The previous article, part 8, in this series on portable
parallelism with OpenCL™ demonstrated how to incorporate OpenCL™ into
heterogeneous workflows via a general-purpose "click-together tools" framework that
can stream arbitrary messages (vectors, arrays, and arbitrary, complex nested structures)
within a single workstation, across a network of machines, or within a cloud
computing framework. The ability to create scalable workflows is important
because data handling and transformation can be as complex and time consuming as
the computational problem used to generate the desired result.
This article discusses OpenCL extensions that provide programmers
with additional capabilities such as double-precision arithmetic and Device Fission.
(Device Fission provides an interface to subdivide a single OpenCL device into
multiple devices – each with a separate asynchronous command queues.)
OpenCL extensions can be defined by a vendor, a subset of
the OpenCL working group, or by the entire OpenCL working group. The most
portable extensions are those defined by the KHR extensions that are formally
approved by the entire OpenCL working group while vendor extensions are the
least portable and likely to be tied to a particular device or product line. Regardless
of who provides the definition, no guarantee is made that an extension will be
available on any platform.
Following are the three types of OpenCL extensions and
naming conventions:
- KHR extension: A KHR extension is formally ratified by the OpenCL
working group and comes with a set of conformance tests to help ensure
consistent behavior. KHR extensions are provided to support capabilities
available on some but not all OpenCL devices. The Microsoft DirectX extension
is one example of an important capability that is only available on devices
that support Microsoft Windows. A KHR extension has a unique name of the form cl_khr_<name>.
- EXT extension: An EXT extension is developed by one or more of
the OpenCL working group members. No conformance tests are required. It is
reasonable to think of these as "work in process" extensions to assess usability,
value, and portability prior to formal approval as a KHR extension. An EXT
extension has a unique name of the form cl_ext_<name>.
- Vendor extension: These extensions are provided by a vendor to
expose features specific to a vendor device or product line. Vendor extensions
should be considered as highly non-portable. The AMD device attribute query is
one example that provides additional information about AMD devices. Vendor
extensions are assigned a unique name of the form cl_<vendor>_<name>.
Thus an AMD extension would have a name string cl_amd_<name>.
The #pragma OPENCL EXTENSION directive controls the
behavior of the OpenCL compiler to allow or disallow extension(s). For example,
part
4 of this series enabled double-precision computation on AMD devices with
the following line. (Note cl_amd_fp64 can be updated to cl_khr_fp64
in the 2.6 AMD SDK release.)
#pragma OPENCL EXTENSION cl_amd_fp64 : enable
Example 1: Pragma to enable double-precision from part 4 of this series
The syntax of the extension pragma is:
#pragma OPENCL EXTENSION <extention_name> : <behavior>
Example 2: Form of an OpenCL extension pragma
The <behavior>
token can one of the following:
- enable: the extension is enabled if supported, or an error is
reported if the specified extension is not supported or the token "all" is
used.
- disable: the OpenCL implementation/compiler behaves as if the
specified extension does not exist.
- all: only core functionality of OpenCL is used and supported, all
extensions are ignored. If the specified extension is not supported then a
warning is issued by the compiler.
By default, the compiler requires that all extensions be
explicitly enabled as if it had been provided with the following pragma:
#pragma OPENCL EXTENSION all : disable
Example 3: Pragma to disable all extensions
The December 2011 version of the "AMD
Accelerated Parallel Processing OpenCL" guide lists the availability of the
following KHR extensions:
- cl_khr_global_int32_base_atomics: basic atomic operations
on 32-bit integers in global memory.
- cl_khr_global_int32_extended_atomics: extended atomic operations
on 32-bit integers in global memory.
- cl_khr_local_int32_base_atomics: basic atomic operations
on 32-bit integers in local memory.
- cl_khr_local_int32_extended_atomics: extended atomic
operations on 32-bit integers in local memory.
- cl_khr_int64_base_atomics: basic atomic operations on
64-bit integers in both global and local memory.
- cl_khr_int64_extended_atomics: extended atomic operations
on 64-bit integers in both global and local memory.
- cl_khr_3d_image_writes: supports kernel writes to 3D
images.
- cl_khr_byte_addressable_store: this eliminates the
restriction of not allowing writes to a pointer (or array elements) of types
less than 32-bit wide in kernel program.
- cl_khr_gl_sharing: allows association of OpenGL context or
share group with CL context for interoperability.
- cl_khr_icd: the OpenCL Installable Client Driver (ICD)
that lets developers select from multiple OpenCL runtimes which may be
installed on a system.(This extension is automatically enabled as of SDK v2 for
AMD Accelerated Parallel Processing.)
- cl_khr_d3d10_sharing: allows association of D3D10 context
or share group with CL context for interoperability.
Version 1.2 of the Khronos OpenCL API registry lists
the availability of the following extensions. Either click on the hyperlink or
access the Khronos OpenCL Working Group document, "The
OpenCL Extension Specification"to find more detailed information about individual
version 1.2 extensions.
Device Fission
By default, each OpenCL kernel attempts to use all the computing
resources on a device according to a data parallel computing model. In
other words, the same kernel is used to process data on all the computational
resources in a device. In contrast, a task parallel model uses the
available computing resources to run one or more independent kernels on the
same device. Both task- and data-parallelism are valid ways to structure code
to accelerate application performance given that some problems are better
solved with task parallelism while others are more amenable to solution by data
parallelism. In general task parallelism is more complicated to implement
efficiently from both a software and hardware perspective. The default OpenCL
default behavior to use all available computing resources according to a
data-parallel model is a good one because it will provide the greatest speedup
for individual kernels.
On AMD platforms, there are two methods to limit the number
of cores utilized when running a kernel on a multi-core processor.
- The
AMD OpenCL runtime checks an environmental variable CPU_MAX_COMPUTE_UNITS.
If defined the AMD runtime will limit the number of processor cores used by an
OpenCL application to the number specified by this variable. Simply set this
environment variable to a number from 1 to the total number of multi-processor cores
in a system. Note: this variable will not affect other devices such as GPUs nor
is it guaranteed to work on with all vendor runtimes.
- The
EXT Device Fission extension, cl_ext_device_fission, provides an
interface within OpenCL to sub-divide a device into multiple sub-devices. The
programmer can then create a command queue on each sub-device and enqueue
kernels that run on only the resources (e.g. processor cores) within the
sub-device. Each sub-device runs asynchronously to the other sub-devices.
Currently, Device Fission only works for multi-core processors (both AMD and
Intel) and the Cell Broadband engine. GPUs are not supported.
(Note: it is possible
to restrict the number of work-groups and work-items so an OpenCL kernel uses
only few cores of a multi-core processor and then rely on the operating system
to schedule multiple applications to run efficiently. This method is not
recommended for many reasons including the fact that it effectively hardcodes a
purposely wasteful usage of resources. Further, this trick depends on external
factors like the operating system to achieve efficient operation. Also, this
trick will not work on GPUs.)
The webinar slides "Device
Fission Extension for OpenCL" by Ben Gaster discusses Device Fission in the
context of parallel pipelines for containers. He notes there are three general
use cases when a user would like to subdivide a device:
- To
reserve part of the device for use for high priority / latency-sensitive tasks.
- To
more directly control the assignment of work to individual compute units.
- To
subdivide compute devices along some shared hardware feature like a cache.
Typically these are use cases where some level of additional
control is required to get optimal performance beyond that provided by standard
OpenCL 1.1 APIs. Proper use of this interface assumes some detailed knowledge
of the devices.
The AMD SDK samples provide an example that uses Device
Fission on multi-core processors. In a standard install, this sample can be
found in /opt/AMDAPP/samples/cl/app/DeviceFission. Ben Gaster also has some
nice slides discussing the basics required to utilize Device Fission in his March
2011 presentation to the Khronos Group, "OpenCL
Device Fission".
Device Fission in an OpenCL click-together tool framework
As noted in part 8 of this
tutorial series, preprocessing the data can be as complicated and time
consuming as the actual computation that generates the desired results. A
"click-together" framework (illustrated below and discussed in greater detail
in part 8) naturally exploits the parallelism of multi-core processors because
each element in the pipeline is a separate application. The operating system
scheduler ensures that any applications that have the data necessary to perform
work will run – generally on separate processor cores. Under some
circumstances, it is desirable to partition the workflow so that multiple
click-together OpenCL applications can run on separate cores without
interfering with each other. Perhaps the tasks are latency sensitive or the
developer wishes to use a command like numactl under UNIX to
bind an application to specific processing cores for better cache utilization.
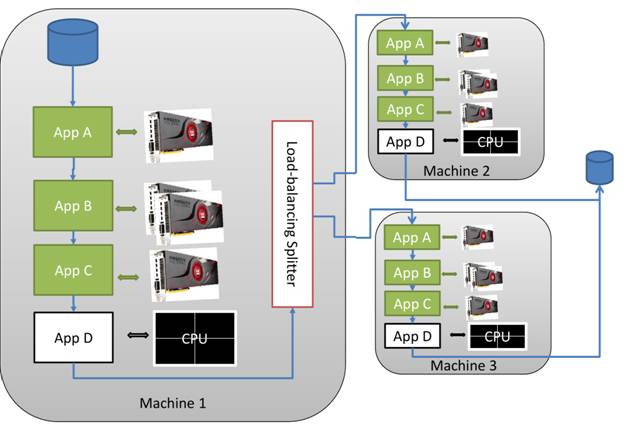
Figure 1: Example click-together workflow
The following source code for dynOCL.cc from part 8
has been modified to use Device Fission. The changes are highlighted in color.
Briefly, the changes are:
- Using
a C++ define to enable the C++ Device Fission bindings.
- Check
if the device supports the cl_ext_device_fission extension.
- Subdivide
the device.
#include <cstdlib>
#include <sys/types.h>
#include <dlfcn.h>
#include <string>
#include <iostream>
#include "packetheader.h"
#define PROFILING // Define to see the time the kernel takes
#define __NO_STD_VECTOR // Use cl::vector instead of STL version
#define __CL_ENABLE_EXCEPTIONS // needed for exceptions
#define USE_CL_DEVICE_FISSION 1
#include <CL/cl.hpp>
#include <fstream>
using namespace std;
void *lib_handle;
typedef char* (*initFini_t)(const char*, const char*, uint32_t*, uint32_t*);
typedef char* (*func_t)(const char*, const char*, uint32_t*, uint32_t*, char*);
typedef void (*dynFree_t)(char*);
typedef void (*oclSetup_t)(const char*, cl::CommandQueue*);
int main(int argc, char **argv)
{
if(argc < 3) {
cerr << "Use: sourcefilename cpu|gpu oclSource" << endl;
return -1;
}
string base_filename(argv[1]);
base_filename = base_filename.substr(0,base_filename.find_last_of("."));
string buildCommand("gcc -fPIC -shared -I $ATISTREAMSDKROOT/include ");
buildCommand += string(argv[1])
+ string(" -o ") + base_filename + string(".so ");
cerr << "Compiling with \"" << buildCommand << "\"" << endl;
if(system(buildCommand.c_str())) {
cerr << "compile command failed!" << endl;
cerr << "Build command " << buildCommand << endl;
return -1;
}
string nameOfLibToLoad("./");
nameOfLibToLoad += base_filename;
nameOfLibToLoad += ".so";
lib_handle = dlopen(nameOfLibToLoad.c_str(), RTLD_LAZY);
if (!lib_handle) {
cerr << "Cannot load library: " << dlerror() << endl;
return -1;
}
initFini_t dynamicInit= NULL;
func_t dynamicFunc= NULL;
initFini_t dynamicFini= NULL;
dynFree_t dynamicFree= NULL;
dlerror();
dynamicFunc= (func_t) dlsym(lib_handle, "func");
const char* dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
dynamicInit= (initFini_t) dlsym(lib_handle, "init");
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
dynamicFini= (initFini_t) dlsym(lib_handle, "fini");
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
dynamicFree= (dynFree_t) dlsym(lib_handle, "dynFree");
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
oclSetup_t oclSetupFunc;
oclSetupFunc = (oclSetup_t) dlsym(lib_handle, "oclSetup");
dlsym_error = dlerror();
if (dlsym_error) { cerr << "sym load: " << dlsym_error << endl; return -1;}
const string platformName(argv[2]);
const char* oclKernelFile = argv[3];
int ret= -1;
cl::vector<int> deviceType;
cl::vector< cl::CommandQueue > contextQueues;
if(platformName.compare("cpu")==0)
deviceType.push_back(CL_DEVICE_TYPE_CPU);
else if(platformName.compare("gpu")==0)
deviceType.push_back(CL_DEVICE_TYPE_GPU);
else { cerr << "Invalid device type!" << endl; return(1); }
try {
cl::vector< cl::Platform > platformList;
cl::Platform::get(&platformList);
cl::vector<cl::Device> devices;
for(int i=0; i < deviceType.size(); i++) {
cl::vector<cl::Device> dev;
platformList[0].getDevices(deviceType[i], &dev);
for(int j=0; j < dev.size(); j++) {
if(dev[j].getInfo<CL_DEVICE_EXTENSIONS>().
find("cl_ext_device_fission") == std::string::npos) {
cerr << "Device Fission NOT on device" << endl;
return(-1);
} else
cerr << "Have DEVICE_FISSION" << endl;
}
for(int j=0; j < dev.size(); j++) devices.push_back(dev[j]);
}
cl_context_properties cprops[] = {CL_CONTEXT_PLATFORM, NULL, 0};
cl::Context context(devices, cprops);
cerr << "Using the following device(s) in one context" << endl;
for(int i=0; i < devices.size(); i++) {
cerr << " " << devices[i].getInfo<CL_DEVICE_NAME>() << endl;
}
cl_device_partition_property_ext props[] = {
CL_DEVICE_PARTITION_EQUALLY_EXT,
1,
CL_PROPERTIES_LIST_END_EXT,
0
};
cl::vector<cl::Device> sdevices;
devices[0].createSubDevices(props, &sdevices);
cerr << "Sub-divided into " << sdevices.size() << " devices" << endl;
for(int i=0; i < sdevices.size(); i++) {
#ifdef PROFILING
cl::CommandQueue queue(context, sdevices[i],CL_QUEUE_PROFILING_ENABLE);
#else
cl::CommandQueue queue(context, sdevices[i],0);
#endif
contextQueues.push_back( queue );
}
} catch (cl::Error error) {
cerr << "caught exception: " << error.what()
<< '(' << error.err() << ')' << endl;
return(-1);
}
oclSetupFunc(oclKernelFile, &contextQueues[0]);
if (!setPacket_binaryIO()) {
cerr << "Cannot set binary mode for cin and cout!" << endl;
return -1;
}
uint32_t size, type;
char *retBlob;
if( (retBlob=(*dynamicInit)(argv[0], base_filename.c_str(),&size, &type)) ) {
writePacketHdr(size, type, &std::cout);
cout.write(retBlob, size);
(dynamicFree)(retBlob);
}
while(readPacketHdr(&size, &type, &std::cin)) {
char *blob = new char[size];
cin.read(blob, size);
retBlob =(*dynamicFunc)(argv[0], base_filename.c_str(), &size, &type, blob);
if(retBlob) {
writePacketHdr(size, type, &std::cout);
cout.write(retBlob, size);
if(retBlob != blob) (dynamicFree)(retBlob);
}
delete [] blob;
}
if( retBlob = (*dynamicFini)(argv[0], base_filename.c_str(),&size, &type) ) {
writePacketHdr(size, type, &std::cout);
cout.write(retBlob, size);
(dynamicFree)(retBlob);
}
dlclose(lib_handle);
return 0;
}
Example 4: Modified dynOCL.cc to use Device Fission
To build and use this example, simply substitute this source
code for dynOCL.cc in part 8.
For testing purposes, the following OpenCL kernel, longAdd.cl,
can be substituted for simpleAdd.cl in the part 8 commands to
demonstrate that Device Fission is working.
inline __kernel void init(int veclen, __global TYPE1* c, int offset)
{
}
inline __kernel void func(int veclen, __global TYPE1* c, int offset)
{
int index = get_global_id(0);
int n=100000;
for(int j=0; j < n; j++)
for(int i=0; i < n; i++) {
TYPE1 tmp = c[index + offset*veclen];
c[index + offset*veclen] += c[index + offset*veclen];
c[index + offset*veclen] -= tmp;
}
}
inline __kernel void fini(int veclen, __global TYPE1* c, int offset)
{
}
Example 5: Source for longAdd.cl to consume lots of CPU time
Following is the graphical output of system monitor for a
6-core AMD Phenom™ II X6 1055T Processor running Ubuntu 10.10 that demonstrates
the default OpenCL behavior to run on all the cores. As noted previously, the longAdd.cl
source code was substituted for simpleAdd.cl in the part 8 script.
Notice that the processor utilization jumps for all six processors when the
application starts running.

Example 6: Default OpenCL behavior is to use all processing cores
Utilizing the Device Frission version of dynOCL.cc
from this tutorial, we see that only one processing core (in this case the
orange line) achieves high utilization.
Example 7: Only a single core is used by the Device Fission code
Summary
OpenCL extensions provide programmers with additional capabilities
such as double-precision arithmetic and Device Fission. Vendor extensions are
the least portable but they do provide an important path to expose an API to
exploit device capabilities. The KHR extensions are the most general as they
require formal ratification and a test suite to define a standard behavior. The
EXT extensions can be viewed as a "work in progress" API that might eventually
achieve the formal status of a KHR extension.
With the Device Fission extension, programmers have an API
to subdivide multi-core processors to better exploit system capabilities. The
Google protobuf streaming framework introduced in part 8 was easily extended to
utilize Device Fission. Through operating systems commands such as numactl, programmers can
even bind OpenCL applications in this streaming framework to specific
processing cores. By extension, OpenCL application programmers can use Device
Fission to further optimize OpenCL plugins and generic workflows discussed in
parts 7 and 8 of this tutorial series.

