Introduction
Over the years, I have seen several organizations and individuals develop frameworks to build their applications with. There have even been books and magazines articles discussing the benefits and detriments the frameworks provide. Having seen and worked with some of these frameworks, I've been fortunate to learn a few things along the way. Many of the frameworks provide layers and patterns. For this article, I'd like to share the Transportable Layer.
Background
Programming will constantly change as our environments and tools change. Unfortunately, change comes with costs. We've had mainframe applications migrate to client server applications. We've had applications migrate to web based applications. Now we even have applications migrating to our Phones. While this change has happened, so have our coding styles changed. Sometimes the styles have started to mature to patterns. As the patterns change, to make our lives “easier”, we adjust to make our lives “easier”. I'll stop here, cause this can be a long story.
Taking a step Back
Looking back on history, it helps to learn and observe. It helps to ask questions. The big question here is, “With all those changes, what could I have done to make those changes cost less?”
The Answer
Repeatedly, I have arrived at one answer for the question. At one point in time, I wanted to call it the Agnostic Layer. The name Agnostic Layer didn't quite fit. I wanted a layer I could move, a Transportable Layer. For brevity, let's call it the T-Layer. Now, this layer is not new. I just see a lot of Frameworks, books, and articles not even mention it. And that's a shame, because over time, that costs us time and increases risk.
What Is It?
The T-Layer for the most part holds our Business Logic. However, it is written so that it is mostly agnostic of the environment it's running under. It has contracts to the upper layers and contracts to lower layers. The goal again is to be transportable, so it can move from MVC to MVVM to ASP.NET Web Service to WCF Services to ServiceStack to XYZ.
Is this possible?
Mostly. It depends on the decisions made as to what your organization or you decide to put into the T-Layer. There are times when having this layer may not be right. For example, a batch process requiring high performance should definitely do what's necessary to meet it's requirements. For UI development, the layer can definitely be used. Can the layer be used in Web Services, sure. Can it move from a Web Service to a UI without change? Possibly.
Where does this layer sit?
For those of you working with large UI patterns or SOA patterns, here's a few pictures to help visualize where this layer should exist.
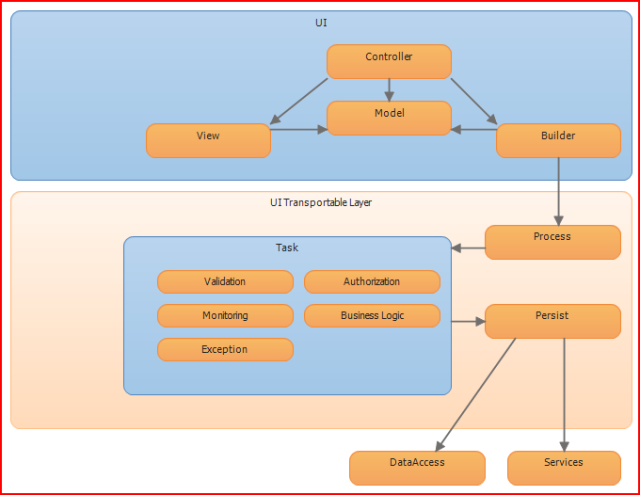
UI Sample Stack

Web Service Stack
As you can see, the T-Layer lies between the UI and the Persistence Layer. The UI should work with the T-Layer's inputs and outputs and map or transpose them to support the UI's needs. The T-Layer has certain demands of the Persistence Layer, but it shouldn't have to worry about how to do Persistence. For SOA, the T-Layer lies between the Communication Layer and the Persistence Layer. The Communication Layer should work with the T-Layer's inputs and outputs and map or transpose them to support the SOA needs. The goal, the T-Layer should be able to move.
What should the T-Layer do?
Tough question and there's many answers. Luckily, I have found a few common tasks for the T-Layer to handle.
In general the methods should work well with many applications' functionality. However, knowing all applications that may need to use a particular functionality may make it impossible to know the right methods to create. Hence, an iterative process may be needed to maintain the T-Layer.
The T-Layer should perform validations. These are the validations that should be applied no matter what higher layers validate and lower layers validate. So if a UI performs a check to make sure an email address is valid, the T-Layer should have the same or better check. If the persistence tool says the email address can only be 255 characters long, the T-Layer should check the email is no more than 255 characters long. Can the UI layer enforce stricter validations? Sure, the T-Layer should handle validations that many users should follow. Usually, validations are for Saving data. Should T-Layer perform validations for querying or request functionality? It most certainly can. It's up to you or your Architects to decide if it should. I think it should. Let's say there's a method to search for potential Customers and there's millions of them. The method looks for Customers by their last name. If there's no last name inputted, there's nothing to search with and something should return a validation saying an input is needed. I would think the T-Layer could return a message saying a last name is needed. Having validation business rules residing in an established location definitely makes life easier in the long run. Being able to move the code and logic around supporting those rules would make life even easier in the long run.
The T-Layer could support processing. There are simple processes and complex processes. The T-Layer is a place the coordination and possibly the execution of processing may occur. Many times processing involves logic and the T-Layer should be able to handle a lot of logic. At times, there are other components and code built to handle complex processes. The T-Layer in complex cases can coordinate with the components and code built to handle those complex processes. Why should the T-Layer interact with the other complex components instead of the applications' themselves? It's an architectural decision. I've found there are pre-processing validations and post-processing cleaning that often happens when working with components. The T-Layer could support the pre-processing and post-processing. Plus having the T-Layer work with the component provides a level of abstraction that may help if the component is changed or replaced. Having a T-Layer that can move the coordination from one location to another in our UI or SOA code would make things cost less in the long run.
Should the T-Layer perform authorization checks?
Some will say yes, others will say no. I'll say yes cause authorization is business logic. Having to rely on a front end application to properly enforce authorization is a risk. An application should still try to enforce authorization into the business and processing logic for the application, not really the T-Layer. Some will say the application should decide if a user has the right to perform a task managed by the T-Layer. The code using the T-Layer or application using the T-Layer that's handling authorization approach really hasn't a need for the T-Layer to perform any authorization. Others will say the T-Layer should handle authorization no matter where the layer is. In some cases, the T-Layer using code and the T-Layer may want to check authentication. A big concern with authorization checks is performance. In some environments, authorization can be slow for code to perform. So having the application and the T-Layer perform authorization checks may not be a good idea. Whatever choice is taken, try to be consistent and make sure to build the environment to support it.
Into the Bits
We've touched on some of the things the T-Layer can do. To make it work well, there may be a few thoughts to keep in mind to keep things consistent. The T-Layer often runs under a context. The context may be the application, the customer, the user, the language, the currency, etc. It shouldn't take long to figure out the context the T-Layer runs under. To make the T-Layer consistent, the context needs to exist in a place that can be transported. At one point, I've seen the context placed on the Principal. The principal is great cause it exists on the thread. But lately, I'm favoring the context be passed in as an object to each method. Passing the context this way is simple for most developers. If the context needs to vary a little, it may contain a Dictionary to capture extra contextual values or use Interface inheritance. Be wary to make the context object one that can be passed between layers and across your SOA implementations. The context can become “heavy”, so be wary of how it's implemented.
Since the T-Layer performs validations, how can “broken” validations return to the calling layer or even the highest layer, like the UI? I have seen the usage of custom exceptions to support this, often called
BusinessLogicException. Luckily, System.Exception has the
Data collection to return values to help pass parameters to higher layers. Using an Exception works fine, but it can be slow cause of how .Net needs to build up Exceptions. So, if you're after performance, using an Exception to return “broken” validations may not work so well. Another approach would be to place “broken” validations on the return of all T-Layer methods. Placing the “broken” validations as the return makes coding fairly easy to check if validations were broken.
if (tComponent.CallSomeMethod(context,
somevalue).Count == 0)
{
Now what to do if the method needs to return results? If our example call of
tComponent.CallSomeMethod returned a List, how would we get to it? We now have our big issue,
“How to work with results and broken validations?” Plus, we want to make the solution transportable and simple. What is a good template for our method signatures?
I have seen different approaches to handle this. One approach is to put the “broken” validations as the return object and have results as an output parameter.
The second approach is to put the result as the return object and the “broken” validations as an output parameter. Third approach is to use a composite result
object that contains both the “broken” validations and the results. Fourth approach is for the method to return an object and use casting to change the object
into something to work with. There may also be AOP and Event ways to handle passing validations back, but those don't sound simple and transportable.
Bottom line, no approach really sounds great. When working with “broken” validations, make sure you or your Architect establish the approach and stick
with it. I would keep in mind the environment the methods are returning data to, like WCF and Rest clients. Remember, to make it transportable and simple.
Validations appeared tough, how about exceptions? There are all kinds of Exceptions. Should our T-Layer have tons of different kinds of Exceptions? It could, but it can become a little messy. I've worked with a custom Exception that had an enum property to indicate what kind of Exception it represented. If the custom Exception needed to pass any values, they could be placed in Data or another custom Exception to be made to handle the hopefully, one-off, scenarios. Again, it's a choice to make. When you get to 50 or so different custom Exceptions that look pretty much the same, you might start to think different about custom Exceptions.
Logging the Exception is also a point of discussion. If the T-Layer will go across platforms, logging involves needing a way to persist the Exception. There are libraries, like log4net, nLog, CommonLogger, to help with persisting Exceptions. If you or your architects decide on a logging strategy for Exceptions, the T-Layer could provide the hooks to persist the Exceptions. Another thought is the code calling the T-Layer should manage the T-Layer Exceptions. This approach also works; just keep it coordinated. How about Exceptions passed up to the T-Layer? The T-Layer could wrap them in another T-Layer custom Exception and pass that up or persist it like the other custom Exceptions. Again, it's something to discuss.
Exceptions help us to manage when things go wrong or unexpected, how about when we want to know how well things are working? Tracking how an application is performing can be essential for identifying bottlenecks, functionality usage, user usage, etc. The T-Layer could help with monitoring. The T-Layer could include monitoring points to turn on and off as needed and work with a library to persist data collected. In some ways, monitoring is like Exceptions when it comes to the available libraries and persisting. Depending on the environment, monitoring may not be needed. At least this is something to think about.
Most applications need to think about authorization. The T-Layer can definitely help here. If the context is set, the T-Layer can perform checks to see if the user can perform the method and use it to determine appropriate logic to take. Hold a second, got a couple questions on that, “how can that be quick? Should every T-Layer method perform a check?” Now, we're really starting to get into the bits. The T-Layer is actually made of several layers. The initial layers should perform the authorization check. Now, if your an organization that is based on roles, your headed for trouble when working on larger applications. If your an organization that does authorization based on function, task, permissions, entitlements, or whatever functional granular nomenclature you use, then your headed down the right track. I like to use 'permission'. T-Layer methods could be set up to check for one or multiple permissions. Now, as we have put a context as part of our method signatures, our context usually has enough data points for the T-Layer method to determine if the method should execute. Can the context contain the permissions? Sure. Having the user's permissions as part of the context saves a lot of time for the T-Layer method, because the T-Layer method doesn't have to retrieve the permissions. Sometimes, like in an SOA environment, passing the permission with the context to a Web Service may not be a good idea. So, in some cases the T-Layer needs to call elsewhere to retrieve permissions. The permission environment should be well tuned. I would definitely recommend looking into a distributed memory based solution (Would somebody please build a decent Distributed MMRDBMS? Please? I said 'please'). If building this from scratch, make sure you establish a Session policy. A Session starts when a user begins working with an application or enters the application environment. An example policy is that the user's authorizations don't change during a Session with an application. Another example policy is that the user's authorizations are dynamic, as in may change at any moment. These decisions may affect what you put on the context and where the authorizations should be collected and checked.
The T-Layer sure has a lot to do. So to separate things out, the T-Layer should have many layers. The first layer I've called a Process layer. It's very similar to a Controller. I could have called it a Function layer or Orchestration layer. In any case, the methods this layer exposes to calling code should align with the calls applications using it need. The layer needs to orchestrate handling authorization checks. It could call another method to perform the check. Then the Process Layer needs to handle validations. Again, the Process layer could call a validation function. The Process Layer could then perform the Function or action by calling a set of methods focused on that. The Process Layer would handle any pre-processing and post-processing. Pre-processing being things like adjust data or setting up data, and yes that could be another function. Post-processing would be similar to pre-processing. Post-processing might be mapping data or even handling exceptions. It's up to you or the architects to decide what this layer should do.
One thing I have seen happen with Agile coding patterns is spaghetti code. Separation of Concerns often leads to spaghetti code, which is a real PITA. Nothing like calling 15+ functions to dot an 'I'. Here's a thought, separate out by what is best to create an automated test for. For example, each method the Process Layer uses, could be broken out into unit tests. Now, if the Process Layer needs to return a simple string, or calculate 1 + 1 = 2, it might not make sense to have the Process Layer call another function to calculate 1 + 1 = 2. When it becomes complicated or many lines, then it might be a good idea to break it out into another function calls. I don't mind eating good spaghetti. I do mind reading spaghetti. Some folks will say, you need to separate things out to make them testable at the Unit Level. There's a cost to all those Unit Tests, especially when good Integration testing can do the same and perform fast enough if things are set up right. Unit Tests can be great when trying to address a specific issue. Just remember, Unit Tests also come with a maintenance cost. Right good tests at the right times. Build the code to support those tests. Less code, less spaghetti.
Should the T-Layer have a layer to abstract out the persistence layer? Tough call. Sometimes yes and sometimes no. For example, if the call is to an external web service, you may want to encapsulate the Web Service with your own interface and mapping code. If the external web service changed, then hopefully only the one layer would have to adjust. Now, let's say you have a mature application and things never change. Making a layer to abstract away the persistence layer may be considered overkill by some. Again folks, this is a judgment call. Now having contracts in place, will definitely help to create the layer. And having the contracts in place will help with testing. So at least reach a point where the T-Layer knows the kind of call it needs to work with persisting data.
The Good, The Bad
Creating a T-Layer will offer several key benefits:
Reduced risk from change, heck we're trying to make it transportable.
Centralization or a designated location to capture transportable business rules.
Consistency in development, once these discussed decisions are made they can be re-used over and over.
Creating a T-Layer does have its detriments:
Initial Costs, it takes time to build these sometimes redundant items.
Performance, the code may need to do some redundant work, like object mapping or authorization.
Risk of immoveable code, there may still be changes in technology, environments, etc. that the transportable code can't move to.
While the essential business rules are nicely located in one place, the code may not transport. If this were to happen, most likely other coding styles would not have transported either.
So there's a few Good's and Bad's.
What's in the sample code?
The sample code provides a simple scenario for handling Address in the T-Layer. The same T-Layer is used in a WCF Service and used in a ASP.NET MVC 3 with Razor. It's more proof-of-concept code to demonstrate some gotchas, ways to handle Model to T-Layer mapping, handling exceptions, handling validations, context, and maybe a few other points.
Here's a sample of a WCF save implementation:
public DataContract.Address Save(DataContract.Context context, bool overrideWarning
, DataContract.Address original)
{
DataContract.Address result = null;
try
{
Dto.Address originalDto = ConversionHelper.ToDto(original);
TLCommon.Method.Context contextCommon = ConversionHelper.ToDto(context);
PersistContract.IAddress addressDal = new AddressDal();
PersistContract.IMonitoring monitoringDal = new Persist.Common.MonitoringDal();
TLProcessContract.IAddressTL addressTL = new TLProcess.AddressTL();
addressTL.AddressPersist = addressDal;
addressTL.MonitoringPersist = monitoringDal;
List<TLCommon.Method.Validation> commonValidations = new List<TLCommon.Method.Validation>();
Dto.Address processResult = addressTL.Save(contextCommon, commonValidations, originalDto);
result = ConversionHelper.ToContract(processResult, commonValidations);
return result;
}
catch (Exception ex)
{
throw ex;
}
}
The sample code shows the use of passing in a Context and an
Address. Both Context and Address are contracts. The method also has the input of
overrideWarning.
The overrideWarning value is a concept where validations may also return warnings and not perform an action. Sometimes the action just has to happen
and this provides a means of forcing the actions. For now, overrideWarning is not used. Walking through the code quickly The
Context and the Address
are converted to classes that can be used by the T-Layer. Following the conversion, there's some code to set up the interfaces. Normally
IOC library
would take of this, but this isn't about demonstrating an IOC. At this point, we're finally ready to call the T-Layer process. For passing validations,
the approach shown here has the validations and addresses passed around as separate objects. A piece to notice is the original object is preserved
and a process result object is created. Sometimes we need to use the original in another step. Sometimes the original may have values we don't want
to pass back. The final step converts the process result object and any validations to a return contract. In this case the return contract has both the result and validations on it.
Enjoy these thoughts and decisions. Now let's move!!!
History

