Introduction
Probability is defined as a quantitative measure of uncertainty state of information or event. It has an index which ranges from 0 to 1. It is also approximated through proportion of number of events over the total experiment. If the probability of a state is 0 (zero), we are certain the state will not happen. However if the probability is 1, the event will surely happen. A probability of 0.5 means we have maximum doubt about the state that will happen.

The following section describes some of the basic probability formulas that will be used:
Conditional probability: The probability of an event may depend on the occurrence or non-occurrence of another event. This dependency is written in terms of conditional probability:
P(A|B)
“the probability that A will happen given that B already has” or “ the probability to select A among B”
Notice that B is given first, and we find the proportion of A among B:
Given the above formula’: An event A is INDEPENDENT from event B if the conditional probability is the same as the marginal probability.
P(B|A) = P(B)
P(A|B) = P(A)
From the formulas the Bayes Theorem States the Prior probability: Unconditional probabilities of our hypothesis before we get any data or any NEW evidence. Simply speaking, it is the state of our knowledge before the data is observed.
Also stated is the posterior probability: A conditional probability about our hypothesis (our state of knowledge) after we revised based on the new data.
Likelihood is the conditional probability based on our observation data given that our hypothesis holds.
Bayes Theorem:
Thomas Bayes (c. 1702 – 17 April 1761) was a British mathematician and Presbyterian minister, known for having formulated a specific case of the theorem that bears his name: Bayes' theorem, which was published posthumously.
The following are the mathematical formalisms, and the example on a spam filter, but keep in mind the basic idea.
The Bayesian classifier uses the Bayes theorem, which says:
Considering each attribute and class label as a random variable and given a record with attributes (A1,A2,…, An), the goal is to predict class C. Specifically, we want to find the value of C that maximizes P(C| A1,A2,…An).
The approach taken is to compute the posterior probability P(C| A1,A2,…An) for all values of C using the Bayes theorem.
So you choose the value of C that maximizes P(C| A1,A2,…An). This is equivalent to choosing the value of C that maximizes P(A1,A2,…An | C) P(C).
So to simplify the task of Naïve Bayesian Classifiers, we assume attributes have independent distributions.
The Naïve Bayes theorem has the following characteristics as advantages and disadvantages:
Advantages:
- Handles quantitative and discrete data
- Robust to isolated noise points
- Handles missing values by ignoring the instance
- During probability estimate calculations
- Fast and space efficient
- Not sensitive to irrelevant features
- Quadratic decision boundary
Disadvantages:
- If conditional probability is zero
- Assumes independence of features
Naïve Bayesian prediction requires each conditional probability be non zero. Otherwise, the predicted probability will be zero.
In order to overcome this, we use probability estimation from one of the following:
The explanation of these is out of the scope of this tutorial.
Program
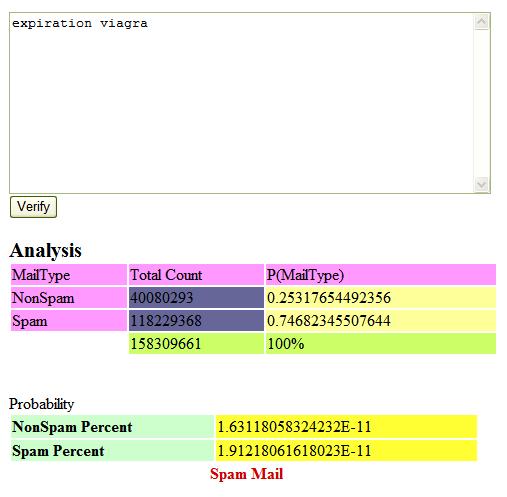
In order to classify and predict a spam email from a non spam one, I will be using the following techniques and assumptions:
- I'll be sorting according to language (spam or non spam), then words, then count
- If a word does not exist, consider to approximate P(word|class) using Laplacian
- I'll be using the following table for my analysis
The antispam-table.txt file is the file that contains each word that content filtering uses to determine if a message is spam. Beside each word, there are three numbers. The first number is an identifier assigned by the anti-spam engine. The second number is the number of times that the word has occurred in non-spam e-mail messages. The third number is the number of times that the word has occurred in spam e-mail messages.
http://support.ipswitch.com/kb/IM-20030513-DM01.htm
Anti-spam table for Statistical Filtering and a new phrase list for Phrase Filtering.
I've create a database from the CSV file. Please see the tutorial. I've also included the Excel computation as a reference. The code goes as follows:
- Remove or replace any known or unknown special characters so only the words can be used for the probability computation. It's best to stick with lower case or convert everything to lower case. (I've not done that.)
String inputContent = TextBox1.Text;
inputContent = inputContent.Replace("\t", "");
inputContent = inputContent.Replace("\n", "");
inputContent = inputContent.Replace(",", "");
inputContent = inputContent.Replace(".", "");
inputContent = inputContent.Replace(";", "");
inputContent = inputContent.Replace(":", "");
inputContent = inputContent.Replace("?", "");
inputContent = inputContent.Replace("!", "");
inputContent = inputContent.Replace("&", "");
- Separate each word and find the corresponding value from the database. the value shows how many times the word has been found in a spam or non spam mail. If the word is not found, use laplace or just make it equal to 1 (reason stated above).
char seperator = ' ';
String[] words = inputContent.Split(seperator);
int CountWords = words.Length;
double SpamPercent = 1.0;
double NonSpamPercent = 1.0;
for (int i = 0; i < CountWords; i++)
{
String thisword = words[i];
String DBaseValue = (BayesTheorem.FindNonSpamWord(thisword));
if (DBaseValue == "")
{
DBaseValue = "1";
}
NonSpamPercent = NonSpamPercent * (Convert.ToDouble(DBaseValue) /
Convert.ToInt32(BayesTheorem.TotalNonSpam()));
}
for (int i = 0; i < CountWords; i++)
{
String thisword = words[i];
String DBaseValue = (BayesTheorem.FindSpamWord(thisword));
if (DBaseValue == "")
{
DBaseValue = "1";
}
SpamPercent = SpamPercent * (Convert.ToDouble(DBaseValue) /
Convert.ToInt32(BayesTheorem.TotalSpam()));
}
- Get the final probability by multiplying each word to the total probability:
SpamPercent = SpamPercent * Convert.ToDouble(Label4.Text) * 100;
NonSpamPercent = NonSpamPercent * Convert.ToDouble(Label3.Text) * 100;
- Show the results in a table:
Label6.Text = NonSpamPercent.ToString();
Label7.Text = SpamPercent.ToString();
Compare the results to one another and determine spam or nonspam based on the highest probability.
if (SpamPercent > NonSpamPercent)
Label8.Text = "Spam Mail";
else Label8.Text = "NonSpam Mail";
- Finally if you have determined an email to be spam, update the values in the database for each word. Same thing as with nonSpam. If the value does not exist in the database, just insert for future training. The more training, the better the classification.
History
- February 27, 2009: Draft of tutorial without source code
- March 1, 2009: Program download and output screenshot

