Introduction
It’s amazing to see how fast the usage of a web application can outpace initial expectations. Growth is good for business, but creates some real challenges when it comes to trying to keep everything up and running speedily along. When an application is being designed, estimates are made for the expected maximum load of web traffic and the number of concurrent requests that the databases will need to handle. Often, these estimates turn out to be too conservative (and sometimes even way off base), so software architects need to plan for much greater application load to avoid major redesigns in the future. These plans usually need to include a database scale-out strategy. Scaling web applications and databases can be quite complex depending on the requirements, but the good news is that for the majority of web applications, it can be done with little impact on a project’s timeline or budget, provided it’s taken into account at the beginning of the design cycle and not as an afterthought.
Scaling Up Versus Scaling Out
The most common approach to scaling applications is to scale them up. In essence, scaling-up simply means to keep increasing the resources (hardware) available on the server, allowing it to handle more load and user requests. The reason that this approach is so common is because it requires no change to the actual application, and all of the data is in one place, which certainly helps reduce complexity and maintenance.
The second and more complex approach is scaling-out. The basic idea is to partition data across several database servers and thereby splitting the load of the application across multiple servers.
While scaling out web servers can be done quite easily, properly scaling out database servers is far more challenging, and happens to be the focus of this article.
Scaling Out Database Servers
Both SQL Server 2005 and 2008 natively offer a few options to scale out databases. These include shared databases, replication, linked servers, distributed partitioned views, and service-oriented data architecture. Each of these technologies has its own pros and cons, and is covered in great detail on Microsoft’s site and many other resources on the web, so I won’t go into them here. Instead, I’ll focus on a strategy that is rightfully considered the most effective way to scale out databases, which also is not directly linked to any particular database vendor. This strategy is called Data-Dependent Routing (DDR).
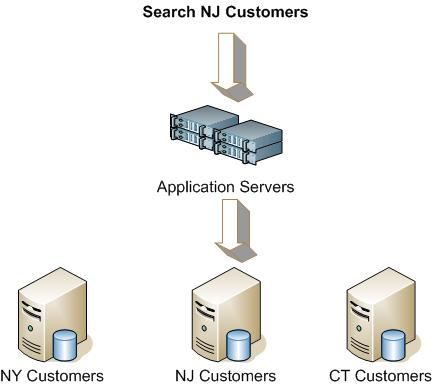
On the diagram above, you can see how a request to search for NJ customers is received by the application server and routed appropriately to be processed by the NJ Customers database.
Data-Dependent Routing (DDR)
Data-dependent routing, in its most elementary form, allows software architects to partition their application’s data across multiple databases in a way known only to the underlying application. So, the application receives database requests, and appropriately routes them to the right databases for processing. Although this approach is a bit more complex to implement and maintain than other scaling-out options, it allows for unprecedented flexibility and unmatched performance gains.
Partitioning Data
One of the challenging decisions software architects face when implementing DDR applications is how exactly to partition the data to balance performance with maintenance costs. Ideally, you want optimum performance and very low maintenance costs. Unfortunately, there is not one answer for every case, so it’s important to understand the options and decide what would work best for each application.
Generally, there are two options to partition data:
Horizontal Data Partitioning
With horizontal data partitioning, the database structure is identical across multiple database instances. The only difference among them lies in the data they hold. For instance, we can separate the data by the region your customers reside in and have one database for NJ customers and one for NY customers.
Vertical Data Partitioning
With vertical data partitioning, the actual tables are separated into multiple database instances. Each database instance generally handles different sets of data. For instance, we might want to configure sales related data in one database and the marketing related data in a different database.
Although both options are viable, this article will focus on horizontal data partitioning because I find it easier to understand and implement in many scenarios. So with that, let’s dive into a Use Case.
Use Case for Horizontal Data Partitioning
Application Overview
Let’s assume that we are trying to design a web application that’s going to serve many mid-size and large companies. Let’s also assume that each company has their own specific data and users and data is never shared among companies. The exact nature of the application is not particularly important for our Use Case, but for our purposes, it can be maintaining users’ contact data and other data related to business operations.
Application Architecture
Based on the description above and assuming that at the most extreme case we would dedicate one database server per company, we can easily structure the application in the following way:
Each company would be assigned one “home database” to hold all its users and data. We would maintain one central database (“Post Office” database) to hold all users in the system and a list of their corresponding home databases, so we could determine which database should handle each request at runtime.
The overall application architecture might look like the following:

The diagram above includes a web farm to handle our application’s interface, several application servers to handle the business logic and database routing, one central database to hold the user mappings to home databases, and several home databases that each hold the specific company data.
Central Database Design
The central database in our case is fairly simple, and includes the following three tables:
- home_databases – holds the information necessary to construct connection strings for connecting to each home database.
- clients – holds our clients (companies) information, and associates each client with one home database.
- users – holds all users in the system, their internal ID, email, and client association, so we can determine at run time their corresponding home database.
Home Database Design
Each home database will include the following tables (aside from its normal business data):
- users – holds user authentication information (email, password, etc.).
- tokens – holds user tokens. Tokens are created when users log in, and contain information that the application uses to identify a user’s home database for future calls and for authorization.
Sample Application’s Operations
Once we have configured the database infrastructure, let’s examine how our application might operate under two common scenarios: logging in and querying some data.
Login Operation
Input: User’s email and password.
Output: User’s authorization token.
Process:
- The user supplies their email address and password.
- The application will contact the central database and figures out the user’s home database based on the email provided.
- The application will contact the user’s home database and verify the provided credentials.
- Upon successful verification, the application will create a unique token with the user’s home database identifier and possibly other information. This approach will help us avoid contacting the central database to locate the right home database with every call the user makes.
- The application returns the token to the client code, so the token can be used for future calls.
Querying Data
Input: User’s token and any additional data for the query.
Output: User’s requested data.
Process:
- The application extracts the token’s information and determines the user’s home database.
- The token is verified against the appropriate home database.
- The appropriate query is called against the user’s home database (authorization might need to take place before the actual database query call).
- The application returns the appropriate data to the client code for processing (i.e., for display on the browser).
Other Scaling-Out Topics
Configuration Data
Often, your application might require some configuration data to be available on all home databases. Configuration data is generally fairly static. One possible solution is to maintain this information on the central database and replicate it to all other home databases using the built-in replication architecture.
Sharing Data
There are cases where the application data needs to be shared across multiple home databases. For instance, what if users in multiple home databases can contact each other and we want to show all of the requests that a particular user has sent and received. You can consider maintaining all the data required on a particular home database and replicate a subset of this data to other home databases that might require it.
There are a few options to do this, and two that worked particularly well for Scopings. We use distributed transactions when you need to log information in two or three databases, and we use Service Broker to share information across a larger number of home databases.
Cross-Database Queries
You might find cases where you need to serve certain requests by querying data across multiple databases. One of the options that Microsoft has introduced for this purpose is linked servers. This allows developers to run queries and joins against multiple databases and servers, which might just do the trick for this case. Unfortunately, unless the application infrastructure is extremely simple and the linked servers can be assigned easily, this might become quite complex to maintain.
One of the solutions we have found to be very effective was to implement a Stored Procedure that will only retrieve data from its particular database and return the data in XML format. This way, the application can potentially query as many databases as needed, and can then easily merge the XML retrieved from all databases into one XML document. The client can then simply use XSLT to process the merged XML as if it was retrieved by one normal query.
Distributing Database Storage
In applications that serve many small entities that may or may not interact with one another, there is often a need to control the distribution of entities across all available home databases. This can be achieved by managing the list of available home databases and their data attributes on the Central Database, so the application code can determine at run time what the most appropriate database to use for creating the next new entity.
You might also want to develop an administrative procedure on the application to move entities between home databases in case you find certain home databases to be overly burdened with transactions, while other remaining idle most of the time.
Queued Processing
Sometimes you might end up processing more concurrent requests than you first envisioned, or you might have some radical spikes of requests at certain times (such as before a tax deadline). One of the very nice features of SQL Server 2005, and now SQL Server 2008, is Service Broker. Service Broker can be used to handle asynchronous transaction processing, replication, and more. You should definitely consider using it where appropriate because your hardware requirements for the application could shrink dramatically.
Conclusion
Designing an infrastructure that will scale out is by no means simple, but it can sometimes make or break your application. And keep in mind, that it’s always easier to design for scaling at the beginning of development rather than as an afterthought when your application is out in the wild.

