Introduction
- Column store indexes are run by Microsoft’s VertiPaq technology.
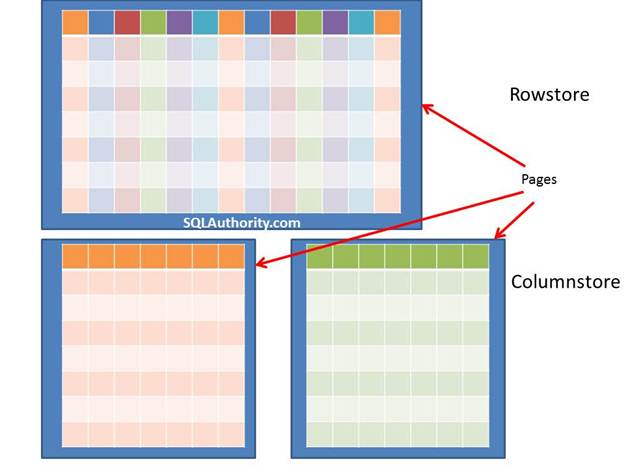
- In case of the row store indexes, multiple pages will contain multiple rows of the columns spanning across multiple pages. In case of column store indexes, multiple pages will contain multiple single columns. This will lead only the columns needed to solve a query to be fetched from disk. Additionally, there is a good chance that there will be redundant data in a single column which will further help to compress the data, this will have positive effect on buffer hit rate as most of the data will be in memory and due to the same, it will not need to be retrieved.
- https://bineeshthomas.wordpress.com/2011/10/07/what-is-vertipaqctp3-denali-sql-server/
VertiPaq makes columnstore indexes more efficient because it uses a different way of storing columns than traditional indexes, and it effectively compresses the data in the index. In a regular index, all indexed data from each row is kept together on a single page, and data in each column is spread across all pages in an index. In a columnstore index, the data from each column is kept together so each data page contains data only from a single column. In addition, the index data for each column is compressed, and since many columns often contain highly repetitive values, the compression ratio can be very high. This architecture reduces the number of pages in the index and, if you are selecting only a few columns, it also reduces the number of pages that need scanning (and therefore it is more likely that SQL Server will be able to keep them in memory).
WITHOUT ANY INDEX
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 9 ms.
(1 row(s) affected)
Table 'BitTable'. Scan count 9, logical reads 278294, physical reads 0,
read-ahead reads 243609, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 21247 ms, elapsed time = 69118 ms.
WITHOUT COLUMNSTORE INDEX (WITH NORMAL INDEX)
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 12 ms.
(1 row(s) affected)
Table 'BitTable'. Scan count 9, logical reads 153430, physical reads 0,
read-ahead reads 99164, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 14929 ms, elapsed time = 46018 ms.
WITH COLUMNSTORE INDEX
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 9 ms.
(1 row(s) affected)
Table 'BitTable'. Scan count 8, logical reads 752, physical reads 1, read-ahead reads 296,
lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 11714 ms, elapsed time = 2977 ms.
Columnstore Structure
Columnstore data is physically stored in one or more segments (regular LOB allocation units) per column, and may also be partitioned in the usual way. Each segment contains roughly one million rows of highly-compressed values or value references (several compression techniques are available). A value reference link to an entry in one of up to two hash dictionaries.
Dictionaries are pinned in memory during query execution, with data value IDs from the segment being looked in the dictionary whenever execution requires the actual data value (this lookup is deferred for as long as possible for performance reasons).
Segments also have a header record containing metadata such as the minimum and maximum values stored in the segment. Information from the header can often be used to eliminate complete partitions from processing at execution time. Header record information is stored in the usual LOB data root structure, so eliminating a segment means the Storage Engine can skip reading the LOB data pages from physical storage entirely. Maximizing the potential for elimination can require careful design, including a dependency on the clustered index order at the time the Columnstore index is built.
Specific Plan Operators
SQL Server 2012 introduces a new execution mode called Batch Mode. In this mode, packets of roughly 1000 rows are passed between operators, significantly improving processor utilization efficiency. Within each packet, columnar data is represented as a vector. Not all plan operators support batch mode operation, but examples of those that do include Columnstore Index Scan, Hash Inner Join, Batch Hash Table Build, Bitmap Filter, Hash Aggregate (not scalar aggregates), Filter, and Compute Scalar (for projection and expression evaluation).
A columnstore index has no rows; instead it uses the BLOB storage to store the column 'segments'. Due to compression possible with column oriented storage, it needs only about one third of the pages needed by the clustered index, although it contains the same columns and the same number facts.
BLOB (Binary Large Object)
A BLOB (binary large object) is a large file, typically an image or sound file, that must be handled (for example, uploaded, downloaded, or stored in a database) in a special way because of its size.
SQL Server stores the BLOB data as a collection of 8KB pages that it organizes in a B-tree structure. Each row's BLOB column contains a 16-byte pointer to the root B-tree structure that tracks the various blocks of data that make up the BLOB. If the amount of binary data is less than 64 bytes, SQL Server stores it as part of the root structure itself. Otherwise, the root structure consists of a series of pointers that SQL Server uses to locate the blocks of data that make up the binary object.
Logical and Physical Reads
http://www.sql-server-performance.com/2010/logical-reads/
“The I/O from an instance of SQL Server is divided into logical and physical I/O. A logical read occurs every time the database engine requests a page from the buffer cache. If the page is not currently in the buffer cache, a physical read is then performed to read the page into the buffer cache. If the page is currently in the cache, no physical read is generated; the buffer cache simply uses the page already in memory.”
It is important to remember that SQL Trace reads are logical reads and not physical reads.
Logical Reads, Physical Reads and Buffer Cache Hit Ratio logical reads:
- Logical Reads: Reading Data pages from Cache
- Physical Reads: Reading Data pages from Hard Disk
- Buffer Cache Hit Ratio logical reads – physical reads)/logical read * 100%
Logical Reads
Logical read indicates total number of data pages needed to be accessed from data cache to process query. It is very possible that logical read will access the same data pages many times, so count of logical read value may be higher than actual number of pages in a table. Usually the best way to reduce logical read is to apply correct index or to rewrite the query.
Physical Reads
Physical read indicates total number of data pages that are read from disk. In case there is no data in data cache, the physical read will be equal to number of logical read. And usually it happens for the first query request. And for subsequent same query requests, the number will be substantially decreased because the data pages have been in data cache.
Buffer Cash Hit Ratio
Buffer hit ratio will be calculated based on these two kinds of read as the following formula: (logical reads – physical reads)/logical read * 100%. The high buffer hit ratio (if possible to near 100%) indicates good database performance on SQL Server level. So use information from physical read and buffer hit ratio to measure performance in server level and logical read to measure individual query level.
Vertical Partitioning: Example

Row Store and Column Store
| Row Store | Column Store |
| Easy to add/modify a record | Only need to read in relevant data |
| Might read in unnecessary data | Tuple writes require multiple accesses |
Why Column Stores?
- Fetch only required columns for a query
- Better cache effects
- Better compression (similar attribute values within a column)
Benefits of Columnstore Index
- As Columnstore Index is stored in separate pages, only required pages are fetched from the disk
- Faster query processing
- Frequently accessed columns remain in memory
- Enhanced query optimization and execution features, improves data warehouse query performance by hundreds to thousands of times in some cases
B-tree
A B-tree is a method of placing and locating files (called records or keys) in a database. (The meaning of the letter B has not been explicitly defined.) The B-tree algorithm minimizes the number of times a medium must be accessed to locate a desired record, thereby speeding up the process.
B-trees are preferred when decision points, called nodes, are on hard disk rather than in random-access memory (RAM).
B-trees save time by using nodes with many branches (called children), compared with binary trees, in which each node has only two children. When there are many children per node, a record can be found by passing through fewer nodes than if there are two children per node.
In a tree, records are stored in locations called leaves. This name derives from the fact that records always exist at end points; there is nothing beyond them.
History
- 21st February, 2012: Initial version

