Introduction
On 6th of March Microsoft released the SQL Server Data Tools
offered as a free extension living inside Visual Studio 2010. If you are in need
of a first idea about what the SSDT’s are I recommend you to read the link
above and come back to this article later again.
SSDT’s offer some features on paper I was missing so far, being that much impressive to me that I tried to question my current
style of database development using SQL Server Management Studio and give it a chance.
The objective of this article to help you in your decision about the question if you should adopt SSDT's for your database development or not. Furthermore I will give some pieces of advice about how I tried to solve some issues I encountered during testing.
SSDT’s top features
Namely I was attracted by these features the most:
- Schema syntax checks across all database objects; e.g. meaning that referencing a non existing column in a query yields an error
at design time
- Refactoring possibilities; e.g. when renaming a column this change will be propagated throughout the whole database schema automatically
- Auto generation of deployment scripts; meaning that I would no longer have to administer a list of change scripts and take care of the correct order of these script files
- Integrated development; meaning that the database project resides in the same Visual Studio solution as the .Net projects
- Source control the database; this is the result of the declarative approach where the complete database schema exists inside the Visual Studio solution
SSDT’s must have basic features
As compelling these top features are, abandoning SQL Server Management Studio as a well known and reliable database development platform is a huge step. This is why I also defined a list of more basic features needed for my daily work as database developer which must be provided by SSDT’s. Most of these features are critical to me, meaning that if only one critical feature is missing, I may prefer to continue using SQL Server Management Studio instead.
Here is the list of basic features I defined:
- Resolve references to other production and system databases like msdb
- Resolve references to other production databases connected by a linked server
- Support of migration scripts to enable data preservation and to add static data
- Fast and reliable build of deployment scripts
- Possibility of executing and deploying a single file
- Detection of isolated changes in the target database
- Responsive SSDT'S GUI as compared to SQL Server Management Studio
- Comfortable T-SQL writing
- Extendable usage of snippets
Testing SSDT’s basic features
Having defined what is important to me, the main part of this article is about the implementation of these features in SSDT's.
1 Resolve references to other production and system databases like msdb
Databases may reference each other and partly exist on different SQL Server instances. I simulated this by creating a Visual Studio solution containing not only the database to test but also adding additional databases being referenced by the main test database. This was done by creating a new SSDT SQL Server Database project and importing the referenced database into the project.
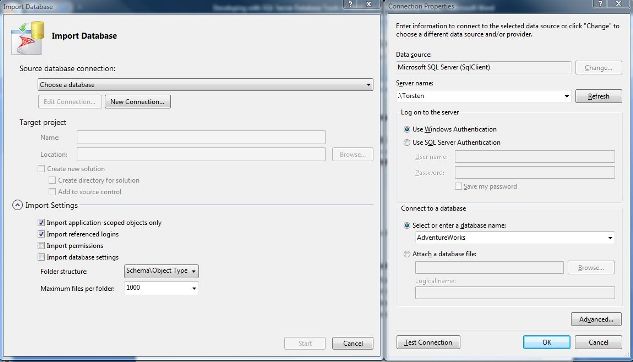
You also have to option to import a SSDT’s dacpac-file containing the schema, but of course, at the beginning you won’t have one. To give you a better idea in general about how your VS solution looks like after having imported the database have a look at this screenshoot:

After the import you need to build the project for VS to create the dacpac-file needed for referencing the project. Most likely your build will fail, because you will have lots of warnings and maybe errors in the project. Errors need to be resolved, warnings may be suppressed and thus don’t prevent the built (more on this later).
Nonetheless it means that you need to take care of the referenced database as well which may result in schema changes in this database, too. This makes it harder for you to get ready at the beginning when your database is referencing another production database. On the other side it is not a bad thing, because the errors and warnings do have a reason, and fixing them will probably improve your database.
Another inside is that if you decide to use the SSDT’s you should use them for all your databases referencing each other. By doing so your databases profit from the necessary bug fixing at the beginning and will coincide with the schemas used by the SSDT’s. This is important, because if you want to deploy a database referencing a not up-to-date database the deployment may fail.
Creating a database reference itself is straight forward by right-clicking on the references and selecting to add a database reference.
When adding a database reference the following dialog opens.
Other than selecting the database to reference you also decide about how to reference the database. Do you prefer a variable (as done in the screenshot above) or a literal (chosen when database variable field is blank).
Variable:
SELECT * FROM [$(Database2)].[Schema1].[Table1]
Literal:
SELECT * FROM [Database2].[Schema1].[Table1]
Using a literal has the advantage that you can run a script referencing another database directly as is. Using a variable has the advantage that when publishing, you don’t rely on a fixed name of the referenced database because you can simply change the value of variable.
Other than production databases you will also reference system databases. SSDT’s offers dacpacs for the msdb and the master database and can be referenced very simple in the dialog above. A small downside is that at least the master dacpac is incomplete, meaning that e.g. undocumented internal views are missing which may lead to warnings in your project you will have to suppress. Maybe Microsoft will add these in the future.
Another system database you will reference is the tempdb. In my tests it was not necessary to add a database reference to it to make usage of temporary tables like this:
IF EXISTS (SELECT * FROM tempdb.dbo.sysobjects WHERE ID = OBJECT_ID(N'tempdb..##MyTempTable'))
DROP TABLE ##MyTempTable;
On the other side, I got a warning when referencing a temporary table I had created in another stored procedure. To me, it looks like the create statement of the temporary table must reside inside the script using the temporary table. Otherwise a reference warning occurs.
2 Resolve references to other production databases connected by a linked server
Adding a database reference to a database on a different server is easy and done in the Add Database Reference dialog above. In the database location combobox you select “Different database/different server” and you define the Server name and/or variable. After that you can use the linked server reference like this (variables used):
SELECT
[Id], [ExtId], [ISIN]
FROM
[$(OtherServer)].[$(Database3)].dbo.Security
One thing to note is that a linked server is a server object, not a database object. This means that if you checked “include application scoped objects only” (as I always did) you will miss the linked server. I solved this by creating the linked server using a predeployment script (more on this later) like this:
IF NOT EXISTS(select * from sys.servers where name = N'MyLinkedServer')
BEGIN
EXECUTE sp_addlinkedserver @server = N'MyLinkedServer', @srvproduct = N'SQL Server';
END
3 Support of migration scripts to enable data preservation and to add static data
When renaming a column, an alter table statement will be created that drops the existing column and adding a new one which results in data loss. To avoid this, you can copy the data to preserve including the relevant key into a temporary table in a pre-deployment script and inserting the data back via an update statement later in a post-deployment script.
Somewhat less critical but still important is the ability to add static data (also called domain data) into a new table normally referenced by other tables. This can be done by creating the appropriate insert script in a post-deployment script.
To tell a script-file that it is a pre-/post-deployment script, you change the Build Action in the properties of the script file either to PreDeploy or to PostDeploy.
SSDT’s only support one single PreDeploy and PostDeploy script, but instead of writing all statements in a single script file, you can use as many as you want and reference them from the PreDeploy or PostDeploy script using a reference directive like this:
:r .\FirstPredeploymentScript.sql
:r .\SecondPredeploymentScript.sql
The script files referenced this way must have the build action set to none.
4 Fast and reliable build and deployment
To deploy you need to first build your project which takes some time, depending on the size of your database schema. To give you an idea, the first, complete build on a database having 230 tables and 660 stored procedures plus views, functions, assemblies, etc. takes about 2 minutes on my sluggish laptop. After the first build, the following builds are much faster. Additionally, you don’t need to rebuild every time you added a new database object, because you can already reference it without rebuild. The publishing procedure itself also takes some time when the deployment-script (aka delta-script) is generated and executed. If wanted, you also have the option to only generate the deployment-script, to revise it and to deploy it later.
When publishing, you may need to enter values for the variables and configure the connection of the target database. To avoid these repetitive steps, you can save the deployment configuration, make them part of your project and reuse them by double clicking the file in the Solution Explorer later as shown below.
A critical must have is that SSDT’s define the correct order when building the deployment script. So far, I did not encounter any issues on that. I also scanned the forum related to the SSDT’s and did not find any complaints about the wrong built order not being solved. This means right now I assume this is working in a reliable way.
5 Possibility of executing and deploying a single file
When writing complex queries, you probably want to check the results again and again to verify if what you do is correct. You can do so by defining your development database first in the options of the project.
Having done this, you can open the script file containing the query, selecting the sql-part to execute and do by clicking on Execute on the context menu.
You may also want to deploy the query several times after small changes within a small time frame without using the official deployment procedure. To do this, you can deploy a single database object similar to executing the query above.
Note that SSDT’s complain about the alter statement which is correct, because an alter statement does not belong to the declarative approach of the SSDT’s. Furthermore this ensures that you will change the alter back to create later because the project won’t build otherwise.
In fact, writing an alter statement is what SSDT's calls online development (aka imperative development) in contrast to offline development (aka declarative development). When doing online development you also profit from the possibility of debugging your stored procedures as you are used to when writing C# or VB.net code by simply selecting your procedure to debug in the SQL Server Object Explorer.
6 Detection of isolated changes in the target database
It may happen, that the production database is changed directly either by an admin, to make a quick bug fix or otherwise. When these changes are not mirrored in the SSDT’s project, they get lost when the project is deployed on the production system. This means that it is imperative to have a possibility to check if missing changes in the production database exist. This can be done manually by using the built-in schema compare.
In the screenshot I made some changes on the deployed database before doing the schema compare with the SSDT’s project schema. The differences are shown above. A pain point is that this must be done manually which can become quite complex if you want to deploy many changes. Furthermore, nothing saves you from deploying the changes when you forgot to make check the production database for changes.
What I am also missing is the ability to generate an easy to read report about the differences I could send to another developer to discuss possible database shifts.
7 Responsive SSDT's GUI as compared to SQL Server Management Studio
It is obvious that Visual Studio is much more powerful product than SQL Server Management Studio which unluckily also translates in a product which needs longer to load, may look somewhat bloated and sometimes responds slower than SQL Server Management Studio does. If you know Visual Studio 2010 already, you know what to anticipate, and I guess that it is a matter of personal preference if you feel uncomfortable working with it or not compared to SQL Server Management Studio. Myself, I like Visual Studio, probably mainly because I am already used to it, and I also remember how I disliked the SQL Server Management Studio first when we switched to it from the SQL Server 2000 Enterprise Manager. Today, I would never want to go back anymore.
8 Comfortable T-SQL writing
SSDT’s projects offer intellisense which is nice by definition, but not so nice if you are used to a third party product you use in SQL Server Management Studio on which you are used to and which you like more. In my case the third party product is SQL Complete from devart which also integrates in Visual Studio 2010 but seems to be incompatible with the SSDT’s database project type in its current version. In fact, using SSDT’s intellisense you get no support for typical SQL key words like “Select”, “Inner join” and so on, but intellisense is restricted on the database schema it-self (table names, column names, variables, etc). It also reacts somewhat reluctant, e.g. not proposing column-joins when joining tables. This combined with the missing query editor makes writing queries inferior to SQL Server Management Studio. In a presentation is saw that the query editor is a feature which may be introduced in a new version of SSDT’s, and I also hope that my preferred third party product will also be compatible with SSDT’s in a later release.
9 Extendable usage of snippets
This is another productivity feature like intellisense I don’t want to miss and already use a lot when both when writing queries in SQL Server Management Studio and programming in Visual Studio. Except being able to use snippets it is important to add your own snippets to the snippets collection. This can be done as always in Visual Studio using the Snippet Manager. Unfortunately, editing a new snippet is cumbersome, because I did not see any editor right now supporting SSDT’s-snippets. This means you need to craft it by hand which can easily be done but requires some work.
Apart from this, working with snippets in Visual Studio is fun and – as far as I am concerned – superior from handling than it is in SQL Server Management Studio because the replacement of the variable parts by tabing is very user friendly.
I hope that in the future a snippet editor will be available for SSDT’s snippets as well.
Basic must-have features summary
There was no feature in my list not supported in SSDTs, but some features still have room for improvement. I hope that when adoption of SSDT’s grows Microsoft will further improve the product; third party vendors will ensure compatibility with SSDT’s and open source extensions will provide additional content.
SSDT’s top features summary
I also want to shortly point out some comments about the top features mentioned at the beginning of this article:
Schema syntax checks
That's really great and helped me to find some inconsistencies in a schema of a production database. Mostly it was about queries (stored procedures and views) built ages ago on demand of users and not used anymore today.
Here is how it looks like if your stored procedure references a non existing column:
Refactoring possibilities
Compared to what refactoring means in the world of .Net-programming, the refactoring in SSDT's feel somewhat poor. You only have four types of refactoring, whereby the "expanding wildcards" functionality is also available in SQL Server Management Studio using the plug-in SQL Complete. My favorite one is the ability to rename a database object like a column in the whole schema. Although dynamic SQL is not taken into account, this feature is a real time-saver.
Here is how it looks like to rename a column from "Phone" to "PhoneNumber":
Auto generation of deployment scripts
I already treated this subject in point four of the basic features and just want to summarize that it worked well when testing and helps to make deployments easier compared to a manually maintained script collection.
Integrated development
Integreated development is an important subject when the database project does have a .Net counterpart and I see advantage in it in terms of transparancy compared to a script file collection existing outside the Visual Studio solution.
Also really nice is the abliilty to develop CLR-database objects like functions, etc. directly in the SSDT's project where they naturally belong.
Source control the database
This one takes integrated development to the next level. I did not use much source control for my testing, but I guess that source controling the database schema integrates smoothly with the way you already may do source control. In fact, the database is only a bunch of files now thanks to the declarative approach.
Conclusion
During testing it was especially interesting to see the declarative approach of database development in action, being able to do some refactoring, to check-in the changes to source control and not to take care about the order the scripts must be executed.
I somewhat missed the extended intelisense support I am used to and the non-existing query designer which is often the starting point when building queries of any kind. I also missed my snippets collection and encountered a strange bug duplicating all snippets every time I opened Visual Studio.
Now the question is: will I adopt SSDT’s?
Sorry, it is not my decision alone but the decision of the team I belong to which is not taken yet, so I can’t tell. But I guess that is the best if you play around your-self with SSDT’s, to get your own idea and decide your-self.
Also keep in mind that the SSDT's - according to what I have read - are taken seriously by Microsoft and will most probably expand in terms of features, meaning that even if you decide against using them right now, you may consider to do otherwise when a new version will be released.
Anyway, imperatively and declaratively I wish you good luck!

