The previous article, part 7, in this series on portable
parallelism with OpenCL™ demonstrated how to create C/C++ plugins that can be dynamically loaded at runtime to add
massively parallel OpenCL™ capabilities to an already running application.
Developers who understand how to use OpenCL in a dynamically loaded runtime
environment have the ability to create plugins that accelerate the performance
of existing applications by an order of magnitude or more – simply by writing a
new plugin that uses OpenCL.
This article will demonstrate how to incorporate OpenCL into
heterogeneous workflows via a general-purpose "click together tools" framework that
can stream arbitrary messages (vectors, arrays, and arbitrary, complex nested structures)
within a single workstation, across a network of machines, or within a cloud
computing framework. The ability to create scalable workflows is important
because data handling and transformation can be as complex and time consuming as
the computational problem used to generate a desired result. My production
version of the framework described in this tutorial has successfully integrated
multiple supercomputers and numerous computation nodes into a single unified
workflow in both commercial and research environments.
For generality, this tutorial
uses the freely downloadable Google
protobufs (Protocol Buffers) package so readers can easily extend the
example codes to operate on their own data structures. Google protobufs provides
binary interoperability across machines and the ability to incorporate
applications written in C/C++, Python, Java, R and many other languages into
their workflows. Used in everyday computing at Google, protobufs are production
hardened. Google also claims this binary format provides a 20 to 100–times
increase in performance over XML.
Google protobufs in a click-together framework
For many applications,
preprocessing the data can be as complicated and time consuming as the actual computation
that generates the desired results. "Click together tools" is a common design
pattern that enables flexible and efficient data workflows by creating a
pipeline of applications to process information. Each element in the pipeline
reads data from an input (usually stdin), performs some filtering or
transformation operation, and writes the result to the output (usually stdout).
Information flows through these pipelines as packets of information comprised
of streams of bytes. All elements in a "click-together" pipeline have the
ability to read a message (sometimes called a packet of information) and write
it to an output. Based on the type of the packet of information, elements in
the pipeline can decide to operate on the data or just pass it along to other
elements in the pipeline.
A "click together" framework naturally exploits the
parallelism of multi-core processors because each element in the pipeline is a
separate application. The operating system scheduler ensures that any
applications that have the data necessary to perform work will run – generally
on separate processor cores. Buffering between applications allows very large
data sets to be processed on the fly. Similarly, the parallelism of multiple
machines can be exploited by piping data across machines with ssh, socat, or equivalent socket-based
applications or libraries.
Scalable, high-performance workflows can be constructed by tying
together multiple machines across a network or in the cloud. Component and
plugin reuse reduces errors as most workflows can be constructed from existing
"known working" applications. The flexibility of dynamic runtime loading allows
OpenCL to be used as a high-performance, massively parallel scripting language to
create and implement new workflows. Highly complex multi-stream work flows can
be easily constructed using a load-balancing split operation based on simple
socket based programming techniques like select() or poll() to
determine when a stream is ready for more data. One possible workflow showing
the use of multi-core processors and multiple GPUs within a system and across a
network is represented in the following figure.
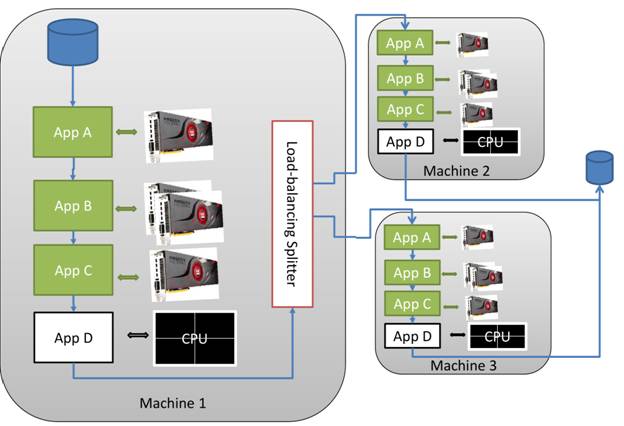
Figure 1: Example workflow
Keep in mind that each stream of information can be written
out to disk as an archive of the work performed, to checkpoint results, or to
use as the input deck for a later application.
Experience gained from decades of using this click-together
framework has shown that each packet of information needs to be preceded by a header
similar to the one shown below:
| Version number | Size (in bytes) of packet | Packet Type ID | Size (in bytes) of packet |
Figure 2: Example header
It is important that the header include a version number as
it allows libraries to transparently select the correct formatting and serialization methods.
For example, data streams that I saved to disk in the early 1980s at Los Alamos
National Laboratory are still usable today. For robustness, it is necessary to
duplicate the size of the packet to detect "silent" transmission errors.
Otherwise, bit-errors in the packet size can cause bizarre failures as an
application may suddenly attempt to allocate 232 or 264
bytes of memory (depending on the number of bits used to store the size). I
have seen such errors when preprocessing data sets on clusters of machines when
the processing takes many weeks to complete. Machine failures can cause
successful transmission of bogus information across a TCP network.
The redundancy in the size information provides a high
likelihood that bit rot in
persistent streams will be found. Some disk subsystems, especially inexpensive
ones, are susceptible to bit rot caused by multi-bit data errors. So long as
the size is correctly known, the packet information can be properly loaded into
memory where other more extensive checks or error recovery can occur. Even if
that particular packet is corrupt, the remaining packets in the stream can be
correctly loaded so all is not lost.
Following is a simple definition of a header that can be adapted
to a variety of languages
struct simpleHeader {
uint64_t version, size1, packetID, size2;
}
Example 1: Header structure
Each application, regardless of language, must be able to
read and understand this header. The application programmer can decide what to
do with each packet of information. At the very least, the programmer can just
pass on the packet of information without affecting the packet contents, or to
discard the packet and remove it from the data stream. Regardless, all header
data is transferred between applications in binary format using network
standard byte order so that arbitrary machine architectures can be used. The
type of streaming protocol has run successfully on most machines sold since the
mid-1980s.
The following pseudo-code describes how to read and write
one or more packets of information. For clarity, this pseudo code does check
that every I/O operation was successful. Actual production code needs to be
very strict about checking every operation.
while ( read the binary header information == SUCCESS)
{
• Compare header sizes (a mismatch flags an unrecoverable error)
• Allocate size bytes (after converting from network standard byte order)
• Binary read of size bytes into the allocated memory.
• Binary write the header in network standard byte order
• Binary write the packet information
}
Example 2: pseudo code showing how to use protobufs in a
stream
Most users will utilize a common
data interchange format for the packet data. By appropriately specifying the
type of the packet in the header, proprietary and special high-performance
formats can also be mixed into any data stream. Whenever possible, binary data
should be used for performance reasons. As previously mentioned, this tutorial
uses Google Protocol Buffers (protobufs)
because they are a well-supported free binary data interchange format that is
fast, well-tested, and robust. Google uses protobufs for most of their internal
RPC protocols and file formats. Code for a variety of destination languages can
be generated from a common protobuf description. Generators exist for many
common languages including C, C++, Python, Java, Ruby, PHP, Matlab, Visual
Basic and others. I have used protobufs on workstations and supercomputers.
The following protobuf specification demonstrates how to
describe messages containing vectors of various types. For simplicity only floating-point
and double precision vectors are defined.
package tutorial;
enum Packet {
UNKNOWN=0;
PB_VEC_FLOAT=1;
PB_VEC_DOUBLE=2;
PB_VEC_INT=3;
}
message FloatVector {
repeated float values = 1 [packed = true];
optional string name = 2;
}
message DoubleVector {
repeated float values = 1 [packed = true];
optional string name = 2;
}
Example 3: tutorial.proto
The .proto file is compiled to a destination source
language with the protoc source language generator. Following is the command
to generate a C++ source package using tutorial.proto. The protoc
compiler will also generate Java and Python source packages. Consult the protobuf website for links to
source generators for other languages.
protoc --cpp_out=.
tutorial.proto
Example 4: protoc command to generate C++ code
Linux users can install protobufs from the application
manager such as "apt-get" under Ubuntu. Cygwin and Windows users will
need to download and install protobufs from code.google.com. Google provides
Visual Studio solutions to help with building the code generator and libraries.
The following file packetheader.h contains the
methods to read and write the header and packet information in a stream
containing multiple protobuf messages. For generality, note that the message
type is defined via the enum in the .proto file. Your own message
packets can be utilized by adding to these definitions.
For brevity, many essential checks have been left out of packetheader.h.
C++ purists will note that cin and cout are changed to support
binary information in the method setPacket_binaryIO(). This was done for
convenience as it allows the use of operating system pipes (denoted with ‘|’) to
easily "click together" applications. While not part of the C++ standard, most C++
runtime systems support binary I/O on std::cin and std::cout. Those
C++ programmers who object to this practice can either (1) change the scripts
to manually specify the FIFOs (First-In First-Out queues) and network
connections so they can use binary I/O according to the C++ standard, or (2)
use the C language. Windows programmers will note that packetheader.h uses
the Microsoft provided _setmode()
method to perform binary IO.
#ifndef PACKET_HEADER_H
#define PACKET_HEADER_H
#ifdef _WIN32
#include <stdio.h>
#include <fcntl.h>
#include <io.h>
#include <stdint.h>
#include <Winsock2.h>
#else
#include <arpa/inet.h>
#endif
static const uint32_t version=1;
inline bool setPacket_binaryIO()
{
#ifdef _WIN32
if(_setmode( _fileno(stdin), _O_BINARY) == -1)
return false;
if(_setmode( _fileno(stdout), _O_BINARY) == -1)
return false;
#endif
return true;
}
inline bool writePacketHdr (uint32_t size, uint32_t type, std::ostream *out)
{
size = htonl(size);
type = htonl(type);
out->write((const char *)&version, sizeof(uint32_t));
out->write((const char *)&size, sizeof(uint32_t));
out->write((const char *)&type, sizeof(uint32_t));
out->write((const char *)&size, sizeof(uint32_t));
return true;
}
template <typename T>
bool writeProtobuf(T &pb, uint32_t type, std::ostream *out)
{
writePacketHdr(pb.ByteSize(), type, out);
pb.SerializeToOstream(out);
return true;
}
inline bool readPacketHdr (uint32_t *size, uint32_t *type, std::istream *in)
{
uint32_t size2, myversion;
in->read((char *)&myversion, sizeof(uint32_t)); myversion = ntohl(myversion);
if(!in->good()) return(false);
in->read((char *)size, sizeof(uint32_t)); *size = ntohl(*size);
if(!in->good()) return(false);
in->read((char *)type, sizeof(uint32_t)); *type = ntohl(*type);
if(!in->good()) return(false);
in->read((char *)&size2, sizeof(uint32_t)); size2 = ntohl(size2);
if(!in->good()) return(false);
if(*size != size2) return(false);
return(true);
}
template <typename T>
bool readProtobuf(T *pb, uint32_t size, std::istream *in)
{
char *blob = new char[size];
in->read(blob,size);
bool ret = pb->ParseFromArray(blob,size);
delete [] blob;
return ret;
}
#endif
The program testWrite.cc
demonstrates how to create and write both double and float vector
messages. The default vector length is 100 elements. Larger messages can be
created by specifying a size on the command-line.
#include <iostream>
using namespace std;
#include "tutorial.pb.h"
#include "packetheader.h"
int main(int argc, char *argv[])
{
GOOGLE_PROTOBUF_VERIFY_VERSION;
int vec_len = 100;
if(argc > 1) vec_len = atoi(argv[1]);
if(!setPacket_binaryIO()) return -1;
tutorial::FloatVector vec;
for(int i=0; i < vec_len; i++) vec.add_values(i);
tutorial::DoubleVector vec_d;
for(int i=0; i < 2*vec_len; i++) vec_d.add_values(i);
vec.set_name("A");
writeProtobuf<tutorial::FloatVector>(vec, tutorial::PB_VEC_FLOAT,
&std::cout);
vec_d.set_name("B");
writeProtobuf<tutorial::DoubleVector>(vec_d, tutorial::PB_VEC_DOUBLE,
&std::cout);
return(0);
}
Example 6: testWrite.cc
The program testRead.cc demonstrates how to read the header
and messages via a stream. The string associated with the optional name in the
protobuf message is printed when provided.
#include <iostream>
#include "packetheader.h"
#include "tutorial.pb.h"
using namespace std;
int main(int argc, char *argv[])
{
GOOGLE_PROTOBUF_VERIFY_VERSION;
if(!setPacket_binaryIO()) return -1;
uint32_t size, type;
while(readPacketHdr(&size, &type, &std::cin)) {
switch(type) {
case tutorial::PB_VEC_FLOAT: {
tutorial::FloatVector vec;
if(!readProtobuf<tutorial::FloatVector>(&vec, size, &std::cin))
break;
if(vec.has_name() == true) cerr << "vec_float " << vec.name() << endl;
cerr << vec.values_size() << " elements" << endl;
} break;
case tutorial::PB_VEC_DOUBLE: {
tutorial::DoubleVector vec;
if(!readProtobuf<tutorial::DoubleVector>(&vec, size, &std::cin))
break;
if(vec.has_name() == true) cerr << "vec_double " << vec.name() << endl;
cerr << vec.values_size() << " elements" << endl;
} break;
default:
cerr << "Unknown packet type" << endl;
}
}
return(0);
}
Example 7: testRead.cc
These applications can be built and tested under Linux with
the following commands:
g++ -I . testWrite.cc tutorial.pb.cc -l protobuf -o testWrite -lpthread
g++ -I . testRead.cc tutorial.pb.cc -l protobuf -o testRead -lpthread
echo "----------- simple test -----------------"
./testWrite | ./testRead
Example 8: Linux build and test commands
bda$ sh BUILD.linux
----------- simple test -----------------
vec_float A
100 elements
vec_double B
200 elements
Example 9: Output of Linux commands
A Click-Together Framework
Combining the previous dynamic compile/link and protobuf examples
yields the powerful "click together" framework discussed earlier in this
article.
Following is the complete source for dynFunc.cc,
which combines the streaming of protobuf messages and the dynamic compilation
of C/C++ methods.
For flexibility, the init(), func(), and fini()
methods have the ability to modify or create new messages that can be passed
onto other applications in the click-together framework. It is the
responsibility of the plugin author to create a char array that will
hold the modified protobuf message. A dynFree() method was added so the
plugin author can free the memory region. This makes the plugin framework
language agnostic. For example, C source code would use malloc()/free()
while C++ source code would use new/delete .
Each method can return a pointer to a character array that contains
a modified message that is to be written out. Returning NULL implies no
message need be written. The plugin author can pass on the original message by
returning the message pointer. In this case, dynFree() is not called
because the plugin framework performed the allocation.
#include <cstdlib>
#include <sys/types.h>
#include <dlfcn.h>
#include <string>
#include <iostream>
#include "packetheader.h"
using namespace std;
void *lib_handle;
typedef char* (*initFini_t)(const char*, const char*, uint32_t*, uint32_t*);
typedef char* (*func_t)(const char*, const char*, uint32_t*, uint32_t*, char*);
typedef void (*dynFree_t)(char*);
int main(int argc, char **argv)
{
if(argc < 2) {
cerr << "Use: sourcefilename" << endl;
return -1;
}
string base_filename(argv[1]);
base_filename = base_filename.substr(0,base_filename.find_last_of("."));
string buildCommand("g++ -fPIC -shared ");
buildCommand += string(argv[1])
+ string(" -o ") + base_filename + string(".so ");
cerr << "Compiling with \"" << buildCommand << "\"" << endl;
if(system(buildCommand.c_str())) {
cerr << "compile command failed!" << endl;
cerr << "Build command " << buildCommand << endl;
return -1;
}
string nameOfLibToLoad("./");
nameOfLibToLoad += base_filename;
nameOfLibToLoad += ".so";
lib_handle = dlopen(nameOfLibToLoad.c_str(), RTLD_LAZY);
if (!lib_handle) {
cerr << "Cannot load library: " << dlerror() << endl;
return -1;
}
initFini_t dynamicInit= NULL;
func_t dynamicFunc= NULL;
initFini_t dynamicFini= NULL;
dynFree_t dynamicFree= NULL;
dlerror();
dynamicFunc= (func_t) dlsym(lib_handle, "func");
const char* dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
dynamicInit= (initFini_t) dlsym(lib_handle, "init");
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
dynamicFini= (initFini_t) dlsym(lib_handle, "fini");
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
dynamicFree= (dynFree_t) dlsym(lib_handle, "dynFree");
if (!setPacket_binaryIO()) {
cerr << "Cannot set binary mode for cin and cout!" << endl;
return -1;
}
uint32_t size, type;
char *retBlob;
if( (retBlob=(*dynamicInit)(argv[0], base_filename.c_str(),&size, &type)) ) {
writePacketHdr(size, type, &std::cout);
cout.write(retBlob, size);
(dynamicFree)(retBlob);
}
while(readPacketHdr(&size, &type, &std::cin)) {
char *blob = new char[size];
cin.read(blob, size);
retBlob =(*dynamicFunc)(argv[0], base_filename.c_str(), &size, &type, blob);
if(retBlob) {
writePacketHdr(size, type, &std::cout);
cout.write(retBlob, size);
if(retBlob != blob) (dynamicFree)(retBlob);
}
delete [] blob;
}
if( retBlob = (*dynamicFini)(argv[0], base_filename.c_str(),&size, &type) ) {
writePacketHdr(size, type, &std::cout);
cout.write(retBlob, size);
(dynamicFree)(retBlob);
}
dlclose(lib_handle);
return 0;
}
Example 10: dynFunc.cc
The source for passthrough.cc is included below. This
plugin simply passes all messages along to the next application in the pipeline.
Linux users will note the g++ command includes use of the –rdynamic option,
which tells the linker to check the executable for any unresolved symbols. (While
Visual Studio code is not provided in this tutorial, it is important that
Visual Studio users specify a #pragma comment() to inform the linker
about needed libraries. In this way the protobuf methods can be linked with the
plugin.)
#include <stdlib.h>
#include <stdint.h>
#include <iostream>
#include "tutorial.pb.h"
using namespace std;
extern "C" char* init(const char* progname, const char* sourcename,
uint32_t *size, uint32_t *type) {
return(NULL);
}
extern "C" char* func(const char* progname, const char* sourcename,
uint32_t *size, uint32_t *type, char *blob)
{
return(blob); }
extern "C" char* fini(const char* progname, const char* sourcename,
uint32_t *size, uint32_t *type) {
return(NULL);
}
extern "C" void dynFree(char* pt) {
cerr << "dynFree" << endl;
if(pt) delete [] pt;
}
Example 11: passthrough.cc
The following source file, reduction.cc, demonstrates
how to use init() and fini() to calculate the sum of either a float
or double protobuf vector message on the host.
#include <stdlib.h>
#include <stdint.h>
#include <iostream>
#include "tutorial.pb.h"
using namespace std;
extern "C" char* init(const char* progname, const char* sourcename,
uint32_t *size, uint32_t *type) {
return(NULL);
}
extern "C" char* func(const char* progname, const char* sourcename,
uint32_t *size, uint32_t *type, char *blob)
{
switch(*type) {
case tutorial::PB_VEC_FLOAT: {
tutorial::FloatVector vec;
if(!vec.ParseFromArray(blob,*size)) {
cerr << progname << "," << sourcename << "Illegal packet" << endl;
} else {
if(vec.has_name() == true) cerr << "vec_float " << vec.name() << " ";
float sum=0.f;
for(int i=0; i < vec.values_size(); i++) sum += vec.values(i);
cerr << "sum of vector " << sum << endl;
cerr << "\tlast value in vector is " << vec.values(vec.values_size()-1)
<< endl;
cerr << "\tvector size is " << vec.values_size() << endl;
}
} break;
case tutorial::PB_VEC_DOUBLE: {
tutorial::DoubleVector vec;
if(!vec.ParseFromArray(blob,*size)) {
cerr << progname << "," << sourcename << "Illegal packet" << endl;
} else {
if(vec.has_name() == true) cerr << "vec_double " << vec.name() << " ";
double sum=0.;
for(int i=0; i < vec.values_size(); i++) sum += vec.values(i);
cerr << "sum of vector " << sum << endl;
cerr << "\tlast value in vector is " << vec.values(vec.values_size()-1)
<< endl;
cerr << "\tvector size is " << vec.values_size() << endl;
}
} break;
default:
cerr << "Unknown packet type" << endl;
}
return(NULL);
}
extern "C" char* fini(const char* progname, const char* sourcename,
uint32_t *size, uint32_t *type) {
return(NULL);
}
extern "C" void dynFree(char* pt) {
if(pt) delete [] pt;
}
Example 12: reduction.cc
Using OpenCL in a Click Together Framework
The source code for dynFunc.cc is easily modified to
include the code needed to parse the device type (either CPU or GPU) and to add
a call to a new method, oclSetupFunc(), which passes the OpenCL context
and name of the kernel source file to the plugin. The plugin can then build
the OpenCL source code and call the OpenCL kernels in the init(),
func()
, and
fini() methods. Changes to the code are
highlighted in bold font in source for
oclFunc.cc below.
#include <cstdlib>
#include <sys/types.h>
#include <dlfcn.h>
#include <string>
#include <iostream>
#include "packetheader.h"
#define PROFILING // Define to see the time the kernel takes
#define __NO_STD_VECTOR // Use cl::vector instead of STL version
#define __CL_ENABLE_EXCEPTIONS // needed for exceptions
#include <CL/cl.hpp>
#include <fstream>
using namespace std;
void *lib_handle;
typedef char* (*initFini_t)(const char*, const char*, uint32_t*, uint32_t*);
typedef char* (*func_t)(const char*, const char*, uint32_t*, uint32_t*, char*);
typedef void (*dynFree_t)(char*);
typedef void (*oclSetup_t)(const char*, cl::CommandQueue*);
int main(int argc, char **argv)
{
if(argc < 3) {
cerr << "Use: sourcefilename cpu|gpu oclSource" << endl;
return -1;
}
string base_filename(argv[1]);
base_filename = base_filename.substr(0,base_filename.find_last_of("."));
string buildCommand("g++ -fPIC -shared -I $AMDAPPSDKROOT/include ");
buildCommand += string(argv[1])
+ string(" -o ") + base_filename + string(".so ");
cerr << "Compiling with \"" << buildCommand << "\"" << endl;
if(system(buildCommand.c_str())) {
cerr << "compile command failed!" << endl;
cerr << "Build command " << buildCommand << endl;
return -1;
}
string nameOfLibToLoad("./");
nameOfLibToLoad += base_filename;
nameOfLibToLoad += ".so";
lib_handle = dlopen(nameOfLibToLoad.c_str(), RTLD_LAZY);
if (!lib_handle) {
cerr << "Cannot load library: " << dlerror() << endl;
return -1;
}
initFini_t dynamicInit= NULL;
func_t dynamicFunc= NULL;
initFini_t dynamicFini= NULL;
dynFree_t dynamicFree= NULL;
dlerror();
dynamicFunc= (func_t) dlsym(lib_handle, "func");
const char* dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
dynamicInit= (initFini_t) dlsym(lib_handle, "init");
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
dynamicFini= (initFini_t) dlsym(lib_handle, "fini");
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
dynamicFree= (dynFree_t) dlsym(lib_handle, "dynFree");
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
oclSetup_t oclSetupFunc;
oclSetupFunc = (oclSetup_t) dlsym(lib_handle, "oclSetup");
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
const string platformName(argv[2]);
const char* oclKernelFile = argv[3];
int ret= -1;
cl::vector<int> deviceType;
cl::vector< cl::CommandQueue > contextQueues;
if(platformName.compare("cpu")==0)
deviceType.push_back(CL_DEVICE_TYPE_CPU);
else if(platformName.compare("gpu")==0)
deviceType.push_back(CL_DEVICE_TYPE_GPU);
else { cerr << "Invalid device type!" << endl; return(1); }
try {
cl::vector< cl::Platform > platformList;
cl::Platform::get(&platformList);
cl::vector<cl::Device> devices;
for(int i=0; i < deviceType.size(); i++) {
cl::vector<cl::Device> dev;
platformList[0].getDevices(deviceType[i], &dev);
for(int j=0; j < dev.size(); j++) devices.push_back(dev[j]);
}
cl_context_properties cprops[] = {CL_CONTEXT_PLATFORM, NULL, 0};
cl::Context context(devices, cprops);
cerr << "Using the following device(s) in one context" << endl;
for(int i=0; i < devices.size(); i++) {
cerr << " " << devices[i].getInfo<CL_DEVICE_NAME>() << endl;
}
for(int i=0; i < devices.size(); i++) {
#ifdef PROFILING
cl::CommandQueue queue(context, devices[i],CL_QUEUE_PROFILING_ENABLE);
#else
cl::CommandQueue queue(context, devices[i],0);
#endif
contextQueues.push_back( queue );
}
} catch (cl::Error error) {
cerr << "caught exception: " << error.what()
<< '(' << error.err() << ')' << endl;
return(-1);
}
oclSetupFunc(oclKernelFile, &contextQueues[0]);
if (!setPacket_binaryIO()) {
cerr << "Cannot set binary mode for cin and cout!" << endl;
return -1;
}
uint32_t size, type;
char *retBlob;
if( (retBlob=(*dynamicInit)(argv[0], base_filename.c_str(),&size, &type)) ) {
writePacketHdr(size, type, &std::cout);
cout.write(retBlob, size);
(dynamicFree)(retBlob);
}
while(readPacketHdr(&size, &type, &std::cin)) {
char *blob = new char[size];
cin.read(blob, size);
retBlob =(*dynamicFunc)(argv[0], base_filename.c_str(), &size, &type, blob);
if(retBlob) {
writePacketHdr(size, type, &std::cout);
cout.write(retBlob, size);
if(retBlob != blob) (dynamicFree)(retBlob);
}
delete [] blob;
}
if( retBlob = (*dynamicFini)(argv[0], base_filename.c_str(),&size, &type) ) {
writePacketHdr(size, type, &std::cout);
cout.write(retBlob, size);
(dynamicFree)(retBlob);
}
dlclose(lib_handle);
return 0;
}
The following OpenCL kernel adds each element in the vector to
itself on the device. The resulting vector is then passed on to the next
application in the pipeline. Note, the number of copies was not optimized in
this example.
inline __kernel void init(int veclen, __global TYPE1* c, int offset)
{
}
inline __kernel void func(int veclen, __global TYPE1* c, int offset)
{
int index = get_global_id(0);
c[index + offset*veclen] += c[index + offset*veclen];
}
inline __kernel void fini(int veclen, __global TYPE1* c, int offset)
{
}
Example 14: simpleAdd.cl source that adds the elements in a
vector to itself
The following commands are used to build and run some tests
under Linux:
gcc -rdynamic -o dynFunc dynFunc.cc tutorial.pb.cc -l protobuf -ldl -lpthread
gcc -I $AMDAPPSDKROOT/include -rdynamic -o dynOCL dynOCL.cc tutorial.pb.cc -L $AMDAPPSDKROOT/lib/x86_64 -lOpenCL -lprotobuf -ldl -lpthread
echo "--------------- showing a dynamic reduction ----------------------------"
./testWrite | ./dynFunc reduction.cc
echo "---------------- Pass through demo -------------------------------"
./testWrite | ./dynFunc passthrough.cc \
| ./dynFunc reduction.cc
echo "------------- the float vector contains values*4 -----------------------"
# increase the float vector by a factor of four
./testWrite \
| ./dynOCL oclFunc.cc cpu simpleAdd.cl \
| ./dynOCL oclFunc.cc gpu simpleAdd.cl \
| ./dynFunc reduction.cc
Example 15: Linux commands to build and test the examples
These commands generated the following output under Linux.
Note the OpenCL plugin that uses simpleAdd.cl is called twice in the
last test to increase the value of the floating-point vector values by a factor
of four as shown in bold font below. This example demonstrates that OpenCL
plugins can be chained together. In addition, the first use of simpleAdd.cl
runs on the CPU and the second runs on a GPU.
$: sh BUILD.linux
--------------- showing a dynamic reduction ----------------------------
Compiling with "g++ -fPIC -shared reduction.cc -o reduction.so "
vec_float A sum of vector 4950
last value in vector is 99
vector size is 100
vec_double B sum of vector 19900
last value in vector is 199
vector size is 200
---------------- Pass through demo -------------------------------
Compiling with "g++ -fPIC -shared passthrough.cc -o passthrough.so "
Compiling with "g++ -fPIC -shared reduction.cc -o reduction.so "
vec_float A sum of vector 4950
last value in vector is 99
vector size is 100
vec_double B sum of vector 19900
last value in vector is 199
vector size is 200
------------- the float vector contains values*4 -----------------------
Compiling with "gcc -fPIC -shared -I $AMDAPPSDKROOT/include oclFunc.cc -o oclFunc.so "
Compiling with "g++ -fPIC -shared reduction.cc -o reduction.so "
Compiling with "gcc -fPIC -shared -I $AMDAPPSDKROOT/include oclFunc.cc -o oclFunc.so "
Using the following device(s) in one context
AMD Phenom(tm) II X6 1055T Processor
building OCL source (simpleAdd.cl)
buildOptions -D TYPE1=float
Using the following device(s) in one context
Cypress
building OCL source (simpleAdd.cl)
buildOptions -D TYPE1=float
dynFree
dynFree
vec_float A sum of vector 19800
last value in vector is 396
vector size is 100
vec_double B sum of vector 19900
last value in vector is 199
vector size is 200
Example 16: Output of the Linux commands and tests
Summary
With the ability to create OpenCL plugins, application
programmers have the ability to write and support generic applications that
will deliver accelerated performance when a GPU is present and CPU-based
performance when a GPU is not available. These plugin architectures are
well-understood and a convenient way to leverage existing applications and code
bases. They also help preserve existing software investments.
The ability to dynamically compile OpenCL plugins opens a
host of opportunities for optimizing code generators and transparently running
a single OpenCL application on multiple device back ends. With this technique, OpenCL
applications can deliver optimized code for specific problems and achieve very
high performance – far beyond what a single generic code can deliver. As OpenCL
matures, these applications will also transparently benefit from any compiler
and other performance improvements.
The workflow example in this article demonstrates how to use
OpenCL to exploit hybrid CPU/GPU computation. Incorporating OpenCL into the
flexibility, robustness, scalability, and performance of "click together"
pipeline workflows gives programmers the ability to capitalize on GPU
acceleration and CPU capabilities in their production workflows.

