Introduction
Ever since I heard of the new Code First approach of Entity Framework, I did want to give it a try because the concept sounded quite appealing to me. For those of us who haven’t heard of it yet, the three start points to work with Entity Framework are:
- Database first, when we start our design from the database side.
- Model first, when we define our model directly in Visual Studio, creating our entities and establishing the proper relationships between them.
- Code First, this is the new strategy to be consolidated in the next .NET 4.5 release and consisting in declaring our entities as classes in our code.
This article does not pretend to be a Code First tutorial but a practical use of this technology in a middle complexity real life scenario. The result lacks some testing, error processing improvements and logging but it behaves well and is a good tool to demonstrate Code First.
The Entity Framework version used for this article is 4.2 and as database provider version 4.0 of SQL Server Compact which already supports identity fields.
Prerequisites
If you want to run the application, you will need to install previously SQL Server Compact 4.0 (http://www.microsoft.com/download/en/details.aspx?id=17876).
In order to edit the source code and debug it, you will have to upgrade to SP1 of Visual Studio 2010, in case you haven’t done it yet, as well as to install the Tools for SQL Server Compact 4.0.
The easiest way to install those updates and components is by using the Web Platform Installer tool from Microsoft: http://www.microsoft.com/web/downloads/platform.aspx.
Description
The system presented in this article is a kind of small multimedia cataloger tool which manages two concepts, namely, films and audio albums. Films are video files and albums are folders containing audio files, all of them in any of the common media formats and encodings. The user will define local folders storing video or audio albums and the system will search for files under those folders and their subfolders recursively.
For video files, the system will extract the information of the main video track, of all the audio ones and the language of subtitle tracks. In the case of audio files, only the main audio track information is required. To achieve this, the library MediaInfo was used (http://mediainfo.sourceforge.net).
Furthermore, for video files, a film information provider interface was included in the design to collect information about actors, director, film poster, genres and more. For now, only one of these information providers is implemented consisting in a FilmAffinity web site scraper (which could fail if the website changes its format or design), but adding a new one, such as imdb for instance, would be clean and straightforward.
For audio files, ID3 information is read out to generate the concept of album. In case any of the tags are not the same for all the audio files under a given folder, a generic “Multiple Values” string is assigned to the field in question.
The system is composed of a library holding the Code First entities definitions, the data context, main operations on them and folder processing and of a WinForm project that uses this library and allows a user to configure and consult the data.
The UI Application
Let me introduce now the main window of our user application.
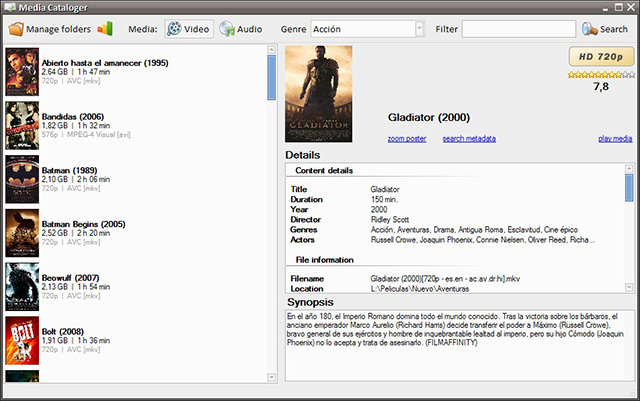
There are three main areas:
- A top toolbar with the main commands and search options
- A result list on the left to show the matches of the searches performed by the user
- A detail panel on the right to represent the information of the selected item on the matches list
Focusing on the toolbar, we will shortly describe the commands and controls contained in it.

- Opens the media folder management window, where we can add or remove media folders and fire the content processing task
- Shows a
MessageBox indicating the amount of records of each entity of interest are contained in the database - Media type selection buttons
- The media genre
combobox gets filled each time the media type selection changes with the appropriate values for the new selection and allows the user filtering by genre. - An additional text filter to refine the search or to search directly by it instead of selecting a given genre.
- This button performs the search operation applying the previous three filters and fills the result list with the matches found.
The result list is an overload of the ListView control that uses the Tile view to show the most important information for each item. Two remarkable things of this control are the dynamic creation of the ImageList associated with the list to display the images accompanying the matches and the resize mechanism of the tiles in order to expand to the list width so that it looks more like a row list rather than the normal tile representation.
Finally, the details panel displays the information available for the selected item on the result list including media tracks technical information, metadata from ID3 or from film information provider and file properties. A couple of extra commands are included as links in this view but you will have to discover what they exactly do by yourself.
The Data Library
The data library defines, as we have previously introduced, our data entities using Code First approach and declares the data context where those entities are included and some of their relationships get refined using Fluent API.
The Model
Well, now it’s time to discover our model in the way we have declared it as classes with Code First annotations, conventions and Fluent API. The goal was to include inheritance and all possible kind of relationships.
Here is a detailed view focusing on audio items.
And now, another one focusing on video elements.
As for the model diagram, it is quite self-explanatory since the concepts represented by the entities (folder, file, track …) should be familiar to almost everybody, but we will try to clarify the proposed entity creation mechanism with another diagram.
On the lower part of the diagram, we can see the way LanguageCode, VideoPerson, VideoGenre and AudioGenre get created. The getter methods in MediaCatalog return the instance of the requested entity, creating it previously if it does not exist in the corresponding table. Anyways, the end user of the library will not have the need to deal with these methods since they are all internally used mainly by VideoMetaInfo and AudioMetaInfo.
On the upper part, we find a static method in the MediaFile class definition which suggests that VideoFile and AudioFile instances should be created invoking it. It works as a kind of Factory method with Builder essence, implementing the common operations of MediaFile creation and delegating rest of the construction process to the concrete implementation of the protected methods BuildFromMediaInfo and BuildMetaInfo.
Still talking about MediaFile, the methods Add and Remove are the way we should go to achieve those operations since the deletion of AudioTrackInfo items related to MediaFile are configured not to be done on cascade.
Finally, although it is not shown in the diagram, MediaFolder implements a Remove method which handles the deletion of its related MediaFile records as well as some clean up like, for now, orphan AudioAlbumMetaInfo records removal.
Folder Processing
The data library includes a namespace containing the required classes to recursively update the media file records in the catalog, removing the ones that don’t exist anymore and adding the new ones.
For this processing, a composite pattern is used along with a visitor one as exposed in the following diagram. Have a look at the source code if you want to go into it in depth.
Code First Analysis
It’s time now to go a little bit more into detail with Code First and thus we will try to analyze the most interesting aspects of it related to our data model.
You can find a good introductory documentation on MSDN at this link where you can read about conventions, annotations and Fluent API.
The Data Model
As a reference and to allow visual comparisons between the generated entity model and the database schema, both diagrams are included here so you can examine the mapping that has been applied.
Resulting Entity Model
Mapped Database Schema
Conventions
The main convention used in the data library is the Primary Key one according to which if a property is found containing the string “Id” or the class name followed by that string, regardless of the case of the characters in the string “Id”, Code First infers that it is the entity’s primary key. Besides, if the property is of integer type, it will be mapped to an identity column.
Annotations
Code First annotations are one of the two tools we have to further define the data model when we are working with this technology, the other one is the previously mentioned Fluent API. In most cases, we can use annotations to concrete the particularities of our entity’s members but for some relationships, there is no other way than using Fluent API. Finally, notice that some of the annotations have a double use when using Code First together with MVC although we will just focus on the Code First meaning.
Let’s enumerate and comment briefly the annotations that have been used in the solution:
- [
Required] – The field is required and not nullable. It can also be used on references to other entities and foreign key fields. - [
NotMapped] – This annotation allows us to define properties that will not be mapped into table columns. - [
MaxLength(…)] – Used to limit the length of a text field in the database. - [
Table("Table name")] – Over an entity class definition to specify a different name than the one given by convention for the table to be mapped with this entity. - [
Key] – We use this annotation when the primary key does not comply with convention rules. - [
Column(TypeName = "image")] – To specify the storage format as image for a byte array property. - [
ComplexType] – This indicates that the following class won’t be mapped to an entity and if included as a field on an entity class, it will be mapped to columns of that entity’s table.
Inheritance
Supposedly, Code First default mapping strategy for inheritance is Table Per Hierarchy (TPH) unless you set something different using Fluent API but in our model, only one of the three cases of inheritance were mapped as TPH.
The first case of inheritance, found in MediaFile and children, behaves as expected and a single table is created for both children with a discriminator column. The following diagram illustrates this fact.
The second case is represented by MediaGenre and its two children. This time, Code First decided to apply the Table per Concrete Type (TPC) strategy as we can see in the diagram. I find it a better solution for this situation but I cannot fully infer the logic after this decision although my guess is that it has something to do to the relationships to those entities.
Finally, the third case is not a classic one since VideoTrackInfo is annotated as a ComplexType and its fields are mapped as columns of the entity where it is being used. This fact makes AudioTrackInfo the only one entity to be taken into account from the inheritance point of view and thus Code First just creates a single table for it.
Relationships
As stated on the introductory paragraphs, the aim of this article is to provide a working implementation covering as many aspects of Code First as possible to serve as a reference for other people developing projects with this technology. So, I will point out the best blog I have found about declaring relationships using Code First which, though written on version 4.1, is a great starting point for this subject. It is a series of six posts beginning with this one.
The schemas included before will help locating the different kinds of relationships defined in the model and once you locate a relationship of interest, you can address to the source code to see the implementation details.
Table Splitting
Table splitting allows mapping multiple entities to the same table in the database. We will use this functionality in our data project to define image fields as entities to enable lazy loading on them. The split entities are AlbumCover and VideoFilePoster.
Let just see the AlbumCover - AudioAlbumMetaInfo case. To enable table splitting on them, we have to specify that both entities will be persisted on the same table and define a shared primary key association, in other words a one-to-one primary key association, between them. The main entity then contains a navigation property to the one to be lazy loaded.
Indexes
Indexes are supported neither by annotations nor by fluent API and by default, the only indexes that will be created are the ones for our primary key fields. If we want to declare more new indexes, what will be the common case, the way we have to create them from within our data project is through a custom database initializer.
In the data project, we have opted for overriding the Seed method of an inherited class from DropCreateDatabaseIfModelChanges from where we call the ExecuteSqlCommand on the Database property passing the appropriate SQL commands to create the indexes.
At least, I would have expected that Code First generated foreign key fields were automatically indexed but they are not. Hopefully, it gets implemented in future releases of Entity Framework along with further improvements in this subject.
Images in SQL Server Compact
There is something peculiar with images fields in SQL Server Compact in Code First which for that database provider sets the maximum length of strings and binary fields to 4000. For a deeper explanation, I would recommend reading this post.
Since the images to be stored are bigger than that size, Code First complains when we invoke the SaveChanges method. The best solution I have found is making use of a workaround consisting on skipping validation for the entities that contain such fields by overriding the ShouldValidateEntity method of our DbContext inherited class.
This would be an additional reason to apply table splitting on entities having image fields when data storage is relied on SQL Server Compact because this way we can configure our context not to validate that split entity with just an image field defined in it but still validate the parent entity. Another possibility would be to disable validation for all entities setting the property ValidateOnSaveEnabled of DbContext Configuration field to false but it is a quite drastic decision.
This is the implementation done in our DbContext inherited class:
protected override bool ShouldValidateEntity(DbEntityEntry entityEntry)
{
if ((entityEntry.Entity is AlbumCover) || (entityEntry.Entity is VideoFilePoster))
return false;
return base.ShouldValidateEntity(entityEntry);
}
Final Notes
All images used in the solution included in this article fall into one of the following license kinds: Creative Commons, Freeware, GNU/GPL.
The diagrams shown in this article were created using yUML (http://yuml.me/) or Visual Studio Tools.
Wrong Relationship Definition
Once finished with the article and while reviewing the result, I have realized that there is a design error on one of the relationships between VideoFileMetaInfo and VideoPerson. I will try to find the time to fix it but for now, let’s see if you can discover it.
A Comment on SQL Server Compact 4.0
Maybe it’s just my old PIV box or the way Entity Framework interacts with SQL Server Compact 4.0 using Code First but it appears to perform quite inefficiently. As we will see, the main problem seems to be with identity keys generation and my guess is, since this is the first version of SQL Server Compact supporting it, that the implementation is not completely polished.
A test project is included in the solution where the model contains a single entity with just two fields. It allows us to write and read elements from a SQL Server Compact 4.0 database informing of elapsed times in the operations so that we can try the performance. Here, we can see the result of one execution with three sequential write tests and a final read one.
---------------------------------------------------------
- CE40PerformanceTest
---------------------------------------------------------
- R: Read test
- W: Write test
- X: Exit
WRITE TEST: Write 1000 items
Create objects: 5 ms | 200000 items/s
Add to DbSet: 5075 ms | 197 items/s
Save changes: 6358 ms | 157 items/s
WRITE TEST: Write 1000 items
Create objects: 6 ms | 166666 items/s
Add to DbSet: 4743 ms | 210 items/s
Save changes: 12453 ms | 80 items/s
WRITE TEST: Write 1000 items
Create objects: 4 ms | 250000 items/s
Add to DbSet: 8786 ms | 113 items/s
Save changes: 18955 ms | 52 items/s
READ TEST: Get items where Number < 50
150 items read | 1336 ms
What we observe here is how fast the insertion of new records degrades according to the amount of records existing in the database. Read test seems to perform better but not good enough for a production system.
On a second run, executing again the read test on the 3000 already inserted items, leads to a time close to 10 seconds.
To compare these results, based on my experience, persisting 3000 objects of such a class to an XML file using serialization, for example, should take much less than a second which is many times faster. Yes, I know this comparison is quite tricky since the XML test is just a serialization but in this case, without any relationship, index or trigger defined in the database, most part of the work to be done is writing the data to disk.
It would be interesting to run the test against a SQL Server database. I am sure the results are closer (if not better) to the XML serialization times rather than to the SQL Server Compact 4.0 ones.
Personal Thoughts
There is big potential in this technology above all the possibility to develop a full project without leaving our Visual Studio IDE and the fact that Code First entities get defined with POCO classes which means we would not need to generate another set of classes for service serialization.
On the other side, I wished there were some more annotations to deal with the model like setting indexes or customizing relationships and not depending on fluent API or SQL commands.
By the time this article was finished, the new version 4.3 of Entity Framework has already come to light implementing the first version of the migration feature to allow incremental changes on our model, some bug fixes and a couples of additional changes as we can read on a post on the ADO.NET blog on MSDN here.
During the current year 2012, version 4.5 of .NET Framework should be released including Entity Framework 4.5 which I think will be the first one to start considering working with for production systems when speaking about Code First.
History
- 2012-02-23: First version

