Introduction
Developing high-performance applications often requires usage of fast memory allocator storage. Using distributed memory pools may improve
performance of multi-threaded applications on Multi-core PCs [1-3].
Distributed pools attempt to minimize the impact of "false sharing" and thread contention on a Multi-core PC. Instead of accessing
the global memory storage concurrently (which might be a bottleneck), per-thread allocated memory pools can be used along with balancing
private and global pools to leverage fast non-locking algorithms. Such distributed solutions are not simple. Latest versions of Microsoft
Windows provide optimized synchronization primitives. We might want to take advantage of them, designing simple, but still fast pool solutions.
A simplest distributed pool can be an array of pools. Application threads are "distributed" within these pools according to some
distribution rules. The rules may depend on how threads are being created and end - it can be a uniform distribution created
at the application start up, or it can be a "hash-based" distribution. To try these techniques out, we introduce a template class,
Pool_t, representing an element of a pool array. Then, we will implement a class, Array_of_pools_t, representing a distributed pool.
As for a Pool_t object, we use a straightforward implementation leveraging the Windows Interlockedxxx API for single linked lists:
Figure 1. Pool_t - an element of pool array.
template <typename Entry_t, size_t pool_size>
class CACHE_ALIGN Pool_t
{
public:
inline Entry_t* pop(void)
{
List_entry* plist = static_cast<List_entry*>(interlocked_pop_entry_slist(&m_head));
return (plist)? reinterpret_cast<Entry_t*>(reinterpret_cast<char*>(plist) +
data_offset): NULL;
}
inline void push(Entry_t* data)
{
List_entry* plist =
reinterpret_cast<List_entry*>(reinterpret_cast<char*>(data) - data_offset);
interlocked_push_entry_slist(&m_head, plist);
}
Pool_t()
{
::InitializeSListHead(&m_head);
for(size_t i = 0; i < pool_size; i++)
{
interlocked_push_entry_slist(&m_head, &m_pool[i].m_list_entry);
}
}
virtual ~Pool_t()
{
}
private:
typedef SLIST_HEADER CACHE_ALIGN SLIST_HEADER_;
struct CACHE_ALIGN List_entry: public SLIST_ENTRY
{
};
struct CACHE_ALIGN
_Internal_entry_t
{
CACHE_PADDING(1);
List_entry m_list_entry;
Entry_t m_value;
};
static const int data_offset = offsetof(_Internal_entry_t, m_value) -
offsetof(_Internal_entry_t, m_list_entry);
CACHE_PADDING(1);
_Internal_entry_t CACHE_ALIGN m_pool[pool_size];
CACHE_PADDING(2);
SLIST_HEADER_ m_head;
};
This pool implementation is thread safe. It is fast on a Uniprocessor PC. On a Multi-core PC, sharing of the head
of the list m_head incurs a performance penalty. The impact depends on the hardware and may be quite significant. Introducing a distributed pool,
we want different threads to update lists' heads at different memory locations, so that thread contention and "false sharing"
could be less significant. If all threads are created at application start up, a simple solution is to uniformly distribute all the threads within an array of pools:
Figure 2. Simple distributed pool Array_of_pools_t.
template <typename Entry_t, size_t pool_size, size_t number_of_pools>
class CACHE_ALIGN Array_of_pools_t
{
public:
inline Entry_t* pop(size_t index)
{
return m_pools[index].pop();
}
inline void push(Entry_t* data, size_t index)
{
m_pools[index].push(data);
}
inline size_t get_pool_index()
{
volatile static LONG m_counter = 0L;
return (::InterlockedIncrement(&m_counter) - 1) % number_of_pools;
}
Array_of_pools_t()
{
}
private:
Pool_t<Entry_t, pool_size> m_pools[number_of_pools];
};
When a thread is created, first it gets and stores the index = get_pool_index(). This index addresses a pool within the array,
which the thread will be accessing in further pop/push calls. It is important for a thread to use the same index all the time.
Another approach of creating a thread distribution might be using a hash as a pool index, for example:
Figure 4. Using a multiplicative hash to distribute threads within an array of pools.
inline size_t Array_of_pools_t::get_pool_index()
{
return hash(::GetCurrentThreadId());
}
long Array_of_pools_t::hash(long key)
{
const float golden=0.6180339f;
float val = (float)key * golden;
int ival = (int) val;
return((long) ((val - (float)ival) * (float) number_of_pools));
}
The test results of a single Pool_t object and an Array_of_pools_t object are summarized in Figure 5. Eight threads (4 writers and 4 readers)
were concurrently accessing pools on a Quad-core PC. The writer thread popped a buffer from the pool, filled the buffer with random bytes,
and calculated the CRC. Then, the writer pushes the buffer back. Each reader thread pops a buffer from the pool, calculates the CRC,
and compares the latter with the CRC saved by the writer (an exception was supposed to be thrown in case of a CRC error, which would
indicate incorrectness of the pool implementation). The test application is attached to this article.
Figure 5. Comparison performance of single Pool_t and distributed Array_of_pools_t objects when running 8 threads
(4 writers and 4 readers) on a Quad-CPU PC, Intel Q6700, 2.66 GHz, Hyper-Threading disabled, 64-bit Windows Vista Home Premium SP1,
compiled in VC++ 2008 Express (x32- and x64-bit versions). Duration per operation in microseconds.
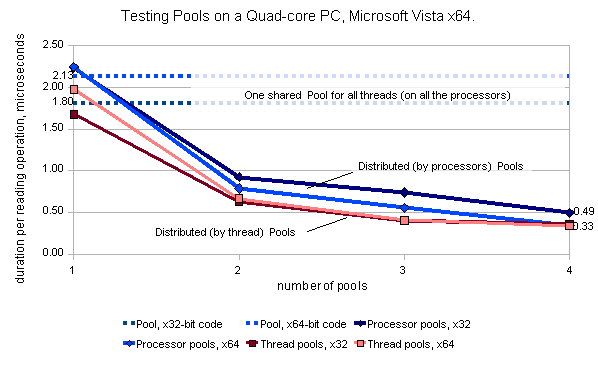
The average duration per read/write in microseconds was calculated based on 50 tests; each of them included 1,000,000 and 4,000,000
iterations for a writer and a reader, respectively. Test results show that the performance of the distributed pool Array_of_pools_t is better
as compared to a single pool, considerably amended (up to ~5-6 times) when the number of pools increases from 1 to 4 on a Quad-core PC.
When the number of threads increases from 8 to 32, performance is improving more considerably, up to 10 times. Two of the factors
affecting the performance of these pools are "false sharing" and thread contention. In order to reduce the impact of thread contention,
we may try a distribution rule "per processor" in place of the distribution rule "per threads". Figure 6 illustrates "per processor"
related modifications of the Pool_t and Array_of_pools_t code:
Figure 6. "Per processor" distributed pool.
template <typename Entry_t, size_t pool_size>
class CACHE_ALIGN Pool_t
{
public:
inline Entry_t* pop(void)
{
List_entry* plist =
static_cast<List_entry*>(interlocked_pop_entry_slist(&m_head));
return (plist)? reinterpret_cast<Entry_t*>(reinterpret_cast<char*>(plist) +
data_offset): NULL;
}
inline void push(Entry_t* data)
{
List_entry* plist =
reinterpret_cast<List_entry*>(reinterpret_cast<char*>(data) - data_offset);
interlocked_push_entry_slist(&m_head, plist);
}
inline static size_t get_pool_id(Entry_t* data)
{
List_entry* plist =
reinterpret_cast<List_entry*>(reinterpret_cast<char*>(data) - data_offset);
return plist->m_pool_id;
}
void set_pool_id(size_t id)
{
for(size_t i = 0; i < pool_size; i++)
{
m_pool[i].m_list_entry.m_pool_id = id;
}
}
Pool_t()
{
::InitializeSListHead(&m_head);
for(size_t i = 0; i < pool_size; i++)
{
m_pool[i].m_list_entry.m_pool_id = 0;
interlocked_push_entry_slist(&m_head, &m_pool[i].m_list_entry);
}
}
virtual ~Pool_t()
{
}
private:
typedef SLIST_HEADER CACHE_ALIGN SLIST_HEADER_;
struct CACHE_ALIGN List_entry: public SLIST_ENTRY
{
size_t m_pool_id;
};
struct CACHE_ALIGN
_Internal_entry_t
{
CACHE_PADDING(1);
List_entry m_list_entry;
Entry_t m_value;
};
static const int data_offset = offsetof(_Internal_entry_t, m_value) -
offsetof(_Internal_entry_t, m_list_entry);
CACHE_PADDING(1);
_Internal_entry_t CACHE_ALIGN m_pool[pool_size];
CACHE_PADDING(2);
SLIST_HEADER_ m_head;
};
template <typename Entry_t, size_t pool_size, size_t number_of_pools>
class CACHE_ALIGN Array_of_pools_t
{
public:
inline Entry_t* pop()
{
return m_pools[::GetCurrentProcessorNumber()% number_of_pools].pop();
}
inline void push(Entry_t* data)
{
m_pools[Pool_t<Entry_t, pool_size>::get_pool_id(data)].push(data);
}
Array_of_pools_t()
{
for(size_t i = 0; i < number_of_pools; i++)
{
m_pools[i].set_pool_id(i);
}
}
private:
Pool_t<Entry_t, pool_size> m_pools[number_of_pools];
};
The idea of the "per processor" distribution is to reduce a number of threads which can access shared members of a pool object
at the same time on a Multi-core PC. This should further minimize thread contention on the pool heads, and thus amend performance.
But the test results in Figure 5 show that there is not much difference in the performance of the pools having "per processor"
and "per thread" distributions. "Per thread" distributed pools are not slower. In order to see the difference in contention
between "per thread" and "per processor" distributions, we may introduce our test version of Interlockedxxx functions for single
linked lists with a "contention" counter. The x32-bit implementation below is simple and perhaps is not too far from what Microsoft
does for x32-bit single linked list API:
Figure 7. SLIST pop/push testing functions with a "contention" counter for x32-bit code.
#if defined(TEST_CONTENTION_COUNT)
#define interlocked_pop_entry_slist test_interlocked_pop_entry_slist32
#define interlocked_push_entry_slist test_interlocked_push_entry_slist32
extern volatile long g_contention_count;
PSLIST_ENTRY WINAPI
test_interlocked_pop_entry_slist32(__inout PSLIST_HEADER ListHead)
{
SLIST_HEADER cmp_header, prev_header;
prev_header.Alignment = ListHead->Alignment;
_read_compiler_barrier_();
long count = -1;
do
{
count++;
if ((prev_header.Next).Next == 0)
{
return NULL;
}
else
{
}
SLIST_HEADER exch = {0};
(exch.Next).Next = (prev_header.Next).Next->Next;
exch.Sequence = prev_header.Sequence + 1;
cmp_header.Alignment = prev_header.Alignment;
prev_header.Alignment = ::_InterlockedCompareExchange64(
reinterpret_cast<__int64*>(&(ListHead->Alignment)),
exch.Alignment,
cmp_header.Alignment
);
__asm{pause}
}
while(prev_header.Alignment != cmp_header.Alignment);
::_InterlockedExchangeAdd(&g_contention_count, count);
return prev_header.Next.Next;
}
PSLIST_ENTRY WINAPI test_interlocked_push_entry_slist32(
__inout PSLIST_HEADER ListHead,
__inout PSLIST_ENTRY ListEntry)
{
PSLIST_ENTRY prev_entry;
PSLIST_ENTRY first_entry;
prev_entry = ListHead->Next.Next;
_read_compiler_barrier_();
long count = -1;
do
{
count++;
first_entry = prev_entry;
ListEntry->Next = prev_entry;
prev_entry = reinterpret_cast<PSLIST_ENTRY>(
::_InterlockedCompareExchange(
reinterpret_cast<long*>(&(ListHead->Next.Next)),
reinterpret_cast<long>(ListEntry),
reinterpret_cast<long>(first_entry)));
__asm{pause}
} while (first_entry != prev_entry);
::_InterlockedExchangeAdd(&g_contention_count, count);
return prev_entry;
}
#else
#define interlocked_pop_entry_slist ::InterlockedPopEntrySList
#define interlocked_push_entry_slist ::InterlockedPushEntrySList
#endif
Test results are summarized in Figure 8. The "contention" counter is measured in % (counter = (g_contention_count / total_number_of_iterations) *100%).
The "contention" counter is higher (~20%) for the pools having the "per thread" distribution as compared with "per processor" distributed pools.
Figure 8. "Contention" counter for a single Pool_t and distributed Array_of_pools_t objects when running 8 threads (4 writers and 4 readers)
on a Quad-CPU PC, Intel Q6700, 2.66 GHz, Hyper-Threading disabled, 64-bit Windows Vista Home Premium SP1, compiled in VC++ 2008 Express (x32-bit application).

Despite the higher values of "contention" counter for the "per thread" distributed pools, they are not slower, but even faster
than pools with the "per processor" distribution, see Figure 5. If a distributed pool is using fast synchronization primitives
(such as the Windows slist's API), the thread contention does not appear to be the only factor affecting performance.
Moreover, the test results of "per thread" distributed pools in Figure 9 shows that the increase in the number of pools greater than
4 does not further improve performance, even if the number of threads increases from 8 to 32.
Figure 9. Performance and "contention" counter for "per thread"-distributed pools when running 8, 16, and 32 threads
on a Quad-CPU PC, Intel Q6700, 2.66 GHz, Hyper-Threading disabled, 64-bit Windows Vista Home Premium SP2, compiled in VC++ 2008 Express (x32-bit application).
If the number of threads equals 32, and the number of pools equals 4, eight threads are concurrently accessing a pool in the array.
In this case, we might expect improving performance along with further increase in the number of pools. But, as it is shown in Figure 9,
both the "contention" counter and performance stays the same on a Quad-core PC when the number of pools reaches 4. Practically, it means
that there is no sense to create a private memory pool per each application thread (as sometimes it is suggested). Depending on the hardware,
creating a distributed pool with a size (number of pools) greater than the number of processors/cores might also be a waste of resources.
Conclusion
- Using a simple array of pools may considerably improve x32/x64 application performance, developed with Microsoft compiler
VC++9.0 for Microsoft Windows Vista, running on a Multi-core PC.
- It might be a disadvantage to create more pools in an array than the number of processors/cores.
References
- Charles Leiserson. "Multicore Storage Allocation", http://www.cilk.com/multicore-blog/bid/7904/Multicore-Storage-Allocation
- Barry Tannenbaum. "Miser - A Dynamically Loadable Memory Allocator for Multi-Threaded Applications", http://www.cilk.com/multicore-blog/?Tag=memory%20management
- "The Hoard Memory Allocator", http://www.hoard.org/
Acknowledgments
Many thanks to Dmitriy V'jukov and Serge Dukhopel. It was their idea to try "per processor" distributed pools on a Multi-core PC,
including methods of thread disstribution within pools. Dmitriy V'jukov also made some valuable comments on the usage and limitation of the code in this article.

