example, if your RDM defines that a person has three phone numbers (home, work, cell) but the IEPD defines that a person has a relationship to a phone number and the number has an extensible "type" field associated with it (home, work, cell, pager, fax, emergency, etc.), then you end up having to deal with mapping the more general IEPD data into a more restrictive (and possibly denormalized) RDM.
So, now that you hopefully understand my motivations for writing this article, and before concluding with the introduction, allow me quote directly from a couple web pages as to what is NIEM and what is an IEPD.
What is NIEM?
NIEM, the National Information Exchange Model, is a partnership of the U.S. Department of Justice and the Department of Homeland Security. It is designed to develop, disseminate, and support enterprise-wide information exchange standards and processes that can enable jurisdictions to effectively share critical information in emergency situations, as well as support the day-to-day operations of agencies throughout the nation.1
NIEM enables information sharing, focusing on information exchanged among organizations as part of their current or intended business practices. The NIEM exchange development methodology results in a common semantic understanding among participating organizations and data formatted in a semantically consistent manner. NIEM will standardize content (actual data exchange standards), provide tools, and manage processes.
What is an IEPD?
An IEPD, or Information Exchange Package Documentation, is a specification for a data exchange, and defines a particular data exchange. For example, there is an IEPD that defines the information content and structure for an Amber Alert, a bulletin or message sent by law enforcement agencies to announce the suspected abduction of a child...The artifacts in the NIEM IEPD specification are an extension of the work on IEPD guidelines done for the Global Justice XML Data Model, specifically Information Exchange Package Documentation Guidelines.2
Other Standards
Here are some other information exchange schemas one might find of interest:
As you can see, using schemas to provide public definitions of information exchange is not just something that the DoJ is doing, but is common in many industries. The schemas mentioned here are just the tip of the iceberg.
Mining an IEPD
I'm going to use the Department of Justice's (DoJ) Incident/Arrest IEPD (the download is at the very bottom of that page), focusing on an Incident to determine the entities and relationships to an Incident. First, we'll look at the entities in this IEPD.
Tools
I've been using Liquid XML Studio 2008 to inspect this schema. If you purchase this utility, you can use it to generate HTML documentation (under Tools, Generate Documentation...), which is extremely useful for navigating the IEPD. I would include the documentation here, but the zipped file is 42MB; however, you can download the documentation from my server here. There are other documentation tools like Innovasys Document X that appear to generate similar documentation, but I haven't tried it out. And, then of course, there is Altova's XmlSpy tool. Frank Kilkelly has what looks like a very nice free XSD viewer.
You can also search the NIEM schemas themselves online using the NIEM Tools website; however, this will not include schemas that extend the NIEM schemas.
Complex Types and Type Relationships
If you download the IEPD above, you will first note that it is daunting. The main N-Dex (National Data Exchange) XSD for the Incident/Arrest IEPD is located in the path: N-DEx-IncidentArrest-2.0.0\xsd\ndexia\ndexia\2.0.
Let's look first at a couple complex types in the schema to understand the general pattern of the type hierarchy so we can create an object graph of the hierarchy. Using the documentation generated by Liquid XML Studio 2008, note the seven different folders in the "Schema Documentation" panel on the left:

Opening the Complex Types folder, scroll down the types until you find "PersonType". Notice how there are several PersonTypes defined in the NIEM-core (nc) and one in the ndexia namespace.
We're interested in the one in the ndexia namespace.
Looking at the schema, note the complex content extension:
<xsd:complexType xmlns:xsd="http://www.w3.org/2001/XMLSchema" name="PersonType" >
...snip...
<xsd:complexContent mixed="false">
<xsd:extension base="nc:PersonType">
Looking at the NIEM-core PersonType, we see the same pattern:
xsd:complexType xmlns:xsd="http://www.w3.org/2001/XMLSchema" name="PersonType" >
...snip...
<xsd:complexContent mixed="false">
<xsd:extension base="s:ComplexObjectType">
in which the NIEM-core PersonType is an extension of the type ComplexObjectType. In fact, similar to how all C# objects are derived from Object, the NIEM types are all derived from either ComplexObjectType or SimpleObjectType.
If we look at another type, "AircraftType", using the documentation browser, notice the hierarchy (part of the documentation generated by Liquid XML):
By observing the extension base type of the complex content, we now have a pattern that can be used to generate an object graph of the complex types. I have done so by iterating through all the top-level elements in the IEPD and recursing through the extensions of the element types.
Some Basics - Load the Schema
The schema is loaded from the filename of the open file browser dialog:
public Iepd(string filename)
{
XmlTextReader xtr = new XmlTextReader(filename);
xsd = XmlSchema.Read(xtr, ValidationHandler);
xsdSet = new XmlSchemaSet();
xsdSet.Add(xsd);
xsdSet.Compile();
typeChildren = new Dictionary<QName, List<XmlSchemaType>>();
parentList = new Dictionary<QName, QName>();
}
It is necessary to add the schema to an XmlSchemaSet and to compile the schema set. The constructor also initializes a couple dictionaries used to generate the hierarchy. Admittedly, the code that generates the type object graph is a bit kludgy because I'm using two dictionaries!
Iterating Through Top Level Elements
The following code illustrates iterating through the top-level elements.
public void BuildTypeHierarchyFromElements()
{
foreach (DictionaryEntry de in xsd.Elements)
{
XmlSchemaElement xse = de.Value as XmlSchemaElement;
XmlSchemaType xst = xse.ElementSchemaType;
FindParent(xst);
}
}
Finding the Parent to a Type
The real work is in finding the parent of the complex type, as specified by a complex content that has an extension. The following code validates that the schema has all the pieces expected in the pattern we identified above for constructing the object graph.
protected void FindParent(XmlSchemaType xst)
{
if (xst is XmlSchemaComplexType)
{
XmlSchemaComplexType xsct = (XmlSchemaComplexType)xst;
if (xsct.ContentModel is XmlSchemaComplexContent)
{
XmlSchemaComplexContent xscc =
(XmlSchemaComplexContent)xsct.ContentModel;
if (xscc.Content is XmlSchemaComplexContentExtension)
{
XmlQualifiedName baseType =
((XmlSchemaComplexContentExtension)xscc.Content).BaseTypeName;
QName parentKey = new QName(baseType);
if (!typeChildren.ContainsKey(parentKey))
{
typeChildren[parentKey] = new List<XmlSchemaType>();
}
if (!typeChildren[parentKey].Contains(xst))
{
typeChildren[parentKey].Add(xst);
QName childQName = new QName(xst.QualifiedName);
parentList[childQName] = parentKey;
XmlSchemaType xstParent = FindType(xsd, baseType);
FindParent(xstParent);
}
}
}
}
}
The FindType method attempts to find the type in the parent schema, and if not found, recurses through the imported schemas until the schema with the correct namespace is found, indicating that the schema defines the desired type:
protected XmlSchemaType FindType(XmlSchema schema, XmlQualifiedName baseType)
{
XmlSchemaType xstParent = schema.SchemaTypes[baseType] as XmlSchemaType;
if (xstParent == null)
{
foreach (XmlSchemaImport import in schema.Includes)
{
if (import.Namespace == baseType.Namespace)
{
xstParent = import.Schema.SchemaTypes[baseType] as XmlSchemaType;
break;
}
else
{
xstParent = FindType(import.Schema, baseType);
if (xstParent != null)
{
break;
}
}
}
}
return xstParent;
}
Populating the Tree
Populating a TreeView of the type object graph requires finding all the types that do not have parents, then building the node list of each type for that parent, recursively. Granted, this is not totally intuitive, as the hierarchy of types that is created is sort of an intermediate structure, rather than a single dictionary in which the key has a collection of the same dictionary items for child types.
public void PopulateTree()
{
Dictionary<QName, List<XmlSchemaType>> h = iepd.TypeHierarchy;
foreach (KeyValuePair<QName, List<XmlSchemaType>> kvp in h)
{
if (!iepd.ParentList.ContainsKey(kvp.Key))
{
TreeNode tn;
tn = new TreeNode(kvp.Key.name);
tn.Tag = kvp.Key;
tnTypes.Nodes.Add(tn);
PopulateChildren(iepd, tn, kvp.Key);
}
}
tnTypes.ExpandAll();
}
protected void PopulateChildren(Iepd iepd, TreeNode tn, QName qname)
{
if (iepd.TypeHierarchy.ContainsKey(qname))
{
foreach (XmlSchemaType xst in iepd.TypeHierarchy[qname])
{
TreeNode tnChild = new TreeNode(xst.QualifiedName.Name);
tnChild.Tag = new QName(xst.QualifiedName);
tn.Nodes.Add(tnChild);
PopulateChildren(iepd, tnChild, new QName(xst.QualifiedName.Name,
xst.QualifiedName.Namespace));
}
}
}
The Result
The result is an object graph rendered in a tree. Note how the graph mirrors the complex content extension in an easy to understand hierarchy:
Attributes and Sub-Attribute Drilling
Let's look again at the complex type PersonType. Notice that the schema defined in the ndexia namespace for PersonType includes two "augmentations" (this, by the way, is another very common pattern in the NIEM and NIEM-derived schemas):
<xsd:complexContent mixed="false">
<xsd:extension base="nc:PersonType">
<xsd:sequence>
<xsd:element minOccurs="0" ref="j:PersonAugmentation"/>
<xsd:element minOccurs="0" ref="ndexia:PersonAugmentation"/>
</xsd:sequence>
</xsd:extension>
</xsd:complexContent>
where one of these elements is defined in the "justice" namespace and the other in the "ndexia" namespace. We want to be able to list all the elements of a particular type, and furthermore, to drill into these elements to view their sub-types, as illustrated by this screenshot for the PersonType type:
So, on the left of the IEPD Browser application is a tree view of the XSD type hierarchy, and selecting an item in that graph creates a tree view of the element hierarchy for that type. If we were to look at this in OOD terms, the left tree represents the "Is A" relationship between types, and the right tree represents the "Has A" items that each type contains. It should be fairly obvious that we could, given just this information, generate the classes and their properties to model the schema!
The following code shows how the elements are recursed to build the element graph:
protected void tnTypes_AfterSelect(object sender, TreeViewEventArgs e)
{
QName qname = (QName)e.Node.Tag;
tbNamespace.Text = qname.ns;
tvElements.Nodes.Clear();
List<ElementInfo> elInfoList = iepd.GetElements(qname);
TreeNode tnRoot = new TreeNode("Elements");
foreach (ElementInfo elInfo in elInfoList)
{
TreeNode tn = CreateElementRow(elInfo);
tnRoot.Nodes.Add(tn);
}
tvElements.Nodes.Add(tnRoot);
tnRoot.Expand();
}
protected TreeNode CreateElementRow(ElementInfo elInfo)
{
TreeNode tn = new TreeNode();
tn.Text = elInfo.Name + " (MinOccurs=" + elInfo.MinOccurs +
", MaxOccurs=" + elInfo.MaxOccurs +
", Type=" + elInfo.Type + ")";
if (elInfo.ChildElements.Count > 0)
{
foreach (ElementInfo ei in elInfo.ChildElements)
{
TreeNode tnChild = CreateElementRow(ei);
tn.Nodes.Add(tnChild);
}
}
return tn;
}
Of particular interest though is the GetElements method, which frankly is somewhat NIEM-pattern specific. As you will see from the code, there is a very specific pattern of qualifiers that determine the list of elements, as described here:
XmlSchemaType is XmlSchemaComplexType
-> ContentModel is XmlSchemaComplexContent
-> Content is XmlSchemaComplexContentExtension
-> Particle is XmlSchemaSequence
-> Items are XmlSchemaElement
-> ContentModel is XmlSchemaSimpleContent
-> Content is XmlSchemaSimpleContentExtension
The qualifier expects that the elements are part of a sequence in a complex content extension. While elements must be part of a sequence, they can also occur as part of the complex type, not just the complex content extension. However, since the NIEM model has all schema types derive from ComplexObjectType, the elements must be part of a sequence of the complex content extension; therefore, I believe the pattern described above is correct, at least for NIEM-based schemas.
public List<ElementInfo> GetElements(QName qname,
out XmlQualifiedName simpleContentType)
{
simpleContentType = null;
List<ElementInfo> elInfoList = new List<ElementInfo>();
XmlSchemaType xst = GetSchemaType(qname);
if (xst == null)
{
XmlSchemaElement xse = GetSchemaElement(qname);
xst = GetSchemaType(new QName(xse.SchemaTypeName));
}
if (xst is XmlSchemaComplexType)
{
XmlSchemaComplexType xsct = (XmlSchemaComplexType)xst;
if (xsct.ContentModel is XmlSchemaComplexContent)
{
XmlSchemaComplexContent xscc =
(XmlSchemaComplexContent)xsct.ContentModel;
if (xscc.Content is XmlSchemaComplexContentExtension)
{
XmlSchemaComplexContentExtension xscce =
(XmlSchemaComplexContentExtension)xscc.Content;
if (xscce.Particle is XmlSchemaSequence)
{
XmlSchemaSequence xss = (XmlSchemaSequence)xscce.Particle;
foreach (XmlSchemaObject xso in xss.Items)
{
if (xso is XmlSchemaElement)
{
XmlSchemaElement xse = (XmlSchemaElement)xso;
ElementInfo elInfo = new ElementInfo(xse, xse.MinOccursString,
xse.MaxOccursString, xse.RefName.Name, xse.SchemaType, xse.RefName);
if (xse.ElementSchemaType is XmlSchemaComplexType)
{
elInfo.DrillIntoType(this);
}
elInfoList.Add(elInfo);
}
}
}
}
}
else if (xsct.ContentModel is XmlSchemaSimpleContent)
{
XmlSchemaSimpleContent xssc =
(XmlSchemaSimpleContent)xsct.ContentModel;
if (xssc.Content is XmlSchemaSimpleContentExtension)
{
XmlSchemaSimpleContentExtension xssce =
(XmlSchemaSimpleContentExtension)xssc.Content;
simpleContentType = xssce.BaseTypeName;
}
}
}
return elInfoList;
}
Lookup Values
The Incident/Arrest schemas also include enumeration facets for lookup values, which consist of a documentation element that is a long description, and an enumeration value that is typically the "code". So, for example, "NY" is the code for the state "New York", which would be found in the documentation for that enumeration facet.
There are two basic patterns for finding an element's lookup values--one is drilling into the SimpleContentType of an element, the other is finding a substitutionGroup for the element.
Drilling into SimpleContentType
Looking at the ndexia:PersonAugmentation of the ndexia:PersonType, we find a variety of elements including PersonFacialHairCode:
<xsd:complexType name="PersonAugmentationType">
<xsd:complexContent>
<xsd:extension base="ndexia:AugmentationType">
<xsd:sequence>
[...snip...]
<xsd:element ref="ndexia:PersonFacialHairCode"
minOccurs="0" maxOccurs="unbounded"/>
[...snip...]
</xsd:sequence>
</xsd:extension>
</xsd:complexContent>
</xsd:complexType>
This element is defined as:
<xsd:element name="PersonFacialHairCode"
type="ndexiacodes:PersonFacialHairCodeType" nillable="true">
<xsd:annotation>
<xsd:documentation>A code that identifies the type
of facial hair the person has.</xsd:documentation>
</xsd:annotation>
</xsd:element>
The type PersonFacialHairCodeType is actually a simple type, which is the enumeration of facial hair codes:
<xsd:complexType name="PersonFacialHairCodeType">
[...snip...]
<xsd:simpleContent>
<xsd:extension base="ndexiacodes:PersonFacialHairCodeSimpleType">
<xsd:attributeGroup ref="s:SimpleObjectAttributeGroup"/>
</xsd:extension>
</xsd:simpleContent>
</xsd:complexType>
The ElementInfo class already contains the SimpleContentType XmlQualifiedName, so it becomes a "simple" matter of getting the documentation and values for the enumeration facets:
public List<EnumFacet> GetLookupData(ElementInfo elInfo)
{
List<EnumFacet> enums = new List<EnumFacet>();
if (elInfo.SimpleContentType != null)
{
XmlSchemaType xse = GetSchemaType(elInfo.SimpleContentType);
if (xse is XmlSchemaSimpleType)
{
XmlSchemaSimpleType xsst = xse as XmlSchemaSimpleType;
if (xsst.Content is XmlSchemaSimpleTypeRestriction)
{
XmlSchemaSimpleTypeRestriction xsstr =
xsst.Content as XmlSchemaSimpleTypeRestriction;
if (xsstr.Facets != null)
{
foreach (XmlSchemaObject xso in xsstr.Facets)
{
if (xso is XmlSchemaEnumerationFacet)
{
XmlSchemaEnumerationFacet xsef =
xso as XmlSchemaEnumerationFacet;
string doc = GetDocumentation(xsef.Annotation);
string val = xsef.Value;
enums.Add(new EnumFacet(val, doc));
}
}
}
}
}
}
return enums;
}
protected string GetDocumentation(XmlSchemaAnnotation xsa)
{
StringBuilder sb = new StringBuilder();
foreach (XmlSchemaObject xso in xsa.Items)
{
if (xso is XmlSchemaDocumentation)
{
XmlSchemaDocumentation xsd = xso as XmlSchemaDocumentation;
foreach (XmlNode xn in xsd.Markup)
{
sb.Append(xn.InnerText);
sb.Append("\r\n");
}
}
}
return sb.ToString();
}
And, the result is a list of codes and documentation that can be used as a pick list for the element. In this case, the codes and documentation are the same:
SubstitutionGroups
Another common pattern is the use of a schema substitutionGroup. We'll look at the NIEM-core PersonEthnicity that is part of the nc:PersonType:
<xsd:element name="PersonEthnicity" abstract="true">
[...snip...]
</xsd:element>
<xsd:element substitutionGroup="nc:PersonEthnicity"
name="PersonEthnicityCode" type="fbi:EthnicityCodeType" nillable="true">
[...snip...]
</xsd:element>
Here, we see that PersonEthnicityCode is a substitution group for PersonEthnicity, and the type comes from the fbi namespace, EthnicityCodeType, which then follows the simpleContentType pattern described above:
<xsd:complexType name="EthnicityCodeType">
[...snip...]
<xsd:simpleContent>
<xsd:extension base="fbi:EthnicityCodeSimpleType">
<xsd:attributeGroup ref="s:SimpleObjectAttributeGroup"/>
</xsd:extension>
</xsd:simpleContent>
</xsd:complexType>
So, to obtain the lookup data for a person's ethnicity, we have to check for an element that is a substitution group for our type. I rewrote the above method because both patterns have a common block of code to get the enumeration facets from the simple type:
public List<EnumFacet> GetLookupData(ElementInfo elInfo)
{
List<EnumFacet> enums = new List<EnumFacet>();
if (elInfo != null)
{
if (elInfo.SimpleContentType != null)
{
XmlSchemaType xse = GetSchemaType(elInfo.SimpleContentType);
if (xse is XmlSchemaSimpleType)
{
XmlSchemaSimpleType xsst = xse as XmlSchemaSimpleType;
GetLookupData(enums, xsst);
}
}
else
{
XmlQualifiedName elxqn = elInfo.RefName;
XmlSchemaElement xse = FindSubstitutionGroupElement(xsd, elxqn);
if (xse.ElementSchemaType is XmlSchemaComplexType)
{
XmlSchemaComplexType xsct =
xse.ElementSchemaType as XmlSchemaComplexType;
if (xsct.ContentModel is XmlSchemaSimpleContent)
{
XmlSchemaSimpleContent xssc =
xsct.ContentModel as XmlSchemaSimpleContent;
if (xssc.Content is XmlSchemaSimpleContentExtension)
{
XmlSchemaSimpleContentExtension xssce =
(XmlSchemaSimpleContentExtension)xssc.Content;
XmlQualifiedName xqn = xssce.BaseTypeName;
XmlSchemaType xse2 = GetSchemaType(xqn);
if (xse2 is XmlSchemaSimpleType)
{
XmlSchemaSimpleType xsst = xse2 as XmlSchemaSimpleType;
GetLookupData(enums, xsst);
}
}
}
}
}
}
return enums;
}
And now, we can get the enumeration facets when a schema substitution group is used to specify a new element type that has a simple content extension:
Yes, the FBI ethnicity enumeration is very simple--only three types.
A More Complex Example
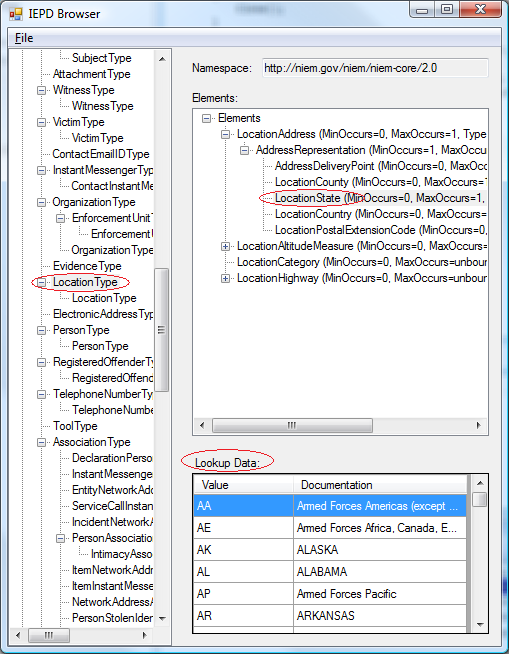
Let's look at what is required to drill into the elements of the ndexia:LocationType complex type, in order to eventually arrive at the LocationState element, which is a substitution group for type usps:USStateCodeType, which is a list of states!
First, let's figure out where the usps:USStateCodeType is used. Mining the schemas backwards, we find the following hierarchy:
ndexia:LocationType is an extension of nc:LocationType nc:LocationType has an element nc:LocationAddress nc:LocationAddress is of type nc:AddressType nc:AddressType has an element nc:AddressRepresentation nc:AddressRepresentation is the value of a substitutionGroup of type nc:StructuredAddressType nc:StructuredAddressType has an element nc:LocationState nc:LocationState is the value of a substitutionGroup of type usps:USStateCodeType
Notice that there are element hierarchies (think of this as a property that returns a class that is derived from some other class), and two substitution groups as well. Using the IEPD Browser, we can already get to the AddressRepresentation:
What is necessary now is to discover the element whose substitution group is the AddressRepresentation so we can drill into the elements of the StructuredAddressType:
<xsd:complexType name="StructuredAddressType">
[...snip...]
<xsd:complexContent>
<xsd:extension base="s:ComplexObjectType">
<xsd:sequence>
<xsd:element ref="nc:AddressDeliveryPoint" minOccurs="0" maxOccurs="2"/>
<xsd:element ref="nc:LocationCounty" minOccurs="0" maxOccurs="1"/>
<xsd:element ref="nc:LocationState" minOccurs="0" maxOccurs="1"/>
<xsd:element ref="nc:LocationCountry" minOccurs="0" maxOccurs="1"/>
<xsd:element ref="nc:LocationPostalExtensionCode" minOccurs="0" maxOccurs="1"/>
</xsd:sequence>
</xsd:extension>
</xsd:complexContent>
</xsd:complexType>
As can be seen from the above schema, there are elements in the complex content extension that should really be displayed in the Elements tree view. The first step is to refactor the code and build a substitution group dictionary. We do this so as to walk through the entire schema just once, then we can look up elements to see if they participate in a substitution group:
protected void BuildSubstitutionGroupDictionary(XmlSchema xsd)
{
foreach (XmlSchemaObject xso in xsd.Items)
{
if (xso is XmlSchemaElement)
{
XmlSchemaElement xse = xso as XmlSchemaElement;
if (xse.SubstitutionGroup != null)
{
substGroupMap[xse.SubstitutionGroup] = xse;
}
}
}
foreach (XmlSchemaImport import in xsd.Includes)
{
BuildSubstitutionGroupDictionary(import.Schema);
}
}
A minor modification to the GetElements method illustrated above allows us to locate the substitution group and continue building the element hierarchy:
[...code snippet...]
if (xse.ElementSchemaType is XmlSchemaComplexType)
{
elInfo.DrillIntoType(this);
XmlSchemaElement xseSubstGroup;
substGroupMap.TryGetValue(xse.QualifiedName, out xseSubstGroup);
if (xseSubstGroup != null)
{
elInfo.DrillIntoSubstGroup(this, xseSubstGroup);
}
}
elInfoList.Add(elInfo);
[...code snippet...].
The result is that the element list now drills into the substitution group, and we can pick up the state list:
Conclusion
In the final analysis, we (as individuals, corporations, local agencies, states, and governments) are moving more and more towards a world in which information must be exchanged across local, state, and national boundaries, and we need a mechanism for working with this data in a standard manner. NIEM and the IEPDs produced by various agencies such as the Department of Justice, as well as other public schemas by other agencies, are an important step in moving towards exchanging information in a defined manner.
I will continue this series of articles by looking next at how an IEPD provides guidance in generating classes that mirror the object graph, how these classes can map to a relational data model, and also how the IEPD provides guidance regarding the UI architecture (I will look especially at the schema's maxOccurs attribute for guidance on how to represent data).
History
1/2/2009
- Fixed problem with niem-core production release, stack overflow processing imports because they are circular.
- Fixed exception when facet documentation doesn't exist.
- Fixed bug where type tree wasn't being cleared when opening a new schema.
1/3/2009
- Substitution group map now allows for multiple substitution groups (see niem-core.xsd, EntityRepresentation type).
- Fixed circular drill into of elements, such as in niem-core, DNAType, ImageLocation, LocationType, ends up with EntityRepresentation that has several substitution groups.
Release 2 on 2/18/2009:
- Fixed problem with niem-core production release, stack overflow processing imports because they are circular.
- Fixed exception when facet documentation doesn't exist.
- Fixed bug where type tree wasn't being cleared when opening a new schema.
- Substitution group map now allows for multiple substitution groups (see niem-core.xsd, EntityRepresentation type).
- Fixed circular drill into of elements, such as in niem-core, DNAType, ImageLocation, LocationType, ends up with EntityRepresentation that has several substitution groups.
- Stopping circular references now uses the element type qualified name, not the element qualified name, as the element qualified name is often "specialized" whereas the type it references is common.
- Now pops "drilled into" element type qnames, because this was preventing sibling and higher level types from drilling into a type already encountered (we want to stop circular references only)
- Modified cardinality to use (n..m) format.
- Fixed: ex: DocumentType, DocumentFiledDate, should show Type=DateType, not DocumentFiledDate (we need the type of the ref)
- Fixed: DateRepresentation is abstract and has substitution groups of simple type. These now show up in the elements tree.
- Type hierarchy tree is now sorted.
- Changed hierarchy tree to iterate through all global complex types rather than starting with global elements and iterating through their types. This gives us a complete list of global types.
- Abstact types now show "anyType" for their type. For some reason, the IsAbstract flag isn't being set (see DateRepresentation)
- For simple type substitution groups, now nulls out the simpleContentType after setting the simple type substitution group. This fixes a problem with showing the wrong type name in the tree.
- Element browser now drills into child elements when the node is expanded. This greatly improves the performance of the UI, as some of these types of very extensive element trees.
- Fixed LocationType/.../LocationState: there are 9 substitution groups. Now shows the correct code list for the simple type of the substitution group.
References

