Introduction
Information is the backbone of every business; we are dependant on information. All the facts and figures become information if find on time, not only time but also before someone else find and present it. Otherwise all these facts and figures prove to be just meaningless data. It becomes more important when we have a large catalogue i.e. web where all this information is available, the only thing is to find it rapidly and timely.
It is evident from different researches that a worker spends a quarter of his/her time on searching the required information. This further leads to
- Decrease ROI (Return of Investment)
- In-efficient Productivity
- Missing opportunities, new business
- Inappropriate business decision
The above noted are not the only effects, rather the impacts can cascade throughout the enterprise.
Now we talk about the solutions that can be implemented to arrange the data & facts in such a way that it is readily and rapidly available to all the stakeholders who need the information. We shall discuss some points that will ensure the key elements of the information availability like:
- It must be available as fast as possible.
- It must be current and updated.
- It must be available to the intended users.
- It must be available through intranet and internet.
To ensure all the above points, we need to take help of different the search engines available on the web. Here we shall discuss about different topics related to search. For easy understanding of the term search, we divide this document in these parts
- What is search?
- What is a search engine?
- Types of search engines
- How search engines work?
- What is a robot.txt file?
- What is a sitemap?
- How Search Engines Rank Web Pages?
- Steps to add your website in Google?
- Points to remember while creating websites for fast and reliable search
- Some useful search Tips
- Improvements required?
What is search?
A search is the organized pursuit of information. Somewhere in a collection of documents, Web pages, and other sources, there is information that you want to find, but you have no idea where it is. You perform a search by issuing a query, which is simply a way of asking a question that will find the information you are looking for. Searching is usually an iterative process. You submit a query and if the results list does not contain the information you are looking for, you refine the query until you locate a page that contains the answer.
What is a search Engine?
A Web search engine is a tool designed to search for information on the World Wide Web. The search results are usually presented in a list and are commonly called hits. The information may consist of web pages, images, information and other types of files. Some search engines also mine data available in NewsBooks, databases, or open directories. Unlike Web directories, which are maintained by human editors, search engines operate algorithmically or are a mixture of algorithmic and human input.
Types of search engines
Though the term “Search Engine” is referred for both crawler-based search engines and human-powered directories, there is a significant different between the two.
Crawler-based search engines crawl or spider the web and store it in search engine's index. This index is sometimes referred as a catalog that contains all the web pages that crawler had found. If there is any updation in the webpage, this catalog is updated with the new information. Different sites have their own crawling schedules that determine when a crawler will update the index. Sometime, the user may not get the updated information for the reason that a webpage may have been crawled, but not indexed when you hit a search.
The Search Engine is the program that finds information through the millions of pages that are present in the index to find the user provided search criteria and rank them in order of what it believes is most relevant.
The other one is Human-Powered Directory. The website owner needs to submit a short description to the directory for your entire site. Then a search looks for a definitive match only in the descriptions submitted. Any updates or changes to your websites have no effect on your listing.
It used to be the case in web's early days that a search engine presents the results in either crawler-based or human-powered directory. However, today it is very common for this information to be presented with both types of results.
For example, MSN Search is more likely to present human-powered listings from LookSmart. However, it does also present crawler-based results (as provided by Inktomi), especially for more obscure queries.
- LookSmart provides search advertising products and services to text advertisers, as well as targeted pay-per-click search and contextual advertising via its Search Advertising Network. It provides directory and listing services to Microsoft.
- Inktomi Corporation was a California company that provided software for Internet service providers and was acquired by Yahoo! in 2002
How search engines work?
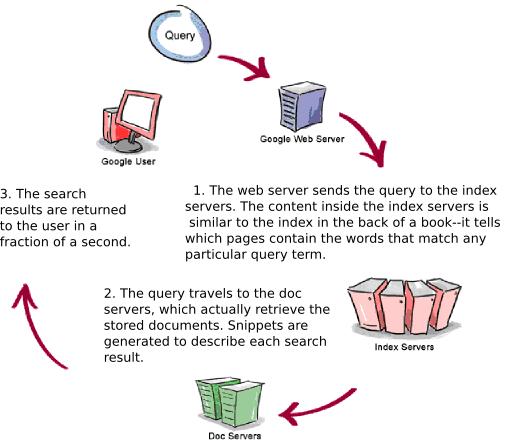
Though every search engine has its own implementation, Usually A search engine has four parts.
- Crawling
- Indexing
- Search Algorithm
- User Interface
Crawling is a process that is used by the search engines for accessing the contents of websites available on web and providing these contents to search engine's indexer. These crawlers can also be used to automate some maintenance activities on a website such as validating reference links and HTML Code. Also, crawlers can be used to gather specific types of information from Web pages, such as harvesting e-mail addresses (usually for spam). A crawler use sitemap file for discovery of website URLs for crawling. Googlebot is the web crawler that finds and fetches web pages for Google.
Indexing - Once the data has been crawl by the web crawler, the Search engine indexing collects, parses, and stores data to facilitate fast and accurate information retrieval. Popular engines focus on the full-text indexing of online, natural language documents. Media types such as video and audio and graphics are also searchable. A cache-based search engines permanently store the index along with the corpus.
Search Algorithm – Here lies the tricks of the trade. This is the part where every search engine has their own implementation. That is why the same query may provide you different results on different search engines. We can take an example of the Google’s Query processor that is responsible for fetching and providing the results to the end user. The life span of a Google query normally lasts less than half a second, yet involves a number of different steps that must be completed before results can be delivered to a person seeking information.
PageRank is Google’s system for ranking web pages. A page with a higher PageRank is deemed more important and is more likely to be listed above a page with a lower PageRank. Google considers over a hundred factors in computing a PageRank and determining which documents are most relevant to a query, including the popularity of the page, the position and size of the search terms within the page, and the proximity of the search terms to one another on the page.
Google also applies machine-learning techniques to improve its performance automatically by learning relationships and associations within the stored data. For example, the spelling-correcting system uses such techniques to figure out likely alternative spellings. Google closely guards the formulas it uses to calculate relevance; they’re tweaked to improve quality and performance.
Google shares general facts about its algorithm; the specifics are a company secret. This helps Google remain competitive with other search engines on the Web and reduces the chance of someone finding out how to abuse the system.
User Interface – This is the placeholder where all the query results are displayed. The Search Results Page may contain Title, Snippets, URL of Result and Size as mandatory information. The optional information may contain Google Logo, Statistics Bar, Tips, Sponsored pages, Spelling Corrections, Dictionary Definition, Cached, Similar Pages, News, Product Information, Translation, Book results etc.

What is a robot.txt file?
A robots.txt file on a website will function as a request that specified robots ignore specified files or directories in their search. This might be, for example, out of a preference for privacy from search engine results, or the belief that the content of the selected directories might be misleading or irrelevant to the categorization of the site as a whole, or out of a desire that an application only operate on certain data.
For websites with multiple subdomains, each subdomain must have its own robots.txt file. If example.com had a robots.txt file but a.example.com did not, the rules that would apply for example.com would not apply to a.example.com.
The format and semantics of the "/robots.txt" file are as follows:
- The file consists of one or more records separated by one or more blank lines (terminated by CR, CR/NL, or NL). Each record contains lines of the form "<field>:<optionalspace><value><optionalspace>". The field name is case insensitive.
- Comments can be included in file using UNIX bourne shell conventions: the '#' character is used to indicate that preceding space (if any) and the remainder of the line up to the line termination is discarded. Lines containing only a comment are discarded completely and therefore do not indicate a record boundary.
- The record starts with one or more User-agent lines, followed by one or more Disallow lines, as detailed below. Unrecognized headers are ignored.
- Optionally, the location of the Sitemap can also be included in the robots.txt file by adding the Sitemap: /sitemap.xml line to robots.txt.
- The file name must be robot.txt and must be placed on the root of the web i.e. www.example.com/robot.txt.
The following example "/robots.txt" file specifies that no robots should visit any URL starting with "/cyberworld/map/" or "/tmp/", or / PersonalData.html. A Sitemap file also has been provided.
# Robots.txt for http:
User-agent: *
Disallow: /cyberworld/map/ # This is an infinite virtual URL space
Disallow: /tmp/ # these will soon disappear
Disallow: /PersonalData.htm
Sitemap: /sitemap.xml
What is a sitemap?
Where a robot.txt disallow a crawler to retrieve information on a website, a Sitemaps protocol allows a webmaster to inform search engines about URLs on a website that are available for crawling.
A Sitemap is an XML file that lists the URLs for a site. It allows webmasters to include additional information about each URL: when it was last updated, how often it changes, and how important it is in relation to other URLs in the site. This allows search engines to crawl the site more intelligently. Sitemaps are a URL inclusion protocol and complement robots.txt, a URL exclusion protocol.
The webmaster can generate a Sitemap containing all accessible URLs on the site and submit it to search engines. Since Google, MSN, Yahoo, and Ask use the same protocol now, having a Sitemap would let the biggest search engines have the updated pages information.
Sitemaps supplement do not replace the existing crawl-based mechanisms that search engines already use to discover URLs. Instead by submitting Sitemaps to a search engine, a webmaster is only helping that engine's crawlers to do a better job of crawling their site(s). Using this protocol does not guarantee that web pages will be included in search indexes, nor does it influence the way that pages are ranked in search results
Some more fact about sitemaps
- Sitemaps can also be just a plain text file containing list of URLs.
- Sitemap files have a limit of 50,000 URLs and 10 megabytes per sitemap.
- Multiple sitemap files are supported, with a Sitemap index file serving as an entry point for a total of 1000 Sitemaps.
- The filename should fit in file naming restrictions of all common operating systems.
- The filename may contain any characters but must comply with the above 4th point.
A sample file of an XML Sitemap:
<?xml version='1.0' encoding='UTF-8'?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9"
http:
<url>
<loc>http:
<lastmod>2006-11-18</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>
</urlset>
A sample file of text Sitemap:
http:
http:
How Search Engines Rank Web Pages?
How a search engines go about determining relevancy, when confronted with hundreds of millions of web pages to sort through? They follow a set of rules, known as an algorithm. Exactly how a particular search engine's algorithm works is a closely-kept trade secret. However, all major search engines follow some general rules to determine the Page Ranking:
- Location – A location where the search string is present is very important. A website where the search string is present in the HTML title will be displayed first in comparison with the website where it is present in body text. In other words, if a search string is available in the title get the first preference and then header, then first few paragraphs of the body text in the index page and so on.
- Frequency - is the other major factor in how search engines determine relevancy. A search engine will analyze how often keywords appear in relation to other words in a web page. Those with a higher frequency are often deemed more relevant than other web pages.
- Meta Tags –Search engines also uses some Meta tags to rank/search/index pages. Every search engine has its own set of tags that are used for this purpose.
The above mentioned location/frequency method is a very generic method that is treated as a first step for page ranking in most of the search engines. The other methods include clickthrough measurement. It means that a search engine may watch what results someone selects for a particular search, then eventually drop high-ranking pages that are not attracting clicks, while promoting lower-ranking pages that do pull in visitors.
Search engines may also penalize pages or exclude them from the index, if they detect search engine "spamming." An example is when a word is repeated hundreds or thousands of times on a page, to increase the frequency and propel the page higher in the listings. Search engines watch for common spamming methods in a variety of ways, including following up on complaints from their users.
Going through the above basic page ranking that in a way is controlled by web administrator, a search engine may have their own algorithm to provide assured page ranking which is a trade secret and some search engines may even charge for their page ranking system. So even though the website administrator provides all the above noted information for page ranking, there is not any guarantee that their page will be displayed in the very first few result pages.
Steps to add your website in Google
In this section we shall discuss, how we can add a newly created website in Goggle’s database and allow other search engines also to crawl our website and make an entry in their index. So our website is available in the search results when someone searches. These steps are specific to Google and you must have a goggle email id as a prerequisite to perform these steps. Here are the steps to follow :
- Create a sitemap file and upload it on your website.
- Go to www.google.com/webmasters/tools/
- Login using your Google username and password
- Create a domain name providing your website.
- Provide the sitemap file and verify.
That’s all done. Now Google will index your website in its next crawling session. There is not any time frame that is specified for next crawling. You need to check intermittently if your site is displayed in the search results or not.
Points to remember while creating websites for fast and reliable search
Here are some points by following which you can achieve higher page ranking for your website.
- Provide relevant titles for each page in your website. A very common mistake people make is to copy the same title with a slight modification. In my opinion, the title of every page should be very specific to the contents of the page.
- Use the same rule for heading tags also. Put the most important keyword in h1 and second most important in h2 and so on for other variations.
- Always provide alt attribute for all the images on your page. The text provided in these attributes must be relevant to the page/image.
- A standard keyword density in content body should be between 4-6%. This means that 4-6 out of every 100 words should be the main keywords that a user might use in his/her search criteria.
- Regular updates of the pages. My suggestion is to refresh/update the contents once or twice in a month, but this rule changes for different websites depending on a many other factors. It is only for the crawler to get something different when it makes a visit to your website for updates.
- Provide your website link on other websites as well. There are 2 ways of doing it, one is to pay and provide your website link on some web marketing sites. The other is to provide your website link on some other sites with mutual agreements.
Some useful search Tips
Though the below provided is not a complete list. These can be used anytime you use search on Google. For a complete list you can refer the Google’s online help.
- Phrase search ("") - Using double quotes around a set of words enable google to consider the exact words in that exact order without any change.
- Exclusion Operator (-) - A minus sign immediately before a word (with a space between the string and - sign) indicates not to include pages that contain this word.
- Wildcard (*) - Works as a wildcardand can be very powerful. it tells Google to try to treat the star as a placeholder for any unknown characters and then find the best matches.
- Exact Search (+) - (without a space) can be used to search synonyms automatically, so that it finds related synonyms of the search string.
- OR operator - By default google behavior is to consider all the words provided in search text box. OR can be used if you want to get result if either one of provided words matches.
- A dollar sign ($) is usually used to indicate prices.
Improvements required?
>
Though today’s search engines are very advanced, there is always some scope for improvements. Here are some points that can be improved.
- A search can be extended to concept based instead of simple text based. A concept based search may provide a finer result set. For example, if I search for “indexing software” in Google. It gives me the irrelevant results on the very first page. That should not be the case. The result set contains the “Insurance software” that is totally irrelevant to my search criteria.
- More questions can be asked while searching the contents. It will make the search narrow and may produce a better and relevant result set. This is implemented by most of the sites by way of advance search.
- The other important factor that can be included is the document update date. A search engine never uses the document update date. It becomes very important when searching for current news. If there is a news for riots or blasts in any country, everyone will try to search “Riots in <country>” and may be provided a result sets with archived data that is irrelevant.
Useful Links
For more information about the terms used in the above document, you can refer these links.
http://Google.co.inhttp://searchenginewatch.com/http://www.seowizz.net/http://computer.howstuffworks.com/google1.htmhttp://en.wikipedia.org/wiki/Main_Page
Thanks

